之前遇到了这样一个问题:
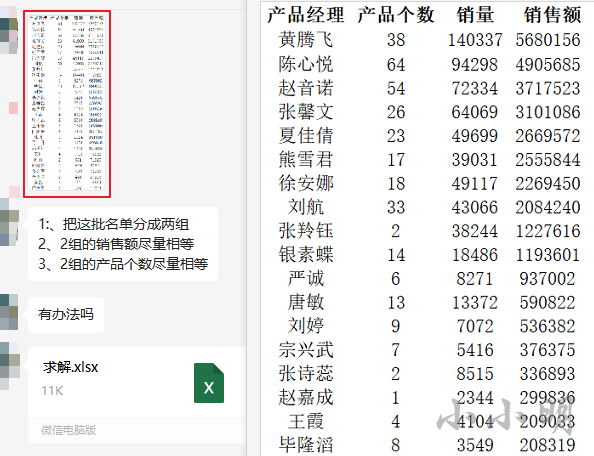
总结就是,将一批名单分成两组使得产品个数和销售额尽可能相等。
单纯的平分销售额或者平分产品个数会非常简单,但是要求两个维度同时进行就比较复杂,观察可以看到销售额的数字远远高于产品个数,我们可以先控制要求产品个数相等的情况下,找出销售额相差最小的方案,如果销售额相差较大,可以降低产品个数相差要求再看。慢慢提高相差范围,最终凭感性找出一个比较平衡的值。
首先读取数据(复制下面的表格后再执行下面的代码即可得到相同的数据):
import pandas as pd
import numpy as np
df = pd.read_clipboard()
df
| 产品经理 | 产品个数 | 销量 | 销售额 | |
|---|---|---|---|---|
| 0 | 黄腾飞 | 38 | 140337 | 5680156.5 |
| 1 | 陈心悦 | 64 | 94298 | 4905685.2 |
| 2 | 赵音诺 | 54 | 72334 | 3717523.2 |
| 3 | 张馨文 | 26 | 64069 | 3101085.6 |
| 4 | 夏佳倩 | 23 | 49699 | 2669572.1 |
| 5 | 熊雪君 | 17 | 39031 | 2555844.4 |
| 6 | 徐安娜 | 18 | 49117 | 2269450.4 |
| 7 | 刘航 | 33 | 43066 | 2084240.0 |
| 8 | 张羚钰 | 2 | 38244 | 1227615.6 |
| 9 | 银素蝶 | 14 | 18486 | 1193600.5 |
| 10 | 严诚 | 6 | 8271 | 937001.5 |
| 11 | 唐敏 | 13 | 13372 | 590821.6 |
| 12 | 刘婷 | 9 | 7072 | 536381.8 |
| 13 | 宗兴武 | 7 | 5416 | 376375.0 |
| 14 | 张诗蕊 | 2 | 8515 | 336892.5 |
| 15 | 赵嘉成 | 1 | 2344 | 299836.0 |
| 16 | 王霞 | 4 | 4104 | 209033.0 |
| 17 | 毕隆滔 | 8 | 3549 | 208318.8 |
| 18 | 王彬彬 | 5 | 3599 | 207989.9 |
| 19 | 但伊静 | 4 | 3476 | 153416.8 |
| 20 | 张丹 | 6 | 2614 | 131388.8 |
| 21 | 马一丹 | 6 | 1450 | 128639.6 |
| 22 | 郭哲达 | 7 | 2590 | 124674.6 |
| 23 | 黄怡 | 4 | 2293 | 75829.7 |
| 24 | 何虹 | 2 | 751 | 71925.1 |
| 25 | 仲倩影 | 3 | 949 | 36375.1 |
| 26 | 秦文君 | 1 | 420 | 20958.0 |
| 27 | 关贞卓 | 1 | 478 | 20218.2 |
| 28 | 黄蕊 | 1 | 86 | 19994.0 |
| 29 | 许国露 | 1 | 357 | 17374.3 |
pulp求解
下面我们使用pulp进行整数规划进行求解,首先尝试设置约束要求划分的两个数据集产品个数相等,其次要求两个数据集销售额的差值尽可能的小。
可惜pulp默认的cbc求解器并不支持绝对值约束,我的方案是先限制a大于b之后,再求a-b的最小值。
from pulp import *
import numpy as np
prob = LpProblem('目标函数和约束', sense=LpMinimize)
# 第一份数据集被选中的位置
x = np.array([LpVariable(f"x{
i}", cat=LpBinary) for i in range(df.shape[0])])
# 剩余被选中的位置
y = 1-x
# 首先尝试产品个数相等
prob += (x*df.产品个数).sum() == (y*df.产品个数).sum()
prob += (x*df.销售额).sum() >= (y*df.销售额).sum()
# 目标
prob += (x*df.销售额).sum() - (y*df.销售额).sum()
status = prob.solve()
print("求解状态:", LpStatus[prob.status])
r1 = df[[bool(value(i)) for i in x]]
r2 = df[[bool(value(i)) for i in y]]
print(r1.sum(numeric_only=True))
print(r2.sum(numeric_only=True))
print(r1.sum(numeric_only=True)-r2.sum(numeric_only=True))
display(r1)
display(r2)
executed in 10.3s, finished
产品个数 190.0
销量 326201.0
销售额 16954109.8
dtype: float64
产品个数 190.0
销量 354186.0
销售额 16954108.0
dtype: float64
产品个数 0.0
销量 -27985.0
销售额 1.8
dtype: float64
可以看到,销售额差值仅1.8,可以说差距已经非常小了,很可能已经就是最佳答案。我们再求解一下产品个数差距在2范围内时,销售额最低差值是多少:
from pulp import *
import numpy as np
prob = LpProblem('目标函数和约束', sense=LpMinimize)
# 第一份数据集被选中的位置
x = np.array([LpVariable(f"x{
i}", cat=LpBinary) for i in range(df.shape[0])])
# 剩余被选中的位置
y = 1-x
