Github: https://github.com/huange7/workcount
个人项目
1. 题目描述
Word Count
1. 实现一个简单而完整的软件工具(源程序特征统计程序)。
2. 进行单元测试、回归测试、效能测试,在实现上述程序的过程中使用相关的工具。
3. 进行个人软件过程(PSP)的实践,逐步记录自己在每个软件工程环节花费的时间。
1.1 项目要求
wc.exe 是一个常见的工具,它能统计文本文件的字符数、单词数和行数。这个项目要求写一个命令行程序,模仿已有wc.exe 的功能,并加以扩充,给出某程序设计语言源文件的字符数、单词数和行数。
实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。
具体功能要求:
程序处理用户需求的模式为:
wc.exe [parameter] [file_name]
基本功能列表:
wc.exe -c file.c //返回文件 file.c 的字符数
wc.exe -w file.c //返回文件 file.c 的词的数目
wc.exe -l file.c //返回文件 file.c 的行数
扩展功能:
-s 递归处理目录下符合条件的文件。
-a 返回更复杂的数据(代码行 / 空行 / 注释行)。
空行:本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如“{”。
代码行:本行包括多于一个字符的代码。
注释行:本行不是代码行,并且本行包括注释。一个有趣的例子是有些程序员会在单字符后面加注释:
} //注释
在这种情况下,这一行属于注释行。
[file_name]: 文件或目录名,可以处理一般通配符。
高级功能:
-x 参数。这个参数单独使用。如果命令行有这个参数,则程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、行数等全部统计信息。
需求举例:
wc.exe -s -a *.c
返回当前目录及子目录中所有*.c 文件的代码行数、空行数、注释行数。
解题思路
首先想要对一个文件进行统计行数等等,那么肯定就涉及到对文件进行IO操作了。
1. 对字符的处理
对字符的处理则是直接获取当前行数的长度以及加上默认的换行符两个字符
2. 对行数的处理
对行数的处理是直接累计每次获取的行数
3. 对单词的处理
利用正则表达式对每行中的特殊符号进行替换,换成空格。之后再根据空格进行切割。就可以获取到当前行有多少个单词。
4. 特殊行的处理
首先对注释行进行处理,利用正则表达式,对每一种注释进行匹配,当检测到不是注释行时,则进行空行的匹配,如果空行再次匹配失败,则说明是代码行。
5. 图形界面
利用javafx进行界面的编写,再进行一个总体调用程序进行调用。
6. 文件递归
每次读取单个文件夹下的所有文件(包括文件夹),之后对文件数组进行逐个遍历读取。当读取到文件夹时继续执行该函数。
遇到的困难及解决方法
- 对代码行与注释行的区分已经归类
- 尝试进行多种正则表达式的匹配
- 仍存在特殊情况无法解决
- 对正则表达式的运用更加熟悉
- 对命令行和图形界面的整合
设计实现过程
项目分包设计:
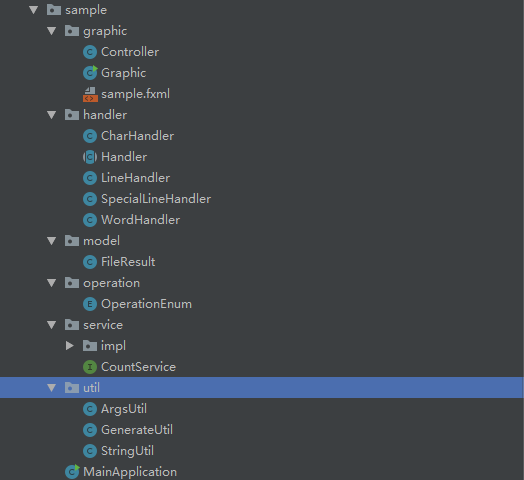
共分为6个包,分别为graphic,handler,model,operation,service,util包。
graphic包用于图形显示界面的逻辑处理
handler包用于每一行的情况处理,包括字符统计,行数统计,单词统计等等
model包用于图形界面时表格的展示
operation包包含一个枚举类,枚举了用户可能的参数
service包用于处于统计业务逻辑
util是工具包,包括字符串处理,参数处理,以及处理链的生成。
流程图
主函数流程图:
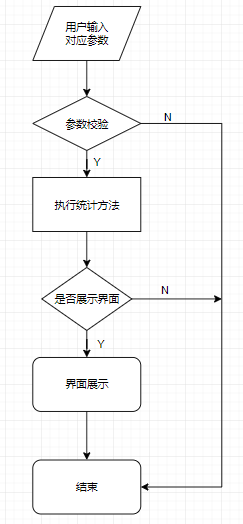
关键代码or设计说明
处理采用的是责任链模式,每个处理类构成一条处理链条,分别对对应的行进行自己相应的处理并统计。
处理链部分代码
抽象类处理代码:
/**
* 后继对象
*/
private Handler successor;
/**
* 计算数
*/
private Integer count = 0;
/**
* 处理对应的责任链
* @param line 处理的行
*/
public abstract void handleRequest(String line);
/**
* 打印统计结果
*/
public abstract void printCount();
/**
* 清空数据
*/
public void clear(){
setCount(0);
}
/**
* 取值方法
*/
public Handler getSuccessor() {
return successor;
}
/**
* 赋值方法,设置后继的责任对象
*/
public void setSuccessor(Handler successor) {
this.successor = successor;
}
/**
* 获取数量
*/
public Integer getCount() {
return count;
}
/**
* 赋值方法,设置数量
*/
public void setCount(Integer count) {
this.count = count;
}
字符处理代码:
public void handleRequest(String line) {
setCount(getCount() + line.length() + System.lineSeparator().length());
if (getSuccessor() != null){
getSuccessor().handleRequest(line);
}
}
行数处理代码:
public void handleRequest(String line) {
setCount(getCount() + 1);
if (getSuccessor() != null){
getSuccessor().handleRequest(line);
}
}
单词处理代码:
public void handleRequest(String line) {
// 将c文件中的符号转换为
String pattern = "[,;{}()#\"':<>.\\s=%+\\-*/0-9]";
setCount(getCount() + StringUtil.split(line.replaceAll(pattern, " "), " ").length);
if (getSuccessor() != null){
getSuccessor().handleRequest(line);
}
}
特殊行处理代码:
public void handleRequest(String line) {
// 设置空行正则表达式
String emptyPattern = "[\\s{}]*";
// /*注释开始标记
String startAnnotationA = "^[\\s]*/\\*.*";
// /*注释行文中开始标记
String startAnnotationB = ".*[;})][\\s]*/\\*.*";
// }注释行
String annotationSpecial = "^\\s*}\\s*/[*/].*";
// //注释开始标记
String startAnnotationC = "^[\\s]*//.*";
// //注释行文中开始标记
String startAnnotationD = ".*[;})][\\s]*//.*";
// */注释结束标记
String endAnnotation = ".*\\*/[\\s]*$";
if (isAnnotation && line.matches(endAnnotation)){
// 匹配到已经是注释模式且已经找到结束位置
isAnnotation = false;
annotationLine++;
} else if (isAnnotation){
annotationLine++;
} else if (line.matches(startAnnotationA) || line.matches(startAnnotationB)){
if (!line.matches(endAnnotation)){
isAnnotation = true;
}
annotationLine++;
