论文总结:A trustworthy industrial data management scheme based on redactable blockchain(基于可编辑区块链的工业物联网数据管理机制)
1.背景
\qquad 工业物联网的数据安全涉及到收集、传递、存储和分析等方面,如果数据安全无法保障,那么物联网上的各种设备的安全性也无法被保障。例如在2015年
\qquad 可编辑区块链技术也已经被提出,可编辑区块链采用了变色龙哈希。可编辑区块链依据陷门管理方式划分为两种:集中式可编辑区块链和分布式可编辑区块链。集中式可编辑区块链当中有一个管理者对陷门进行管理,但但这种情况下如果管理者被攻击,则陷门的安全也无法保障,并且管理者也有可能成为不诚实的;而分布式可编辑区块链指的是将陷门管理权限下放给不同的实体,这些实体共同管理陷门,这种管理方式缺陷是如果其中一个节点不诚实,那么就有可能提供恶意的陷门片段,导致陷门恢复失败。
2.相关工作
\qquad 传统的工业数据管理应用出现了安全和效率的瓶颈,区块链的出现有助于突破这个瓶颈。由于区块链具有去中心化、可追溯和数据不可变的特点,和区块链相关的工业数据管理方案被不断提出,但他们都忽视了区块链上的有害数据治理问题。
\qquad 可编辑区块链最早于2016年被提出,该方案采用了变色龙哈希,采用这种哈希函数的原因是避免哈希值因为区块链数据的修改而改变。
\qquad 本文指出:集中式可编辑区块链当中的集中式陷门管理者在工业物联网环境下不存在,并且集中式可编辑区块链中的陷门管理者需要面对被攻击的风险。如果采用分布式区块链则会导致陷门回复过程中消耗大量的算力,这对于物联网设备来说不能接受。
3.本文方案简介和前置知识
3.1变色龙哈希
\qquad 变色龙哈希是一种带有陷门的哈希函数,设计变色龙哈希时需要满足:拥有两个信息 x ′ x' x′和 x x x且 x ≠ x ′ x \neq x' x=x′的情况下仍然有 H ( x ′ ) = H ( x ) H(x')=H(x) H(x′)=H(x),其中 H ( ) H() H()代表的含义是变色龙哈希函数。变色龙哈希函数的基本结构分为以下四个方面:
\qquad (1)初始化:需要构造安全参数 λ \lambda λ以及两个大质数 p p p和 q q q并满足 q ∣ ( p − 1 ) q|(p-1) q∣(p−1),输出是一个乘法群 Z p ∗ Z_{p}^{*} Zp∗,其中生成元为 λ \lambda λ,阶数为 q q q。
\qquad (2)密钥生成:私钥为 x ∈ Z q ∗ x \in Z_{q}^{*} x∈Zq∗ ,公钥为 y ≡ g x m o d p y \equiv g^{x} mod p y≡gxmodp。
\qquad (3)哈希计算:选取一个随机数 r r r,利用前两步的生成元、公钥对信息 m m m进行哈希计算得到 H a s h ( y , m , r ) = g m y r Hash(y,m,r)=g^{m}y^{r} Hash(y,m,r)=gmyr。
\qquad (4)构造碰撞:针对一个新的信息 m ′ m' m′,构造一个新的随机数 r ′ = ( m − m ′ + x r ) x − 1 r'=(m−m′+xr)x^{-1} r′=(m−m′+xr)x−1,使得 H a s h ( y , m ′ , r ′ ) = H a s h ( y , m , r ) Hash(y,m',r') =Hash(y,m,r) Hash(y,m′,r′)=Hash(y,m,r)。
3.2密钥共享
\qquad 本方案采用的是Shamir密钥共享,这种方案的优势是将密钥分发给 n n n个人,而恢复密钥的时候只需要 t t t个人(满足 t < n t < n t<n)即可恢复密钥。Shamir密钥共享方案用于本方案的陷门恢复部分。
\qquad (1)初始化:生成随机两个大素数 p p p和 q q q,需要满足 q ∣ ( p − 1 ) q|(p−1) q∣(p−1),并设定密钥持有者人数 n n n和门限值 t t t,门限值作用是规定有恢复密钥需要 t t t个人。
\qquad (2)密钥分配:密钥分发过程中, t t t个人随机选取属于自己的 a i a_{i} ai,其中 i ∈ [ 0 , t − 1 ] i \in [0,t-1] i∈[0,t−1],并且 a 0 a_{0} a0是被共享的密钥,密钥片段分配时,首先需要计算表达式 f ( x ) = a 0 + a 1 x + a 2 x 2 + ⋅ ⋅ ⋅ + a t − 1 x t − 1 f(x)=a_{0}+a_{1}x+a_{2}x^{2}+\cdot\cdot\cdot+a_{t-1}x^{t-1} f(x)=a0+a1x+a2x2+⋅⋅⋅+at−1xt−1,每个人都需要随机选择 x i ( i ∈ [ 1 , n ] ) x_{i}(i \in [1,n]) xi(i∈[1,n]),密钥片段将会以 ( x i , f ( x i ) ) (x_{i},f(x_{i})) (xi,f(xi))的形式保存。
\qquad (3)密钥恢复:当有 t t t个密钥片段持有者时,通过拉格朗日插值多项式进行密钥恢复,多项式为: F ( x ) = { ∑ i = 1 t ( y i ∏ 1 ≤ j ≤ t , j ≠ i ( x − x j ) ( ∏ 1 ≤ j ≤ t , j ≠ i ( x j − x i ) ) − 1 ) } m o d ( p ) F(x)=\left\{\sum_{i=1}^{t}\left(y_{i} \prod_{1 \leq j \leq t, j \neq i}\left(x-x_{j}\right)\left(\prod_{1 \leq j \leq t, j \neq i}\left(x_{j}-x_{i}\right)\right)^{-1}\right)\right\} \bmod (p) F(x)={ ∑i=1t(yi∏1≤j≤t,j=i(x−xj)(∏1≤j≤t,j=i(xj−xi))−1)}mod(p),恢复的结果就是 a 0 a_{0} a0。
####4.系统模型
4.1模型概述和攻击概述
\qquad 整个系统分为四个角色:管理者、密钥生成中心(KGC)、陷门片段持有者和执行者,管理者职责是进行初始化(创建区块链并进行参数设置),区块链创建完成后系统管理者将会退出系统;密钥生成中心是一个可靠的第三方实体,这个实体只负责陷门生成并进行陷门片段的分发,陷门持有者都是诚实的,他们持有陷门片段,确保区块链上的数据安全。执行者的作用是当完整的陷门恢复之后,对可编辑区块链上的数据进行修改。
\qquad 整个系统分为七个算法,分别是:初始化(Setup)、陷门生成(TrapdoorGen)、公钥生成(PKGen)、哈希计算(CHash)、恢复陷门(VerRestore)、恢复陷门的备份方法(AltRestore)和碰撞构造(Forge)。
\qquad 哈希计算需要事先知道系统参数(生成元)、公钥和随机数,之后利用变色龙哈希函数进行计算。
\qquad 陷门恢复需要满足至少有 t t t个陷门片段持有者,此时调用陷门恢复算法就可以恢复完整的陷门。
\qquad 陷门恢复的备份方法是在陷门回复(VerRestore)失效的情况下进行使用的,这就增强了系统的鲁棒性。
\qquad 碰撞构造算法输入旧的信息、新的信息、旧的随机数以及生成元,输出的元素是新的随机数,新的随机数满足公式 H a s h ( y , m ′ , r ′ ) = H a s h ( y , m , r ) Hash(y,m',r') =Hash(y,m,r) Hash(y,m′,r′)=Hash(y,m,r)。
\qquad 在攻击模型中,需要满足的前提条件是:双链结构是安全的并且陷门片段持有者事先已经选定且不会受到攻击。
4.2系统的实现方法
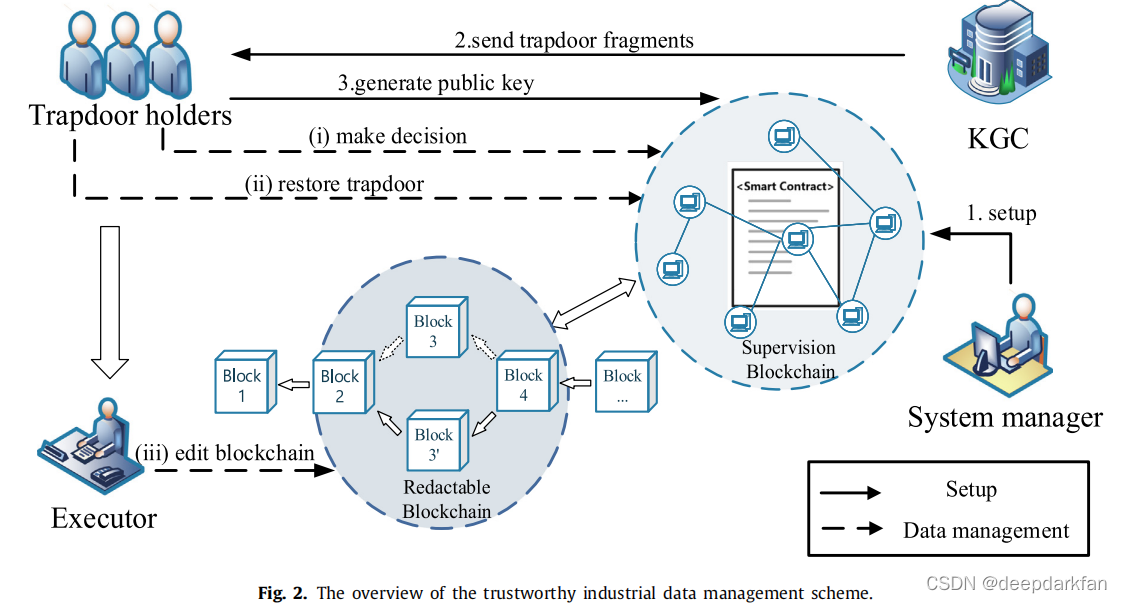
\qquad 首先,系统的管理者将会构建用于监管的区块链和可编辑区块链,之后KGC将会创建陷门,并将陷门片段发放给陷门持有者,这些陷门持有者将会生成公钥,当陷门持有者恢复陷门和做出决定的时候,这些决定将会被写入监管区块链,当决定通过后,执行者才会去编辑区块链信息。
\qquad 系统分为三个阶段:区块链初始化阶段(off-chain setup phase)、密钥初始化阶段(on-chain setup phase)和数据管理阶段。on-chain被翻译成密钥初始化阶段是因为这一阶段区块链已经创建完毕。
\qquad 区块链初始化阶段:这一阶段分为两个算法Setup和TrapdoorGen,Setup算法作用是生成可编辑区块链和用于监管的区块链,以及系统所需要的两个大素数 p , q p,q p,q和生成元 g g g,这三个参数将写入两条链的智能合约当中。TrapdoorGen负责陷门的生成,陷门生成后,将按照Shamir共享的方式进行陷门片段的分发,陷门片段表示为 x i x_{i} xi,陷门 T = ∏ i = 1 n x i T=\prod^{n}_{i=1}x_{i} T=∏i=1nxi,而Shamir表达式当中的 a 0 a_{0} a0的值为 T T T。
\qquad 密钥初始化阶段:该算法负责系统公钥的生成,公钥生成需要陷门片段和生成元的参与,第一个门限片段持有者进行运算 y 1 = g x 1 m o d p y_{1}=g^{x_{1}} \bmod p y1=gx1modp, y 2 y_{2} y2的计算又与 y 1 y_{1} y1直接相关, y 2 y_{2} y2的计算方式为 y 2 = y 1 x 2 y_{2}=y_{1}^{x_{2}} y2=y1x2,即 y 2 = g x 1 x 2 y_{2}=g^{x_{1}x_{2}} y2=gx1x2,由此可得 y = y n = g ∏ i = 1 n x i m o d p y=y_{n}=g^{\prod_{i=1}^{n} x_{i}} \bmod p y=yn=g∏i=1nximodp, y y y作为公钥将会被记录到可编辑区块链中作为公共参数。
\qquad 数据管理阶段:分为两个部分,分别是哈希计算和数据编辑。
\qquad 哈希计算的公式是 CHash ( m , r , y , p , g ) = g m y r m o d p \operatorname{CHash}(m, r, y, p, g)=g^{m} y^{r} \bmod p CHash(m,r,y,p,g)=gmyrmodp,为了将数据存储在区块链上,数据首先会以事务的形式进行广播,矿工之后会在事务池当中选取事务,并将这些事务封装成块进行广播,上链之前先利用变色龙哈希进行区块的正确性验证,验证通过后上链。
\qquad 恢复陷门(VerRestore)算法流程如下:1. 第一个陷门持有者将自己的陷门 x 1 x_{1} x1和 f ( x 1 ) f(x_{1}) f(x1)发布到监管区块链上,假设当前陷门片段有误,此时就可以假设 x ’ 1 x’_{1} x’1和 f ( x 1 ′ ) f(x'_{1}) f(x1′)。2.之后就需要计算 y 1 ′ y'_{1} y1′,并和监督区块链上的 y 1 y_{1} y1进行比较,如果 y 1 ≡ y 1 ′ y_{1} \equiv y'_{1} y1≡y1′则说明陷门片段正确可以进行下一步。3.按照公式 y i ′ = g ∏ j = 1 i x j ′ m o d p y_{i}^{\prime}=g \prod_{j=1}^{i} x_{j}^{\prime} \bmod p yi′=g∏j=1ixj′modp进行递推求解验证陷门片段的正确性。4.如果最后的计算结果和 y y y一致,则说明陷门正确,可以恢复到完整的陷门。
\qquad 恢复陷门的备份方法(AltRestore)只会在其中一个陷门片段失效了以后运行,剩下的陷门持有者将先公布自己的正确陷门片段,之后将会利用Shamir密钥恢复的思想恢复陷门 T T T,求解公式是KaTeX parse error: Undefined control sequence: \substack at position 48: …\right) \prod_{\̲s̲u̲b̲s̲t̲a̲c̲k̲{l=1 \\ l \neq …
\qquad 碰撞构造:对于一个新的信息 m ′ m' m′,需要计算一个新的随机数 r ′ r' r′满足 CHash ( r , m , y ) = CHash ( r ′ , m ′ , y ) \operatorname{CHash}(r,m, y)=\operatorname{CHash}\left( r^{\prime},m^{\prime}, y\right) CHash(r,m,y)=CHash(r′,m′,y), r ′ r' r′计算公式是 r ′ = ( m − m ′ + T r ) ⋅ T − 1 m o d q r^{\prime}=\left(m-m^{\prime}+T r\right) \cdot T^{-1} \bmod q r′=(m−m′+Tr)⋅T−1modq,之后将会对 m ′ m' m′和 r ′ r' r′进行广播,对信息 m ′ m' m′和哈希值进行验证,如果哈希值不变且信息 m ′ m' m′符合规范,则可以在区块链上进行修改。
5.安全性分析
