文章目录
前言
你将学习到:HashMap和HashTable的区别
1.继承的父类不同
2.同步性不同(线程安全不同)
3.对null key和null value的支持不同
4.初始化数组的时机不同
5.扩容方式不同
6.计算hash值的方法不同
7.计算下标的方法不同
1.继承的父类不同

进入HashMap和HashTable的原码,首先可以看到的是,两者继承的父类不同。HashMap继承了AbstractMap,HashTable继承了Dictionary。不过他们两都实现了Map、Cloneable、Serializable接口。
2.同步性不同(线程安全不同)

继续纵观两者的源码发现,HashTable的绝大部分方法前都加了synchronized(同步函数),而HashMap则没有。由此得出,HashTable是线程安全的,HashMap不是线程安全的,同时也能得出HashTable的效率不如HashMap。(加了synchronized,所有的线程进来之后都要排队执行,线程越安全,效率越低)
拓展:多线程环境下,HashMap线程不安全,而HashTable同步的效率又比较低,所以我们通常使用concurrentHashMap,它不会把所有的方法锁住,而是采用分段锁的方式进行锁定,在提高线程安全的同时又提高了效率。
3.对null key和null value的支持不同
对于是否允许空键空值,最能体现的就是put方法
先来看一下HashTable的put方法:

可以看出,若value为空,直接抛出空指针异常。若key为空,则null.hashCode()也会抛空指针异常,因此得出HashTable中key和value是不能为空的
再来看一下HashMap的put方法:


可以看出,在put方法中,并没有对空key和空value做抛异常处理(疯狂暗示,HashMap中key和velue 是可以为空的)。接着进入hash方法(计算key的哈希值),可以看出,若key为空,则它的哈希值为0,否则进行计算。
拓展:key的hash与它的低16位做异或运算,(h = key.hashCode()) ^ (h >>> 16),为什么是这样计算的呢?是为了高位、低位同时参与运算,让哈希的散列算法更加的均匀。
通过对比得出:HashTable中的key和value都不允许为空。HashMap中的key和value可以为空,并且key只能有一个null(多了会覆盖),value则可以有无数个null
4.初始化数组的时机不同
先看HashTable:
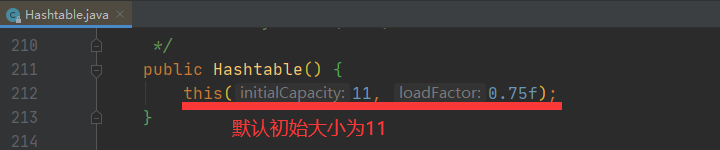

可以看出,HashTable中数组的初始化是在构造函数中进行的,初始容量大小为11
再来看HashMap:



可以看出,HashMap中数组的初始化是在第一次调用put的时候,resize(重新扩容)的方法中进行的
综上:HashTable中数组的初始化是在构造函数中,创建时如果给定了容量初始值,那么HashTable会直接使用你给定的大小,而HashMap中数组的初始化是在第一次调用put方法的时候。
5.扩容方式不同
HashTable的扩容:

HashMap的扩容:

综上:HashTable的扩容方式为2n+1,HashMap的扩容方式为2n
6.计算hash值的方法不同
HashTable:

HashMap:

拓展:为什么是右移16位?因为int类型占4个字节,总的就是32个字节,高低位对半分的话就是高位左边16位,低位右边16位,因此高位转低位的时候要右移16位
综上:HashTable计算hash值的方式为直接调动HashCode()方法计算hash值,而HashMap则是key的hash与它的低16位做异或运算,(h = key.hashCode()) ^ (h >>> 16)
7.计算下标的方法不同
HashTable:

(hash & 0x7FFFFFFF)是为了将hash的最高位变为0,变为正数
HashMap:

综上:
HashTable计算下标的方式为:hash值对数组长度取余运算
HashMap计算下标的方式为:容量-1再和hash值做与运算
总结
1.继承的父类不同
HashMap继承了AbstractMap,HashTable继承了Dictionary
2.同步性不同(线程安全不同)
HashTable是线程安全的,HashMap不是线程安全的
3.对null key和null value的支持不同
HashTable中的key和value都不允许为空。HashMap中的key和value可以为空,并且key只能有一个null(多了会覆盖),value则可以有无数个null
4.初始化数组的时机不同
HashTable中数组的初始化是在构造函数中,默认值为11,创建时如果给定了容量初始值,那么HashTable会直接使用你给定的大小,而HashMap中数组的初始化是在第一次调用put方法的时候,默认值为16
5.扩容方式不同
HashTable的扩容方式为2n+1,HashMap的扩容方式为2n
6.计算hash值的方法不同
HashTable计算hash值的方式为直接调动HashCode()方法计算hash值,而HashMap则是key的hash与它的低16位做异或运算,(h = key.hashCode()) ^ (h >>> 16)
7.计算下标的方法不同
HashTable计算下标的方式为:hash值对数组长度取余运算
HashMap计算下标的方式为:容量-1再和hash值做与运算
当你真心想要做一件事的时候,整个宇宙都会帮助你,加油!