} else if (line.matches(startAnnotationC) || line.matches(startAnnotationD)){
annotationLine++;
} else if (line.matches(emptyPattern)){
emptyLine++;
} else {
codeLine++;
}
if (line.matches(startAnnotationB) || line.matches(startAnnotationD)){
if (!line.matches(annotationSpecial)){
codeLine++;
}
}
setCount(getCount() + 1);
if (getSuccessor() != null){
getSuccessor().handleRequest(line);
}
}
主函数处理类:
先根据参数构造对应的处理链,接着获取文件夹的名称,对文件夹里面的文件进行逐个遍历。
public void doHandler(String fileDir, String[] args) throws IOException {
// 获取处理链
Handler head = GenerateUtil.generateChain(args);
// 获取文件名称
fileName = ArgsUtil.getFileName(args);
// 将文件名进行转换
fileName = fileName.replaceAll("[*?]", ".*");
// 获取文件夹
File file = new File(fileDir);
if (!file.exists()){
System.out.println("文件或者文件夹不存在!");
return;
}
// 获取文件夹下的文件
File[] files = file.listFiles();
if (files != null) {
for (File f :
files) {
readFile(head, f);
}
}
}
根据传入的文件是文件夹还是文件进行处理,当是文件时则进行读取,如果是文件夹则进行遍历。
结果将根据是否显示为图形函数而进行显示。public void readFile(Handler head, File file) throws IOException {
// 处理文件类型
if (!file.isDirectory()){
if (!file.getName().matches(fileName)){
return;
}
FileReader fileReader = null;
try {
fileReader = new FileReader(file);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
BufferedReader reader = new BufferedReader(fileReader);
String line;
// 一行一行进行处理
while ((line = reader.readLine()) != null) {
head.handleRequest(line);
}
// 对结果进行处理和展示
if (ArgsUtil.isGraphical){
generateResult(head, file);
}else{
showResult(head, file);
}
}
// 当文件属于文件夹类型,需要查看是否处于 递归 模式
if (ArgsUtil.isRecursion && file.isDirectory()){
File[] files = file.listFiles();
if (files != null) {
for (File f :
files) {
readFile(head, f);
}
}
}
}
测试运行
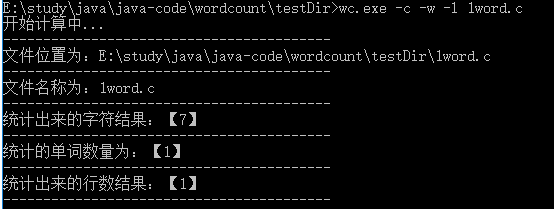
1. 只有一个字符的文件

2. 只有一个单词的文件
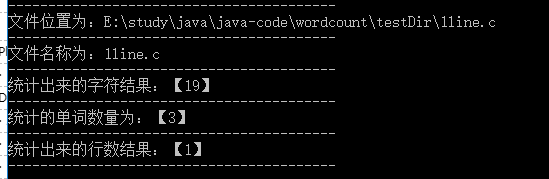
3. 只有一行的文件
4. 典型的非空文件:
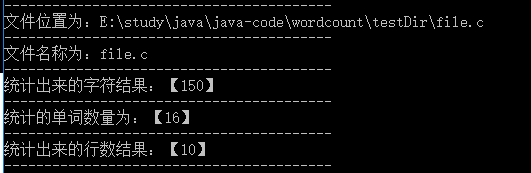
5. 特殊行处理:

6. 文件夹处理:
结果过于长,不全部展示