\qquad 本方案的安全性来自于两个方面:离散对数问题和对错误陷门的恢复。
\qquad 离散对数问题:如果敌手需要获取陷门片段 x i x_{i} xi,那么敌手需要获得 y i y_{i} yi、 y i − 1 y_{i-1} yi−1和 p p p,根据VerRestore算法,敌手如果只是知道了 y i − 1 y_{i-1} yi−1以前的公钥片段是不足以求解,同理,如果敌手知道了 y i + 1 y_{i+1} yi+1以后的公钥片段,因为这一片段必然包含 y i y_{i} yi,从而也无法进行陷门片段 x i x_{i} xi的求解。即便是直接从监管区块链上获取了 y i y_{i} yi、 y i − 1 y_{i-1} yi−1和 p p p,敌手也会因为计算困难而导致无法获取陷门 x i x_{i} xi。
\qquad 陷门的恢复:通过计算 y i = y i − 1 x i m o d p y_{i}=y_{i-1}^{x_{i}} \bmod p yi=yi−1ximodp即可排查出陷门片段的错误。本文将陷门恢复的情况分为了三类:(1)恶意的陷门持有者 T H i TH_{i} THi提供了错误的陷门片段 ( x i , f ( x i ) ) (x_{i},f(x_{i})) (xi,f(xi))(2)恶意的陷门持有者 T H i TH_{i} THi没有及时提供陷门片段 ( x i , f ( x i ) ) (x_{i},f(x_{i})) (xi,f(xi))(3)恶意的陷门持有者做出了错误的决定。针对第一种情况,错误的陷门片段会被及时发现不会造成严重的危害;针对第二种情况,该陷门持有者被标记为恶意实体并进行陷门修复方法;针对第三种情况,大部分的陷门持有者都是诚实的,个别的错误决定不会影响最终结果。
\qquad 由图可以得知,执行者部分采用了集中式的设计,整个系统只有一个执行者实体,为了防止写入有害数据,陷门片段持有者将会对修改进行验证,如果执行者无法修改数据,那么陷门片段持有者将会拒绝修改数据并更换执行者。
6.实验数据
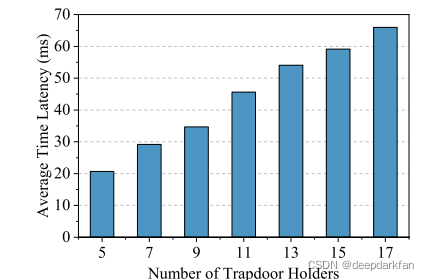
\qquad 随着陷门片段持有者数量的增加,公钥生成时间也会随之增加。
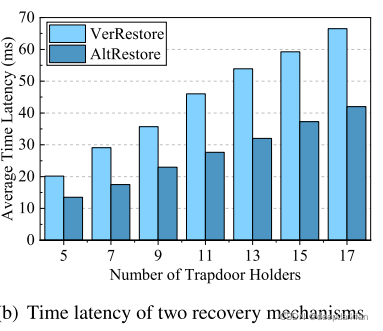
\qquad 两个陷门恢复机制所需时间并不一致,因为在VerRestore的情况下,所有的陷门片段持有者都要参加恢复陷门,而AltRestore因为只需要不超过一半的陷门片段持有者参与,所以后者花费的时间比前者少。

\qquad 而当陷门持有者数量一定时,发现恶意行为的时间会随着恶意陷门片段持有者的数量增加而减少,因为恶意陷门片段持有者比例增加,系统就会更早的触发陷门恢复机制。
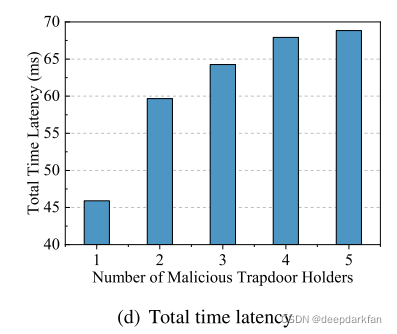
\qquad 随着恶意陷门片段持有者数量增加时,陷门恢复过程有可能无法排除掉所有的恶意陷门片段持有者,因此剩下的陷门片段持有者将会花费更多的时间进行陷门恢复,总时延增加。
7.展望
\qquad 整个方案最大的问题就是效率问题,递推求解完整陷门时间会越来越长,这种递推求解和共识机制没有关系,建议是重新设计算法。其次就是陷门片段持有者的监管问题,需要针对共识机制和声望机制进行改进。