# 产品个数差距小于3
prob += (x*df.产品个数).sum()-3 <= (y*df.产品个数).sum()
prob += (x*df.产品个数).sum()+3 >= (y*df.产品个数).sum()
# 两者的销售额的差值的绝对值最小
prob += (x*df.销售额).sum() >= (y*df.销售额).sum()
prob += (x*df.销售额).sum() - (y*df.销售额).sum()
status = prob.solve()
print("求解状态:", LpStatus[prob.status])
r1 = df[[bool(value(i)) for i in x]]
r2 = df[[bool(value(i)) for i in y]]
print(r1.sum(numeric_only=True))
print(r2.sum(numeric_only=True))
print(r1.sum(numeric_only=True)-r2.sum(numeric_only=True))
display(r1)
display(r2)
executed in 1.21s, finished
求解状态: Optimal
产品个数 189.0
销量 354048.0
销售额 16954110.2
dtype: float64
产品个数 191.0
销量 326339.0
销售额 16954107.6
dtype: float64
产品个数 -2.0
销量 27709.0
销售额 2.6
dtype: float64
相反计算出来的结果比之前的差距更大了,说明产品个数相同时就可以找到最佳答案。
MIP 求解器
ortools的SCIP求解器可以使用相同的思路求解这个问题:
from ortools.linear_solver import pywraplp
# 创建一个mip求解器
solver = pywraplp.Solver.CreateSolver('SCIP')
x = np.array([solver.BoolVar(f'x_{
i}') for i in range(df.shape[0])])
y = 1-x
solver.Add((x*df.产品个数).sum() == (y*df.产品个数).sum())
solver.Add((y*df.销售额).sum() >= (x*df.销售额).sum())
solver.Minimize((y*df.销售额).sum() - (x*df.销售额).sum())
# 求解结果
status = solver.Solve()
status = {
solver.OPTIMAL: "最优解", solver.FEASIBLE: "可行解"}.get(status)
print(status)
r1 = df[[bool(i.solution_value()) for i in x]]
r2 = df[[bool(i.solution_value()) for i in y]]
print(r1.sum(numeric_only=True))
print(r2.sum(numeric_only=True))
print(r1.sum(numeric_only=True)-r2.sum(numeric_only=True))
display(r1)
display(r2)
executed in 6.16s, finished
最优解
产品个数 190.0
销量 354186.0
销售额 16954108.0
dtype: float64
产品个数 190.0
销量 326201.0
销售额 16954109.8
dtype: float64
产品个数 0.0
销量 27985.0
销售额 -1.8
dtype: float64
cp_model求解
ortools的cp_model可以使用相同的思路求解这个问题,但是仅支持整数:
from ortools.sat.python import cp_model
model = cp_model.CpModel()
x = np.array([model.NewBoolVar(f'x_{
i}') for i in range(df.shape[0])])
y = 1-x
model.Add((x*df.产品个数).sum() == (y*df.产品个数).sum())
v = (df.销售额*10).astype("int")
model.Add((x*v).sum() >= (y*v).sum())
model.Minimize((x*v).sum() - (y*v).sum())
# 求解结果
solver = cp_model.CpSolver()
status = solver.Solve(model)
status = {
cp_model.OPTIMAL: "最优解", cp_model.FEASIBLE: "可行解"}.get(status)
print(status)
r1 = df[[bool(solver.Value(i)) for i in x]]
r2 = df[[bool(solver.Value(i)) for i in y]]
print(r1.sum(numeric_only=True))
print(r2.sum(numeric_only=True))
print(r1.sum(numeric_only=True)-r2.sum(numeric_only=True))
display(r1)
display(r2)
executed in 1.66s, finished
最优解
产品个数 190.0
销量 326201.0
销售额 16954109.8
dtype: float64
产品个数 190.0
销量 354186.0
销售额 16954108.0
dtype: float64
产品个数 0.0
销量 -27985.0
销售额 1.8
dtype: float64
这个求解器的优点是速度极快,2秒之内已经计算出结果。
回顾
最终划分结果为:
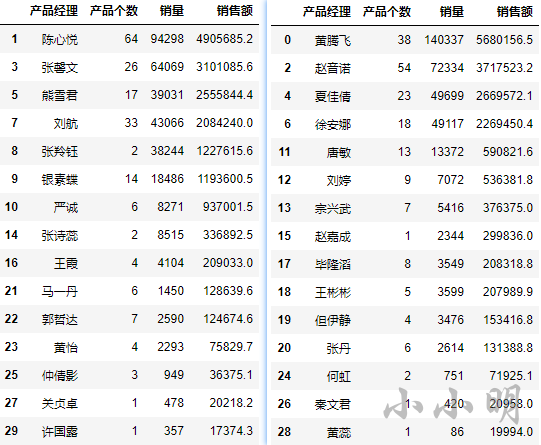
ortools的cp_model求解器虽然只支持整数操作,但速度最快。
参考: