像梯度下降法这样的,通过偏导来优化参数,统称的优化算法。
优化算法:为了寻找最优参数,提升模型训练的速度(加快梯度下降)。
mini-batch
-
BGD:批量梯度下降
- 每次迭代都用到训练集的所有数据。
- 虽然BGD批量梯度下降容易到全局最优解,但是数据量大对内存占用多,迭代的特别慢,每次遍历数据集只做一次梯度下降,而mini-batch一次遍历训练集能做n次梯度下降(n是batch),可以边调整边运算。
-
SGD:随机梯度下降
- 每次迭代只考虑一个样本。
- SGD随机梯度下降虽然迭代速度快,但是它可能不是全局最优解,并且每次迭代的时候用不到向量化带来的优势,mini-batch每次用一批样本梯度下降,相对来说波动小一些
-
mini-batch GD:小批量梯度下降
- 每次迭代用一批样本
梯度下降存在的问题
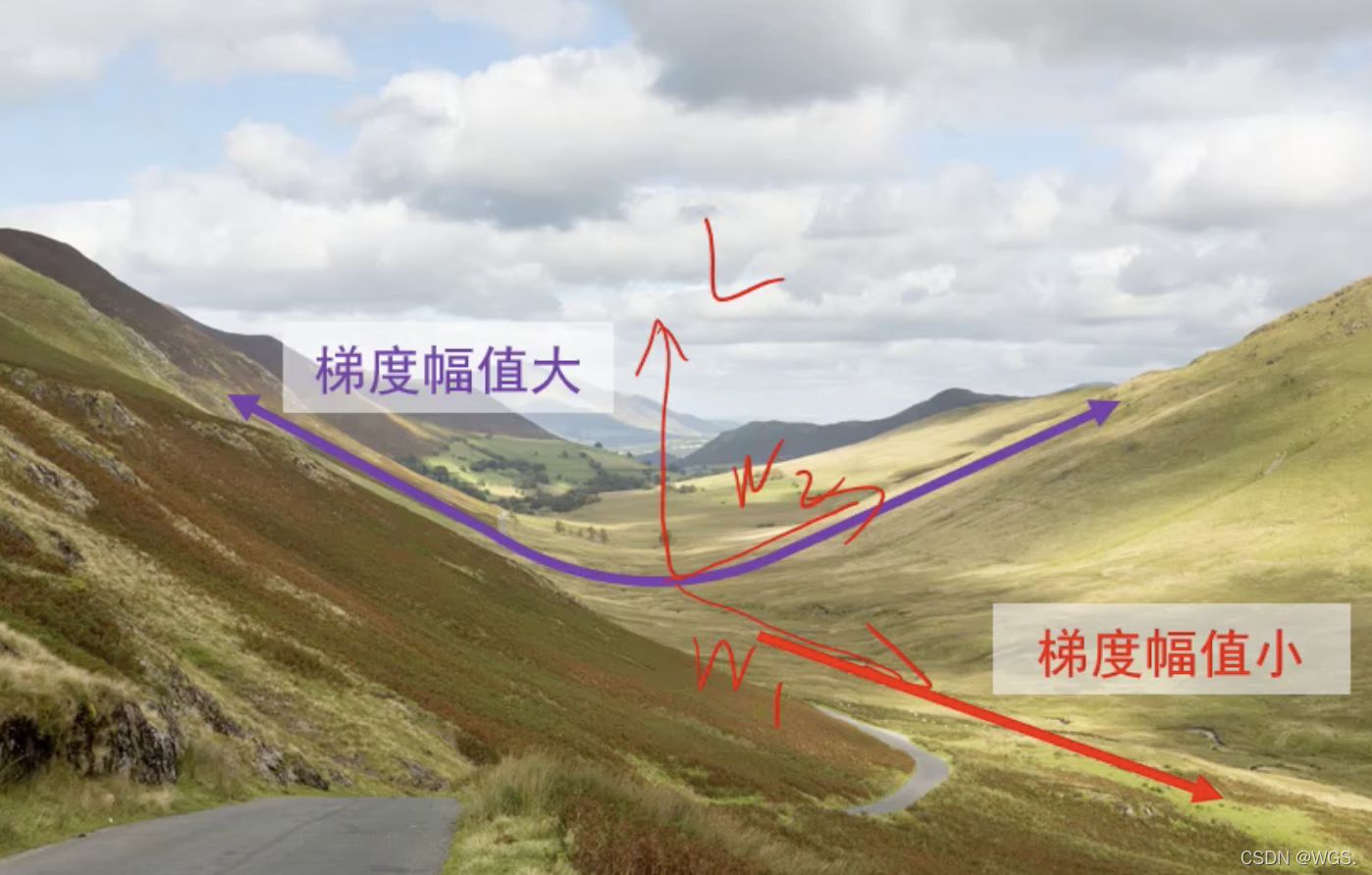
- 损失函数特性:一个方向上变化迅速,而另一个方向上变化缓慢。
-
如图所示,损失L在w2方向是一个震荡方向,在w1方向又比较平坦。
-
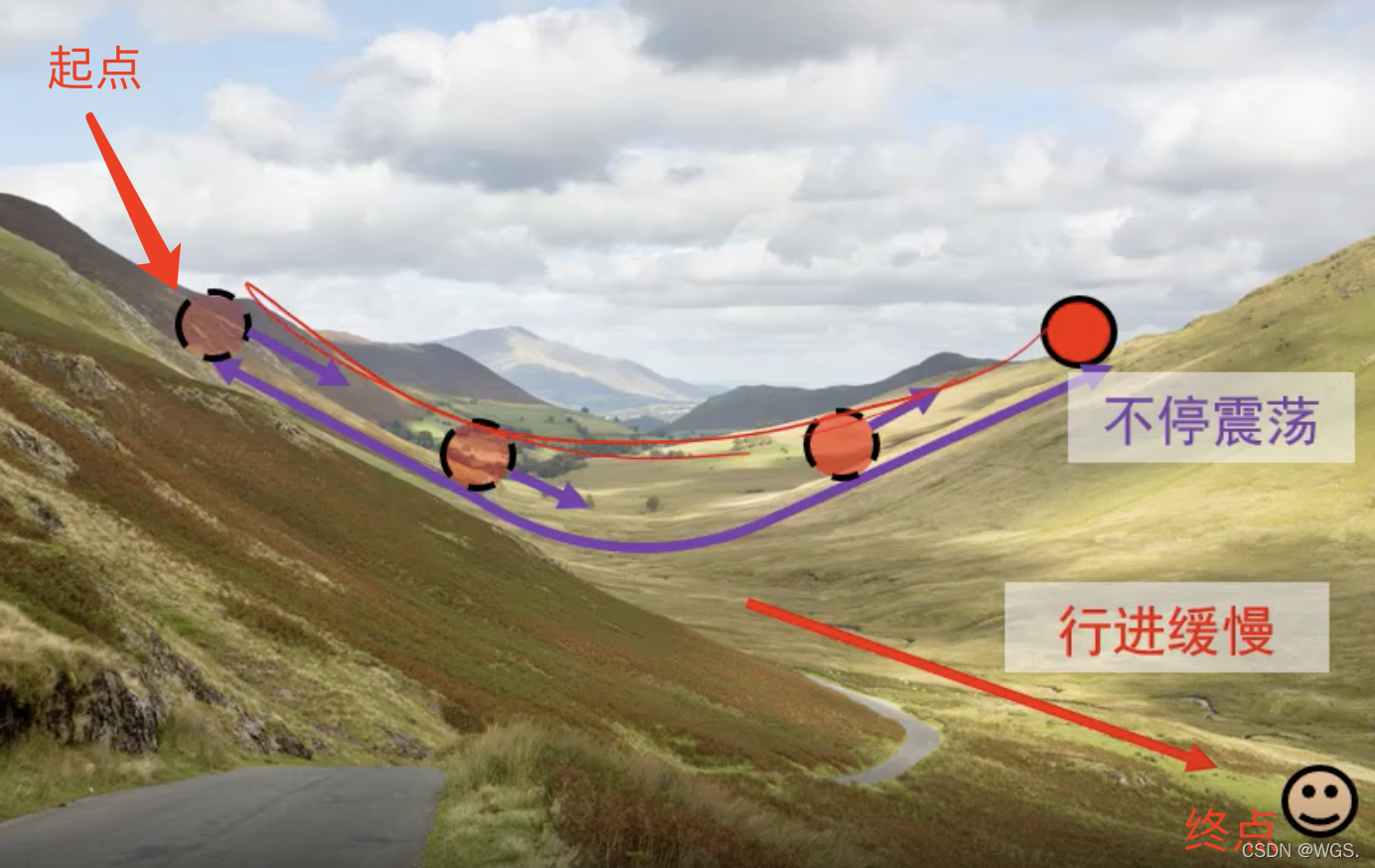
当我们的优化目标如上图为从起点处走到低端笑脸处,梯度下降存在的问题就是:山壁间震荡,往谷底方向的行进较慢。
-
这时网络训练的就很慢,损失下降的很小。可以理解为它把大量的功都用在了无用的震荡上了。
注意:增大步长
(学习率)并不能加快算法收敛速度,因为w2方向的梯度大,w1方向的平缓,所以它会往w2方向运动,w2方向是山谷,所以会反复震荡,而w1方向比较平缓,所以下降的很慢。增加步长相当于在w2方向加了更大的速度,w1方向也加了但是很小。
动量法 Momentum
