背景:
需要通过SparkStreaming实时统计word count
输入源通过netcat来
步骤:
1、安装netcat,运行如下命令
yum install nmap-ncat.x86_642、运行命令
nc -lk 8888这样就会在8888端口监听
3、编写程序
package scalapackage.testspark
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by Germmy on 2018/6/2.
*/
object SparkStreamingWC {
def main(args: Array[String]) {
val sc=new SparkConf().setAppName("SparkStreamingWC").setMaster("local[2]")
val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))
ssc.checkpoint("hdfs://node01:9000/ck-20180602")//针对SparkStreaming设置的checkpoint,在读文件后设置ck也可以
val textStream: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.92.142",8888)
val dStream: DStream[(String, Int)] = textStream.flatMap(_.split(" ")).map((_,1))//2次map?
val key: DStream[(String, Int)] = dStream.updateStateByKey(myfunc,new HashPartitioner(ssc.sparkContext.defaultMinPartitions),false)
key.print(10)
ssc.start()
ssc.awaitTermination()
}
val myfunc=(it:Iterator[(String,Seq[Int],Option[Int])])=>{
it.map(x=>(x._1,x._2.sum+x._3.getOrElse(0)))
}
}
注意:
1、此处的数据源是netcat,因此写成socketTextStream(nc所在ip,8888)
2、此处累加不再是reduceByKey,而是updateStateBykey,需要传入一个自定义函数,这是难点。
自定义函数=后面是入参,带泛型的,方法体写在=>后面,返回类型需要的是一个[String,Int]的元组
3、sparkstreaming需要提前搞好Pom
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.1</version>
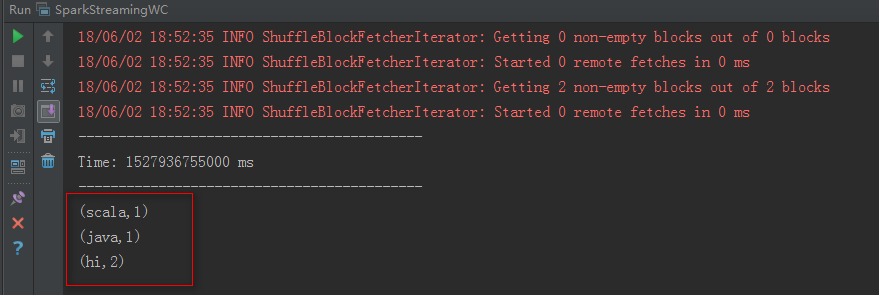
</dependency>运行结果如下
参考
2、