7. 图形界面展示:
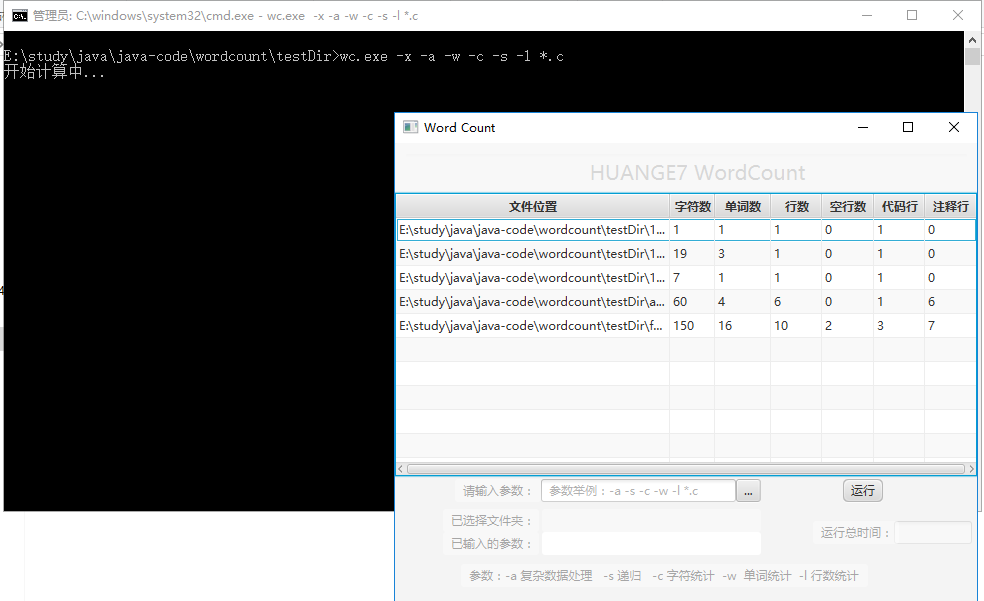
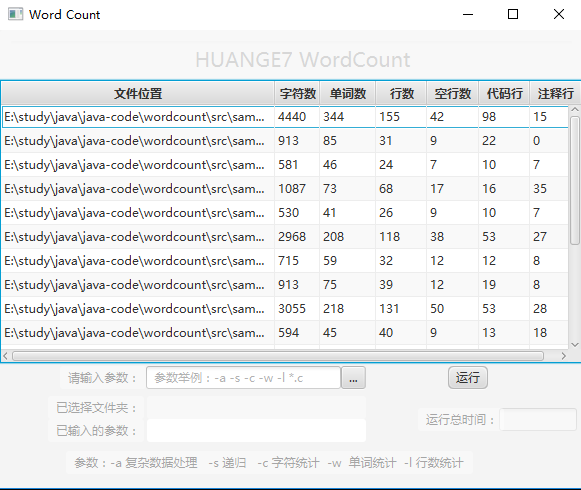
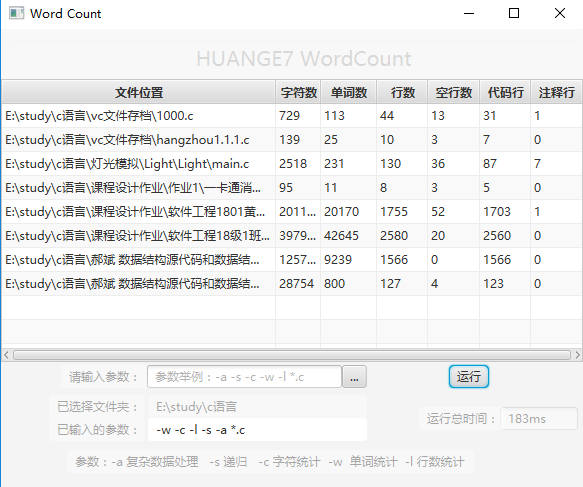
8. 图形界面使用展示:
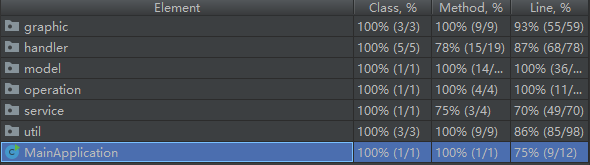
9. 测试代码及其覆盖率
10. 本程序也对用户的输入等等进行了相应的校验和提醒:
未输入参数:

错误的参数类型:

无效的参数类型:

未支持的文件类型:

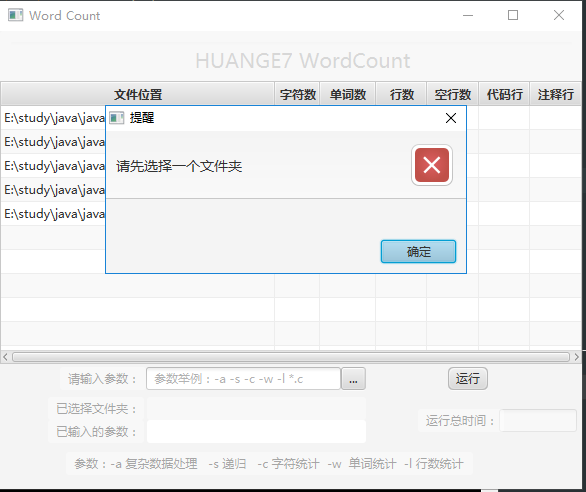
采用图形界面时未选择文件夹:
多次提交任务:
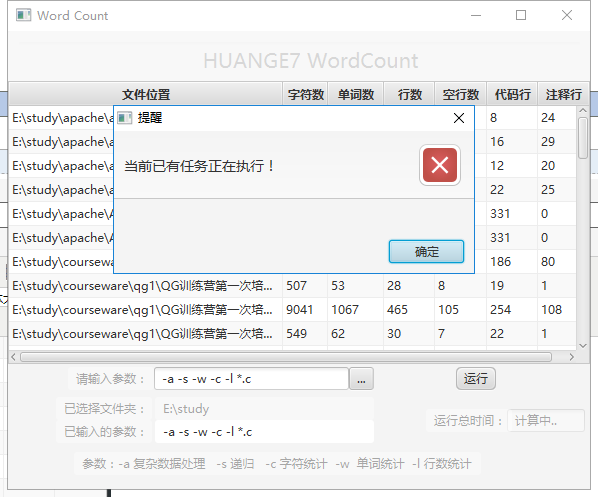
因为图形界面时是采用异步执行任务,所以一次仅允许运行一个任务。
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 40 |
| Development | 开发 | 360 | 360 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 10 |
| · Design Spec | · 生成设计文档 | 5 | 5 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| · Design | · 具体设计 | 60 | 70 |
| · Coding | · 具体编码 | 180 | 200 |
| · Code Review | · 代码复审 | 20 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 30 |
| Reporting | 报告 | 60 | 53 |
| · Test Report | · 测试报告 | 20 | 12 |
| · Size Measurement | · 计算工作量 | 5 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 35 | 31 |
| 合计 | 480 | 453 |
总结:
对于此次作业,自己从中学习到了许多,首先是对于正则表达式的学习,之前是没有尝试过去写这些正则表达式去匹配的,这次尝试了许多。
第二是使用javafx进行界面展示,由于很少使用,所以这次使用javafx时也出现了许多小问题。
这次作业给了我一个机会去更好的学习java,同时也让自己认识到了完整开发一个软件的流程,从计划,开发到测试,每一个环节都是至关重要的,因此我们应该重视这些,应该认真对待。
个人项目
1. 题目描述
Word Count
1. 实现一个简单而完整的软件工具(源程序特征统计程序)。
2. 进行单元测试、回归测试、效能测试,在实现上述程序的过程中使用相关的工具。
3. 进行个人软件过程(PSP)的实践,逐步记录自己在每个软件工程环节花费的时间。
1.1 项目要求
wc.exe 是一个常见的工具,它能统计文本文件的字符数、单词数和行数。这个项目要求写一个命令行程序,模仿已有wc.exe 的功能,并加以扩充,给出某程序设计语言源文件的字符数、单词数和行数。
实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。
具体功能要求:
程序处理用户需求的模式为:
wc.exe [parameter] [file_name]
基本功能列表:
wc.exe -c file.c //返回文件 file.c 的字符数
wc.exe -w file.c //返回文件 file.c 的词的数目
wc.exe -l file.c //返回文件 file.c 的行数
扩展功能:
-s 递归处理目录下符合条件的文件。
-a 返回更复杂的数据(代码行 / 空行 / 注释行)。
空行:本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如“{”。
代码行:本行包括多于一个字符的代码。
注释行:本行不是代码行,并且本行包括注释。一个有趣的例子是有些程序员会在单字符后面加注释:
} //注释
在这种情况下,这一行属于注释行。