- 目标:改进梯度下降算法存在的问题,即减少震荡,加速通往谷底。
- 改进思想:利用累加历史梯度信息更新梯度。
- 在w2方向,往左、往右的梯度一累加就会被抵消了。
- 在w1方向,也会慢慢的累加变大。

-
与mini-batch相比多了步骤3、步骤4。
-
步骤3: v v v就是累加值, μ μ μ为衰减系数。新的累加值等于当前梯度和历史累加值相加。
- 为什么有效:这个累加过程中,震荡方向会被抵消,前进方向
(平坦方向)会被加强。 - μ μ μ取值范围为 μ ∈ [ 1 , 0 ) ] μ ∈ [1, 0)] μ∈[1,0)], μ = 0 μ=0 μ=0时就等价于梯度下降算法。建议设置为0.9。
- 极端情况如果 μ = 1 μ=1 μ=1的话, v = v + g v = v+g v=v+g,那么梯度 g g g就会不停的加到历史累加值里去。即使已经走到了平坦区了
(g等于0),但是更新量v不为0,即权重会一直更新下去,它停不下来了。 - 当 μ = 0.9 μ=0.9 μ=0.9时,即使走到平坦区, v = 0.9 v v = 0.9v v=0.9v,迭代个几轮也会慢慢的衰减下来,就好比是一个摩擦系数。
- 为什么有效:这个累加过程中,震荡方向会被抵消,前进方向
-
步骤4:更新权值的时候用的是累加值 v v v
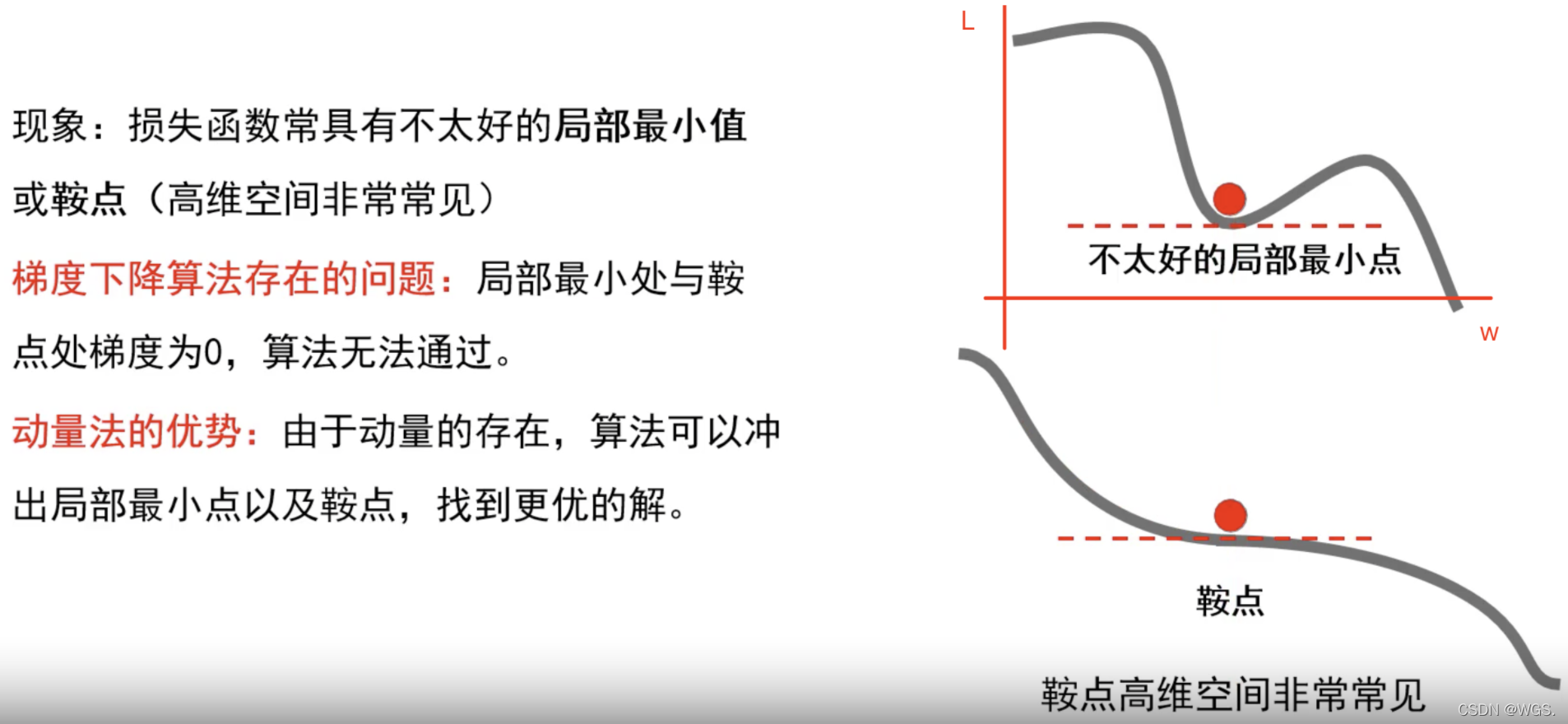
- 根据步骤3,即使在局部最小点或鞍点,梯度为0了, v = μ v v = μv v=μv 它还会往前跑一跑,有机会冲出鞍点或局部最小点。
自适应梯度 AdaGrad
-
改进思想:自适应梯度法通过减小震荡方向步长,增大平坦方向步长来减小震荡,加速通往谷底。
- 不用同一个步长,分别改变震荡方向和平坦方向的步长。
