1、Redis 与MySQL数据双写一致性工程落地案例
你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
双写一致性,你先动缓存redis还是数据库mysql哪一个?whby?
1.1、概要
canal ,主要用途是用于MySQL数据库增量日志数据的订阅、消费和解析,是阿里巴巴开发并开源的,采用Java语言开发,历史背景是早期阿里巴巴因为杭州和美国双机房部署,存在跨机房数据同步的业务需求,实现方式主要是基于业务trigger(触发器)获取增量变更。从2010年开始,阿里巴巴逐步尝试采用解析数据库日志获取增量变更进行同步,由此衍生出了canal项目;
1.2、作用
- 数据库镜像数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务cache 刷新
- 带业务逻辑的增量数据处理
1.3、mysql主从复制的原理

MySQL的主从复制将经过如下步骤:
- 当master主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件中;
- salve 从服务器会在一定时间间隔内对 master主服务器上的二进制日志进行探测,探测其是否发生过改变,如果探测到 master主服务器的二进制事件日志发生了改变,则开始一个I/O Thread请求master二进制事件日志;
- 同时 master主服务器为每个I/O Thread启动一个dump Thread(转储线程),用于向其发送二进制事件日志;
- slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中;
- salve 从服务器将启动SQL Thread 从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致;6、最后I/O Thread和SQL Thread将进入睡眠状态,等待下一次被唤醒;
1.4、canal工作原理
canal模拟MySQL slave 的交互协议,伪装自己为MySQL slave,向MySQL master 发送dump协议,MySQL master 收到 dump请求,开始推送 binary log 给 slave(即 canal ),canal解析 binary log 对象(原始为 byte流)

1.5、具体操作
分布式系统只有最终一致性,很难做到强一致性
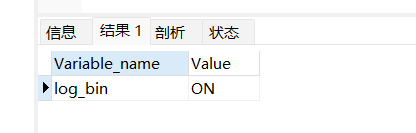
- 查看是否开启log_bin复制
SHOW VARIABLES LIKE 'log_bin'
- 修改数据库配置 my.ini 或者my.conf
log-bin=mysql-bin #开启binlog
binlog-format=ROW#选择ROW模式
server_id=1—#配置MySQL replaction需要定义,不要和canal的 slaveld重复
- ROW模式除了记录sql语句之外,还会记录每个字段的变化情况,能够清楚的记录每行数据的变化历史,但会占用较多的空间。
- STATEMENT模式只记录了sql语句,但是没有记录上下文信息,在进行数据恢复的时候可能会导致数据的丢失情况;-
- MIX模式比较灵活的记录,理论上说当遇到了表结构变更的时候,就会记录为statement模式。当遇到了数据更新或者删除情况下就会变为row模式;

- 创建授权
//删除canal用户
DROP USER 'canal'@'%';
//创建canal用户
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal"';
FLUSH PRIVILEGES;
//查询用户
SELECT* FROM mysql.user;
- 下载软件
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.deployer-1.1.5.tar.gz
-
修改配置

-
启动服务
-
客户端代码
package com.atguigu.redis.controller;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import java.net.InetSocketAddress;
import java.util.List;
public class RedisCanalClientController {
public static final Integer _60SECONDS = 60;
public static void main(String[] args) {
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.1.100",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
// connector.subscribe(".*\\..*");
connector.subscribe("redis_demo.t_user");
connector.rollback();
int totalEmptyCount = 10 * _60SECONDS;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
2、缓存双写一致性之更新策略
2.1、缓存双写一致性
- 如果redis中有数据,需要和数据库中的值相同
- 如果redis中无数据,数据库中的值要是最新值
读写缓存:采用同步直写策略, 写缓存时也同步写数据库,写数据库时也要同步写缓存,缓存和数据库中的数据一致,对于读写缓存来说,要想保证缓存和数据库中的数据一致,就要采用同步直写策略
-
什么时候同步直写?
小数据,某条、某—小撮热点数据,要求立刻变更,可以前台服务降级一下,后台马上同步直写。 -
什么时候异步缓写?
- 正常业务,马上更新了mysql,可以在业务上容许出现1个小时后redis起效
- 出现异常后,不得不将失败的劝作重新修补,不得不借助kafka或者RabbitMQ等消息中间件,实现解耦后重试重写。
2.2、数据库和缓存一致性的几种更新策略
目的是保证数据的最终一致性的解决方案。
所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存,达到一致性,切记以mysql的数据库写入库为准。
- 挂牌报错,凌晨升级:单线程,这样重量级的数据操作最好,不要多线程,比方说不得不更新数据库和redis的时候,以及大量数据的时候。
2.2.1、 先更新数据库,再更新缓存
出现的异常情况:
- 先更新mysql的某商品的库存,当前商品的库存是100,更新为99个。
- 先更新mysql修改为99成功,然后更新edis。
- 此时假设异常出现,更新redis失败了,这导致mysql里面的库存是99而redis里面的还是100。
- 上述发生,会让数据库里面和缓存redis里面数据不一致,读到脏数据
先更新数据库,再更新缓存,但是redis如果异常更新失败,导致从redis还是读取到了老的脏数据.
2.2.2、 先删除缓存,再更新数据库
2.2.2.1、异常情况:
-
A线程先成功删除了redis里面的数据,然后去更新mysql,此时mysql正在更新中,还没有结束(比如网络延时),这时B突然出现要来读取缓存数据。

-
此时redis里面的数据是空的,B线程来读取,先去读redis里数据,但是redis中的数据已经被A线程delete掉了,此处出来2个问题:
这时就会出现两种情况:- 第一种是B线程从mysql获得了旧值。B线程发现redis里没有(缓存缺失),马上去mysql里面读取,而此时数据库中A线程要更改的数据还未写入成功,从数据库里面读取来的是旧值。
- 第二种是B线程会把获得的旧值写回redis。B线程获得旧值数据后返回前台,并回写进redis(刚被A线程删除的旧数据有极大可能又被写回了)。

2.2.2.2、问题的原因
两个并发操作,一个是更新操作,另一个是查询操作,A线程更新操作,删除缓存后,B线程查询操作没有命中缓存,B线程先把老数据读出来后放到缓存中,然后A线程更新操作更新了数据库。但是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还可能一直这样脏下去了。
这种方式如果实在低并发的情况下,会写回旧值,高并发的环境会出现缓存击穿的问题。
2.2.2.3、解决方案
采用延时双删策略,

加上sleep的这段时间,就是为了模拟先让线程B能够先从数据库读取数据,再把缺失的数据写入缓存, 然后,线程A再进行删除。所以,线程A 进行sleep的时间,就需要大于线程B读取数据再写入缓存的时间。这样一来,其它线程读取数据时,会发现缓存缺失,所以会从数据库中读取最新值。因为这个方案会在第一次删除缓存值后,延迟一段时间再次进行删除,所以我们也把它叫做“延迟双删”。
2.2.2.3、延迟双删的缺点
- 这个删除该休眠多久呢?
多次请求接口,获取平均值,在平均值的这基础上加上一定的时间 - 当前演示的效果是mysql单机,如果mysql主从读写分离架构如何?
也是多次请求接口,获取平均值,但是需要算上主从同步的时间,在平均值的这基础上加上一定的时间。 - 这种同步淘汰策略,吞吐量降低怎么办?
启动一个守护线程,异步去删除,也就是说,更新完数据库之后,启动一个新的线程,异步的去删除缓存的数据。

2.2.3、 先更新数据库,再删除缓存
2.2.3.1、存在的问题
如果A线程先更改数据库中的值,如果数据库中数据还未更新完成,此时,线程B,来缓存中进行数据的读取,因为A线程未更新完毕,导致B线程缓存中的数据还是旧数据.
先更新数据库,再删除缓存,假如缓存删除失败或者来不及,导致请求再次访问redis时缓存命中,读取到的是缓存旧值。
2.2.3.2、解决方案:
可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用Kafka/RabbitMQ等)。当程序没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进次删除或更新。如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了,否则还需要再次进行重试。如里重试超过的—定次数后还旱沿有成功,我们就熏要向业各目发送据错信自了,通知运维人员。

流程:
- 更新数据库数据
- 数据库会将操作信息写入binlog日志当中
- 订阅程序提取出所需要的数据以及key
- 另起一段非业务代码,获得该信息
- 尝试删除缓存操作,发现删除失败
- 将这些信息发送至消息队列
- 重新从消息队列中获得该数据,重试操作。
2.2.4、(绝对不允许)先更新缓存,再更新数据库这种策略
2.2.5 、总结
在大多数业务场景下,我们会把Redis作为只读缓存使用。
假如定位是只读缓存来说,理论上我们既可以先删除缓存值再更新数据库,也可以先更新数据库再删除缓存,但是没有完美方案,两害相衡趋其轻的原则,个人建议是,优先使用先更新数据库,再删除缓存的方案。理由如下:
- 先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力,严重导致打满mysql,造成缓存击穿。
- 如果业务应用中读取数据库和写缓存的时间不好估算,那么延迟双删中的等待时间就不好设置。
如果使用先更新数据库,再删除缓存的方案,如果业务层要求必须读取一致性的数据,那么我们就需要在更新数据库时,先在Redis缓存客户端暂存并发读请求,等数据库更新完、缓存值删除后,再读取数据,从而保证数据一致性。