[file_name]: 文件或目录名,可以处理一般通配符。
高级功能:
-x 参数。这个参数单独使用。如果命令行有这个参数,则程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、行数等全部统计信息。
需求举例:
wc.exe -s -a *.c
返回当前目录及子目录中所有*.c 文件的代码行数、空行数、注释行数。
解题思路
首先想要对一个文件进行统计行数等等,那么肯定就涉及到对文件进行IO操作了。
1. 对字符的处理
对字符的处理则是直接获取当前行数的长度以及加上默认的换行符两个字符
2. 对行数的处理
对行数的处理是直接累计每次获取的行数
3. 对单词的处理
利用正则表达式对每行中的特殊符号进行替换,换成空格。之后再根据空格进行切割。就可以获取到当前行有多少个单词。
4. 特殊行的处理
首先对注释行进行处理,利用正则表达式,对每一种注释进行匹配,当检测到不是注释行时,则进行空行的匹配,如果空行再次匹配失败,则说明是代码行。
5. 图形界面
利用javafx进行界面的编写,再进行一个总体调用程序进行调用。
6. 文件递归
每次读取单个文件夹下的所有文件(包括文件夹),之后对文件数组进行逐个遍历读取。当读取到文件夹时继续执行该函数。
遇到的困难及解决方法
- 对代码行与注释行的区分已经归类
- 尝试进行多种正则表达式的匹配
- 仍存在特殊情况无法解决
- 对正则表达式的运用更加熟悉
- 对命令行和图形界面的整合
设计实现过程
项目分包设计:
共分为6个包,分别为graphic,handler,model,operation,service,util包。
graphic包用于图形显示界面的逻辑处理
handler包用于每一行的情况处理,包括字符统计,行数统计,单词统计等等
model包用于图形界面时表格的展示
operation包包含一个枚举类,枚举了用户可能的参数
service包用于处于统计业务逻辑
util是工具包,包括字符串处理,参数处理,以及处理链的生成。
流程图
主函数流程图:
关键代码or设计说明
处理采用的是责任链模式,每个处理类构成一条处理链条,分别对对应的行进行自己相应的处理并统计。
处理链部分代码
抽象类处理代码:
/**
* 后继对象
*/
private Handler successor;
/**
* 计算数
*/
private Integer count = 0;
/**
* 处理对应的责任链
* @param line 处理的行
*/
public abstract void handleRequest(String line);
/**
* 打印统计结果
*/
public abstract void printCount();
/**
* 清空数据
*/
public void clear(){
setCount(0);
}
/**
* 取值方法
*/
public Handler getSuccessor() {
return successor;
}
/**
* 赋值方法,设置后继的责任对象
*/
public void setSuccessor(Handler successor) {
this.successor = successor;
}
/**
* 获取数量
*/
public Integer getCount() {
return count;
}
/**
* 赋值方法,设置数量
*/
public void setCount(Integer count) {
this.count = count;
}
字符处理代码:
public void handleRequest(String line) {
setCount(getCount() + line.length() + System.lineSeparator().length());
if (getSuccessor() != null){
getSuccessor().handleRequest(line);
}
}
行数处理代码:
public void handleRequest(String line) {
setCount(getCount() + 1);
if (getSuccessor() != null){
getSuccessor().handleRequest(line);
}
}
单词处理代码:
public void handleRequest(String line) {
// 将c文件中的符号转换为
String pattern = "[,;{}()#\"':<>.\\s=%+\\-*/0-9]";
setCount(getCount() + StringUtil.split(line.replaceAll(pattern, " "), " ").length);
if (getSuccessor() != null){
getSuccessor().handleRequest(line);
}
}
特殊行处理代码:
public void handleRequest(String line) {
// 设置空行正则表达式
String emptyPattern = "[\\s{}]*";
// /*注释开始标记
String startAnnotationA = "^[\\s]*/\\*.*";
// /*注释行文中开始标记
String startAnnotationB = ".*[;})][\\s]*/\\*.*";
// }注释行
String annotationSpecial = "^\\s*}\\s*/[*/].*";
// //注释开始标记
String startAnnotationC = "^[\\s]*//.*";
// //注释行文中开始标记
String startAnnotationD = ".*[;})][\\s]*//.*";
// */注释结束标记
String endAnnotation = ".*\\*/[\\s]*$";
if (isAnnotation && line.matches(endAnnotation)){
// 匹配到已经是注释模式且已经找到结束位置
isAnnotation = false;
annotationLine++;
} else if (isAnnotation){
annotationLine++;
} else if (line.matches(startAnnotationA) || line.matches(startAnnotationB)){
if (!line.matches(endAnnotation)){
isAnnotation = true;
}
annotationLine++;
} else if (line.matches(startAnnotationC) || line.matches(startAnnotationD)){
annotationLine++;
} else if (line.matches(emptyPattern)){
emptyLine++;
} else {
codeLine++;
}
if (line.matches(startAnnotationB) || line.matches(startAnnotationD)){
if (!line.matches(annotationSpecial)){
codeLine++;
}
}
setCount(getCount() + 1);
if (getSuccessor() != null){
getSuccessor().handleRequest(line);
}
}
主函数处理类:
先根据参数构造对应的处理链,接着获取文件夹的名称,对文件夹里面的文件进行逐个遍历。
public void doHandler(String fileDir, String[] args) throws IOException {
// 获取处理链
Handler head = GenerateUtil.generateChain(args);
// 获取文件名称
fileName = ArgsUtil.getFileName(args);
// 将文件名进行转换
fileName = fileName.replaceAll("[*?]", ".*");
// 获取文件夹
File file = new File(fileDir);
if (!file.exists()){
System.out.println("文件或者文件夹不存在!");
return;
}
// 获取文件夹下的文件
File[] files = file.listFiles();
if (files != null) {
for (File f :
files) {
readFile(head, f);
}
}
}
根据传入的文件是文件夹还是文件进行处理,当是文件时则进行读取,如果是文件夹则进行遍历。
结果将根据是否显示为图形函数而进行显示。public void readFile(Handler head, File file) throws IOException {
// 处理文件类型
if (!file.isDirectory()){
if (!file.getName().matches(fileName)){
return;
}
FileReader fileReader = null;
try {
fileReader = new FileReader(file);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
BufferedReader reader = new BufferedReader(fileReader);
String line;
// 一行一行进行处理
while ((line = reader.readLine()) != null) {
head.handleRequest(line);
}
// 对结果进行处理和展示
if (ArgsUtil.isGraphical){
generateResult(head, file);
}else{
showResult(head, file);
}
}
// 当文件属于文件夹类型,需要查看是否处于 递归 模式
if (ArgsUtil.isRecursion && file.isDirectory()){
File[] files = file.listFiles();
if (files != null) {
for (File f :
files) {
readFile(head, f);
}
}
}
}
测试运行
1. 只有一个字符的文件
2. 只有一个单词的文件
3. 只有一行的文件
4. 典型的非空文件:
5. 特殊行处理:
6. 文件夹处理:
结果过于长,不全部展示
7. 图形界面展示:
8. 图形界面使用展示:
9. 测试代码及其覆盖率
10. 本程序也对用户的输入等等进行了相应的校验和提醒:
未输入参数:
错误的参数类型:
无效的参数类型:
未支持的文件类型:
采用图形界面时未选择文件夹:
多次提交任务:
因为图形界面时是采用异步执行任务,所以一次仅允许运行一个任务。
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 40 |
| Development | 开发 | 360 | 360 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 10 |
| · Design Spec | · 生成设计文档 | 5 | 5 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| · Design | · 具体设计 | 60 | 70 |
| · Coding | · 具体编码 | 180 | 200 |
| · Code Review | · 代码复审 | 20 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 30 |
| Reporting | 报告 | 60 | 53 |
| · Test Report | · 测试报告 | 20 | 12 |
| · Size Measurement | · 计算工作量 | 5 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 35 | 31 |
| 合计 | 480 | 453 |
总结:
对于此次作业,自己从中学习到了许多,首先是对于正则表达式的学习,之前是没有尝试过去写这些正则表达式去匹配的,这次尝试了许多。
第二是使用javafx进行界面展示,由于很少使用,所以这次使用javafx时也出现了许多小问题。
这次作业给了我一个机会去更好的学习java,同时也让自己认识到了完整开发一个软件的流程,从计划,开发到测试,每一个环节都是至关重要的,因此我们应该重视这些,应该认真对待。