- 比如之前的做法两个方向都采用相同的步长:
w 1 = w 1 − ϵ ∂ L ∂ w 1 w 2 = w 2 − ϵ ∂ L ∂ w 2 w_1 = w_1 - \epsilon \frac{\partial L}{\partial w_1} \\ w_2 = w_2 - \epsilon \frac{\partial L}{\partial w_2} w1=w1−ϵ∂w1∂Lw2=w2−ϵ∂w2∂L
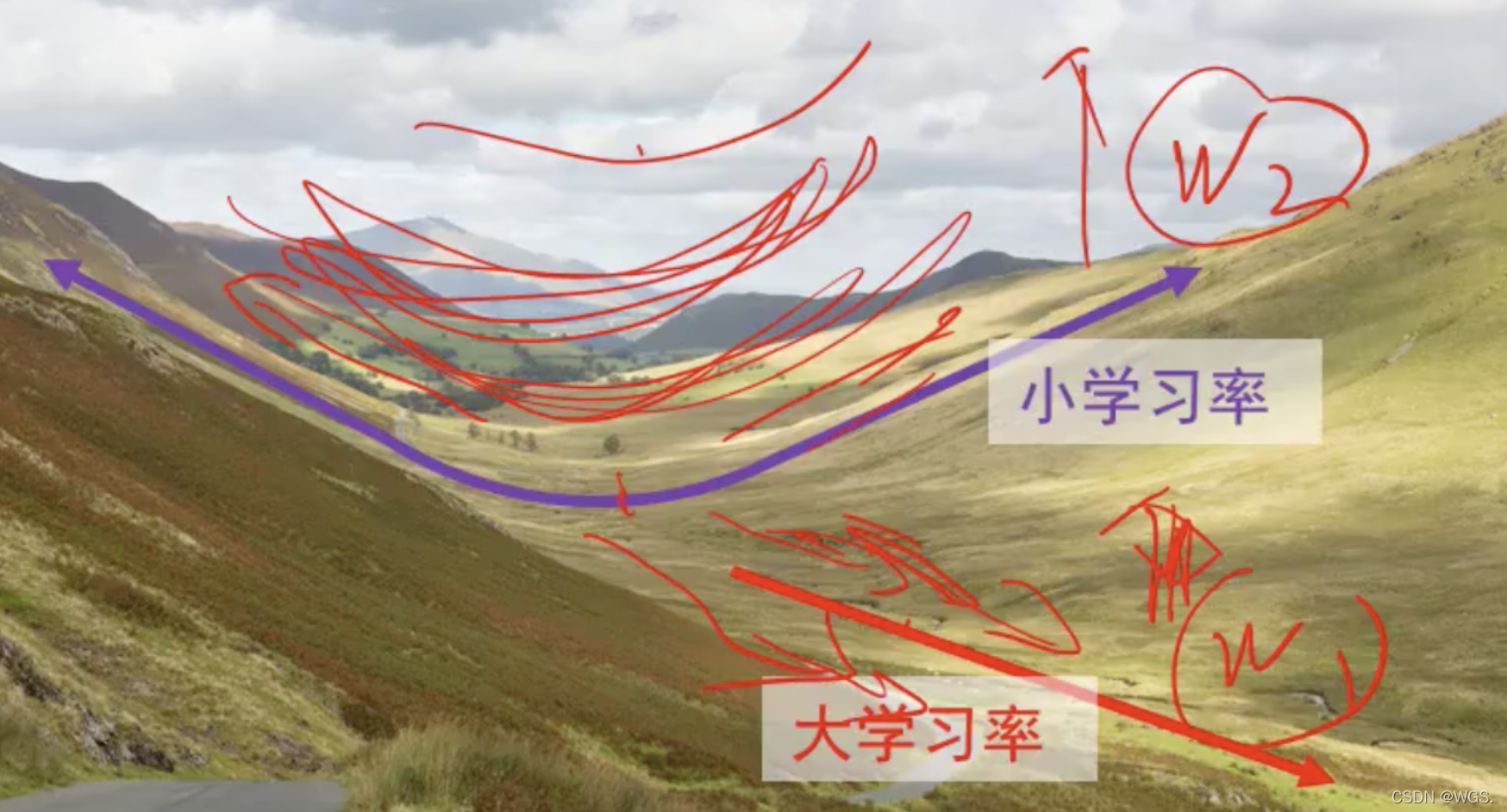
- 光把一个步长加大实际上是没有意义的,震荡方向也会加的很大。
-
所以改进的思想就是, w 1 w_1 w1一个步长, w 2 w_2 w2一个步长, w 1 w_1 w1的步长大一些, w 2 w_2 w2的步长小一些。这就是自适应梯度法的核心。
- 那么如何区分震荡方向与平坦方向呢?
- 将历史梯度累加:
- 梯度幅度的平方较大的方向是震荡方向;
- 梯度幅度的平方较小的方向是平坦方向;

-
通过第3步计算累加值,来确定当前方向是或者不是震荡方向,将 g 2 g^2 g2加到历史累计值,如果历史走过来是一个很大的梯度,那么这个方向很大可能就是震荡方向。
-
通过第4步实现自适应更新权值:
w = w − ϵ r + δ g w = w - \frac{\epsilon}{\sqrt r + δ} g w=w−r+δϵg- 对于上面的 w 1 w_1 w1
(平坦方向)而言,因为 g g g比较小,所以累积值 r r r也比较小,总步长 ϵ \epsilon ϵ除以一个比较小的值,所以 w 1 w_1 w1就被放大了; - 对于上面的 w 2 w_2 w2
(震荡方向)而言,g 、 r g、r g、r都比较大,分母也大,所以导致 w 2 w_2 w2减小;
- 对于上面的 w 1 w_1 w1
-
虽然AdaGrad能够自适应的增大和减小步长,但是也存在问题:
- 第3步的 r r r会一直被累加,到最后会是一个非常大的值,所以 r \sqrt r r很大就会失去对 ϵ \epsilon ϵ的调节作用,它会让其变成一个很小的值。
自适应梯度 RMSProp

RMSProp的做法,第3步:
- 每次的历史梯度加上一个衰减值 p r pr pr;
- 当前梯度的方法 g 2 g^2 g2加上一个(1-p)的控制项;
- 通过混合这两个来生成当前的累加平方值。
- 当 p p p等于0的时候,就剩了个当前梯度的平方,当梯度的平方很大时候,就把这个方向的速度降慢一点;梯度小的方向增大一点;
- 当 p p p等于1的时候,当前的梯度就没用了,累积值 r r r就会从初始值0不会改变了,所以 p p p通常会设置为0.999;
- 当梯度老是0的话, r r r每次都会乘0.999,连乘下去也会非常小。
- p p p也可以这么理解,当 p p p是1的话,它考虑了所有的历史值;当 p p p是0的话,它不考虑历史值只考虑当前值。所以增大 p p p就表示考虑的历史值越多。比如累积值 r r r只care近100轮的累加,100次之前的都不考虑,这样就不会出现累积值 r r r越来越大的情况。
ADAM
- 改进思想:同时使用动量与自适应梯度思想。

- ADAM就有两个累积量了:
- 一个是历史梯度的累加值 v v v;
- 一个是历史梯度平方的累加值 r r r,表示当前点是不是震荡方向;
- 第3步累加历史梯度,动量法的核心用于更新速度。这里加了一个 ( 1 − μ ) (1-μ) (1−μ),可以理解为当前的梯度和历史梯度以一定的比例混合一下,来得到当前要更新的 v v v。
- 第4步自适应思想,通过 r r r来改变学习率。
- 第5步修正偏差,可以极大缓解算法初期的冷启动问题;
- 初始的 μ = 0.9 , v = 0 μ=0.9,v=0 μ=0.9,v=0,最开始启动的时候,第一次的 v ( 1 ) = 0 + 0.1 g v^{(1)} = 0 + 0.1 g v(1)=0+0.1g,这就是第一次更新时候的梯度值,如果不进行修正的话直接拿 v ( 1 ) v^{(1)} v(1)的话,就只能得到 0.1 0.1 0.1倍的梯度来进行运作,相当于开始的时候让梯度缩小了10倍来进行更新,它会走的很慢;
- 同理 r r r也是一样;
- 如果进行偏差修正, v ~ ( 1 ) = 0.1 g 1 − ( 0.9 ) 1 = g \tilde{v}^{(1)} = \frac{0.1 g}{1 - (0.9)^1} = g v~(1)=1−(0.9)10.1g=g
- 其中 t t t为迭代轮次。
- 它能保证冷启动第一次更新的时候用当前原始的梯度 g g g更新,不至于一开始就走的很慢。
- 当 t t t增大,分母为 ( 1 − ( 0.9 ) 10 ) (1-(0.9)^{10}) (1−(0.9)10),几乎就是1,那么 v ~ ≈ v \tilde{v} ≈ v v~≈v,也就是说明过了最开始的冷启动阶段后,修正项就不起作用了。
- 所以修正项只在初期的时候起作用,来防止走的很慢。
- 第6步更新,用 v v v来代替原来的 g g g
(动量法),用 ϵ r + δ \frac{\epsilon}{\sqrt r + δ} r+δϵ来代替原来的 ϵ \epsilon ϵ(自适应梯度),这俩合起来的更新策略就是Adam。
小结
- 动量法是靠累加的自消彼涨来实现的。
- 自适应是靠不同的方向迈不同的步长来实现的。
- ADAM是将两者合二为一。
一般使用adam即可。
adam没有动量+SGD调优的效果好,但是不容易练出比较好的丹。
reference: