按住 Windows 电脑上的“Win+R”键,会弹出一个“运行”对话框。在里面输入指定路径,就能快速打开相应目标软件或文件。
你可能觉得这是个鸡肋功能——因为想要清楚记住所有软件的完整路径并不简单。
2000 年的北京海淀黄庄,还在读初中的肖涵为了解决这个问题,用 VB 开发了一个软件“smartrun”,实现了用文字和表达式替代命令行的功能。比如在“运行”框内直接输入“扫雷+纸牌”的汉字,便可快速启动软件。高中时肖涵还对 smartrun 用 C# 进行了一次重构升级,然后上传到当时的两大软件门户——PCHOME 和华军软件园,供他人下载。后来,2009 年发布的 Windows 7 通过“系统搜索功能”实现文字快速定位目标的功能,当然这已经是后话了。
这段学生时期的经历为肖涵 20 年后的创业故事埋下了注脚。
2009 年肖涵从北京邮电大学信息工程专业毕业,追随当年父亲的脚步,孤身一人来到德国慕尼黑开始攻读人工智能硕博。2014 年博士毕业后,他移居柏林,在德国的一家上市电商负责开发推荐和搜索系统。2018年,肖涵回到国内,加入腾讯 AI-Lab 实验室,带领团队研发微信中“搜一搜”的搜索系统。
在腾讯时,肖涵还负责了一个基于深度学习的开源搜索框架。在紧锣密鼓研发半年后,该项目由于一些内部原因被搁置了。肖涵思前想后,认为首先“神经搜索”未来一定是非常有前景的;二来如果要做,这件事必须要用开源的方式去做。“当时发现并没有一个公司专门去做开源神经搜索,我觉得这是一个非常好的机会,再加上平时的一些积累,就形成了创业契机。”
2020 年 1 月新冠疫情初现,肖涵没有犹豫,而是选择也在那时离开了腾讯。2020 年 2 月,Jina AI 成立。资本市场也给予了 Jina AI 非常快速且友好的反馈,2021 年 11 月,Jina AI 在美国完成了 3000 万美元 A 轮融资。加上之前的种子轮,Pre A轮融资,Jina AI在短短18个月融资总额达到 3800 万美元,投资方来自于美国,中国和德国。Jina AI 也从肖涵一个人的目标和愿景,变成了来自世界 15 个国家 45 个人的共同目标。今天,Jina AI 在德国柏林,中国北京深圳都设有办公室。
作为软件的 Jina 是一个开源的神经搜索框架,将其与 smartrun 放在一起,就功能本身而言,用户均可以通过更简单的指令输入,从计算机或智能终端获得精准的答案;就软件分发而言,二者都选择了一条能让更多人可用的路径。本期【创造者说】我们邀请肖涵聊了聊他看好神经搜索、选择开源战略的深度原因,以及他和 Jina AI 正在做的事。

Jina AI 两周年 Berlin Office 合照,右四为肖涵
为什么是神经搜索
神经搜索(Neural Search)意指 Deep Learning for Search,是 Jina AI 首次提出的概念,指借助深度学习技术,使用非结构化数据搜索非结构化数据。
在神经搜索中,文字、音频、视频、图片甚至 3D 模型等非结构化数据的搜索问题,都借助深度学习技术,转换成了向量相似性搜索问题。听歌识曲、淘立拍、智能问答机器人等,都是神经搜索的典型应用场景。
Jina AI 曾通过以图搜图来解释神经搜索:将一些猫和狗的图片,按照类别和可爱程度,放在二维向量空间中充当索引,如果希望找到跟某一图片最相近的狗狗,只需要找到这一图片在向量空间中的最近邻。详情可见:https://mp.weixin.qq.com/s/CfpzPDp4__xbbjXGP4vgIg
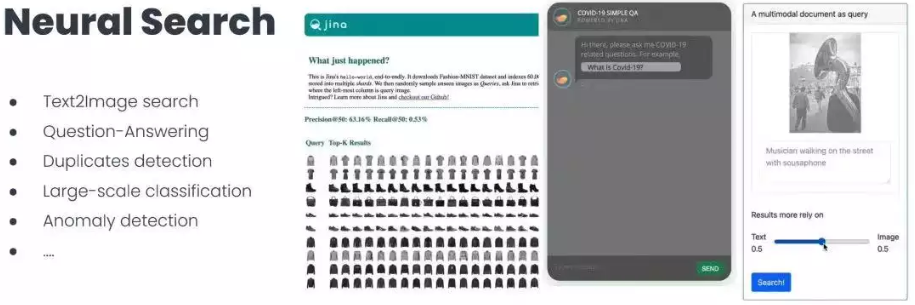
神经搜索系统的应用场景
而之所以锁定在神经搜索领域,在肖涵看来,多模态数据类型的搜素需求已经很多,并且会越来越多,同时,神经搜索的理论基础也已经成熟。这时为开发者提供他们所需要的服务,就变得顺理成章。
真实而巨大的需求
传统的搜索是通过文字去做逐字匹配,对应的场景包括:聊天记录的搜索、文本搜索,公众号文章搜索等等。因此,传统的搜索精于文本,但也仅限于文本。
到了近 5 年,实际上我们已经能感知到,除了文本之外,还有更多的数据模态出现了:比如图片、声音、长视频、短视频、3D 模型,此外元宇宙中其实也出现了许多不同的数据类型。
面对不同的数据类型,传统的文字标签搜索方式已不再适用,图片不可能通过逐个像素分析去匹配,音频也难以切成一秒一秒做搜索。因此,新的数据需要新的搜索方式。
“要理解一个数据类型,首先要让这些数据能被搜索到。如果某种数据类型特别大,但搜都搜不到的话,如何去构建更高级的智能?”在肖涵眼中,现在大家在谈的数据智能、数据分析等等往往是更高级的应用,而最底层的能力往往是可以准确地定位数据,“只有在最基本的需求能够完成的情况下,才有精力去构建更高级的数据智能。”
Jina AI 对于图像、音频、视频或其他内容,首先使用深度神经网络将数据格式转换为通用表达。在这种情况下,它们主要是一个数学向量(100 维向量)。之后匹配算法不计算有多少字母匹配,而是计算数学距离,也就是这两个向量之间的向量距离。通过这种方式,人们基本上可以解决各种数据搜索问题或相关性问题。
理论支撑
“近 5 年,深度学习已经成为主流,大家会认为,深度学习是一个比较完善的方法论了。并且在深度学习中,有两个细分领域,一个是表征学习,另一个是迁移学习,对深度学习工程领域有非常深刻的影响。在这种情况下,构建一个完全基于深度学习的搜索系统,就成为了可能。”
肖涵所提到的表征学习,是一种将原始数据转换成为更容易被机器学习应用的数据的过程。目的是对复杂的原始数据化繁为简,把原始数据提炼成更好的数据表达,使后续的任务事半功倍。迁移学习(Transfer Learning)是指一种学习对另一种学习的影响,或习得的经验对完成其他活动的影响。
这两大框架的发展,使得从头开始训练变得不是那么必须。
传统的深度学习拿到数据之后,需要为数据贴标签,从头开始训练。但是表征学习认为可以跳过这一步,从一个已经训练好了的,比如上一个任务的一个模型作为初始点,然后再进行微调,这实际上是将传统的端到端的学习分成了“预训练+微调”两个部分。
预训练需要大量数据,比如需要学习语言中的特征,词语在句中的顺序,基本的语法结构等等,通过这些就能得到一个关于中文的语言模型,这种语言模型一般无法直接拿来做分类问题,其性能也不是最优的。但是提供了很好的微调的基础。使得很多中小企业,在不需要太多数据的情况下,在预训练模型上进行微调就能实现很好的性能。
“所以我觉得机器学习在某种意义上,已经实现了科技平权。”深度学习发展到今天,从头开始做一个模型的成本不仅仅包括电费、GPU 这种计算成本,人力成本也非常之高,还有时间成本等等。过去只有大厂才有这样的经济实力与耐心,而中小企业无法享受深度学习发展带来的红利。“但迁移学习是你只要拥有一个模型,就能实现像大厂一样的性能。并且,由于中小厂商对自己的商业问题理解更加深入,那么对于自身数据的采集和把控肯定也会更好,这也就在微调这一步提供了很大的优势。”
而在需求爆发与理论充足的两个大背景下,Jina AI 正在做的事情,是面向开发者封装出更易用的神经搜索框架。

从左至右分别是 Jina AI CTO 王楠、CEO 肖涵、COO 何烜彬
面向开发者而不是 C 端用户
虽然深度学习理论的成熟让神经搜索成为可能,但大多数的开发者想要实现一个“以图搜图”之类的功能都需要一定时间,甚至至今也无法实现。原因便是现有的技术框架、能力不够完善,同时搭建一个神经搜索系统非常耗时。
肖涵举了个“查找替换”的例子,每个 APP 中都有查找功能,因为这个功能被封装的非常好,可以非常方便地引入到开发者的软件中,所以 Jina AI 要做的事情也是一样——让神经搜索和今天的“查找”功能一样普遍。
“在开发者需要我们的时候,我们已经把整个技术栈准备好了,开发者可以非常方便地使用这个神经搜索系统对其软件进行赋能。”
Jina AI 首先面向的是开发者。神经搜索的应用入口一定不局限于“文本框”内,比如现在淘宝所使用的以图搜图,其入口可能会是摄像头;小爱同学的输入则是语音,在用户说出“今天天气如何”、“今天冷不冷”、“今天热不热”这三句话时,结果会映射到同一个关于天气的回答上,其背后也是神经搜索。而这种人机交互同样也能看成是一个“搜索框”,通过语音实现的智能问答。
“所以真正的神经搜索是一个非常底层的基础技术,一旦底层技术实现,那么高层的数据智能可以实现,最终极大的丰富 C 端场景。”在肖涵看来,如果 Jina AI 去做 C 端,就会变得非常繁杂,因为 C 端的应用场景太多了,智能音箱、家用电器等等,还可能是特定行业,那么这些场景下的数据集和数据匹配的文件类型都不一样。
但反观赋能企业中的开发者这个方向,由于不是所有公司都是互联网公司,也并不是所有公司都能从头实现自己的神经搜索系统。“帮助企业快速搭建起,不管是基于神经搜索的一套完整解决方案,还是在客户的解决方案/商业模式上去增加神经搜索功能,就是我们要做的事情。”
当下:长文本问答与图片搜索
Jina AI 目前主要客户来自欧洲与国内的一些中小型企业,包括法律文书、电商、游戏平台等,应用的两个主要场景是长文本问答和图片搜索。
第一个是长文本的问答型搜索。比如一份长达 30 页的租房合同,想快速知道一些关键性问题,比如房租多少、需提前多久退房等等。此类问题的解答基于传统的搜索是无法实现的,因为传统搜索是基于关键词匹配,面对许多具体而灵活的问题时就无法直接回答。
长文本问答型的场景还包括洗衣机说明保养、法律文书等等。“对于一个不是法律出身的 C 端用户,想要去理解一段法律文本很难,传统的搜索是做不到的,只会匹配到晦涩难懂的词句上,但是神经搜索可以充分理解语义的内容,相对来说匹配的答案就会更加清晰。”
第二种是图片搜索。图片搜索已经存在了一段时间,但当下强调的往往是更高质量、更精细力度的以图搜图,而不是传统意义上给一张图片就直接搜,现在可以搜索一张图片上的局部,或是只关注背景,又或者前景更加细微化等等的搜索,这也是传统意义上的搜索做不到的。
此外,暂且抛开上面提到的视频数据所有权问题,视频本身毫无疑问已经是人们在互联网上娱乐消费的主要载体。同时,随着人人都在拍短视频,做博主,就会需要建素材,找素材,这时便可以用上神经搜索,比如对于一段已经拍摄好的海浪的场景,系统可以自动从音乐库中找到符合该场景的音乐,这便是基于视频的神经搜索业务场景。
为什么是开源
对于肖涵和 Jina 来说,开源的意义首先是让更多的开发者来使用 Jina。
这与《大教堂与集市》中所论及的开源的最核心价值——“让更多人为软件做贡献”有所不同。Jina 的贡献门槛不低,因此其贡献者也很难大规模增长。而肖涵更关心的则是贡献者的质量,以及通过开源,Jina 是否能成为行业标准。

肖涵
贡献者的量与质
肖涵认为,无论是数据库还是搜索、或者 AI 框架,许多开源软件都是基础软件,并不是每个人都有能力在基础软件中做贡献。如果一昧强调大家要来做贡献,或者社区运营的大目标是拉新贡献者,相对来说结果是会让人失望的。
从开源贡献者角度来说,软件做得越难,贡献者可能就越少,但这往往也意味着,真正能来做贡献者的人,水平是比较高的,同时对软件也是比较认可的,相对来说他所做贡献的质量就越高。
“所以我们看贡献者,更多的是强调质量而非数量。”实际上,单纯为提高贡献者数量也可以将软件从底层设计到上层 API 用文档的形式都解释清楚,那么很多开发者既可以参与进来在,找出错别字,API 中没有写全的注释等等,实现参与和贡献,但这并非是 Jina AI 目前所看重的。
他们看重的是:涉及到软件本身底层的一些逻辑和关键性能,是否能够让社区参与进来去做贡献。“这考验的是开源公司、开源社区能不能把社区吃透。”肖涵认为,一个非常重要的点就是你的开源贡献者究竟是浮在表面,还是深入核心。如果能深入到核心,那说明这个开源软件确实做的不错。
Jina AI 现在在全球的社区总共将近 3000 人,其中有两百多人为生态中的某个产品作过贡献,整体比例不到 10%。“而且这 10% 中,我们还招了不少人,可能我们发现你确实写的不错,那干脆就直接来给我们做吧。”所以,真正游离在外的核心贡献者可能不到 1%。
“这个比例也说明了,做开源软件,项目本身是简单的,是相对纯粹的工程问题,但是开源软件往大了说,是一个社会性问题。”

Beijing Office 三亚团建
软件开源本质——将工程产出社交化
“我常常说,开源软件实际上是在解决好工程能力的同时,用工程产出去进行社交化。去与人构建合作、构建关系、去做软件 API。”肖涵对于开源软件的看法也决定了 Jina AI 在社区方面的发展目标——让所有 API 的接口都向它对齐,让 Jina AI 成为行业规范。
如果一个开源软件没人用,毫无疑问它是不成功的。如果别人用了,而且基于这个软件封装构建了更高级的软件,那么这个开源软件的价值就体现出来了。再进一步,如果别人的软件为了这个软件更改自己的接口,那么其社会价值便体现出来了。此时,这款开源软件便成了非常核心的软件,所有的 API 接口都会向其看齐,与之配合,实现社区中的互通。
“成为通用的搜索方式,我们目前做的还不错。”诞生初期,Jina AI 只推出了一个产品,之后逐渐增加了底层的数据结构等产品,而所有产品之间是相互依赖的。在 Jina AI 内部,从底层设施,到云上增值体验,已经形成了相较完整的体系,“Jina 从一个大而全的东西,变成现在一个小而精的入口,一扇门,通过这扇门,你可以打开神经搜索的整个生态。”
Jina AI 提供了一个涵盖整个开发过程的端到端开源技术栈,这就是神经搜索生态。

Jina AI 神经搜索技术栈
目前已有 DocArray, Jina, Finetuner, CLIP-as-service 等 7 个产品
DocArray 是创建神经搜索项目的第一步。 它将非结构化数据,统一成同一种数据结构,利用 Python API,开发者可以高效地处理、向量化、搜索、推荐、存储及传输数据。
Jina 是生态中最早的产品,诞生于 2020 年。它是一个云原生神经搜索框架,可以把本地 DocArray 程序升级为一个高度可扩展的云服务,允许用户通过 gRPC、HTTP 或 WebSockets 访问。
Finetuner 可以借助特定领域的数据,进一步微调模型,以获得更高的准确率,更好地应用于搜索任务。
CLIP-as-service 利用 CLIP 模型,可以将图像和句子嵌入固定长度的向量中,开发者可以在构建新的搜索解决方案时,将其作为向量化服务,或者在用 Jina 在生产中构建服务时,简单地将其作为最佳实践。
此外 Jina AI 的神经搜索生态中,还包括组件分享平台 Hub,命令行界面 JCloud,以及一行代码解决文本到图像搜索问题的 Jina Now。
目前,Jina AI 已经和多家公司达成合作,覆盖元宇宙、游戏、电商、法律服务、家装等行业,也有许多工程师为适配 Jina AI 的系统做了 API 的设计融合。
而在开源的过程中,Jina AI 也在更加贴近开发者,从 1.0 到 2.0 迭代之时,肖涵和他的团队赢来了一次“胜利”。
2021 年 1 月,Jina AI 1.0 版本上线,同年 6 月就“赶紧推出了 2.0”。原因便在于 1.0 时期肖涵团队接到很多反馈称软件太难用了,于是 2.0 对整个高层的 API 进行了重新定制与优化,因此 2.0 实现了爆发式的增长,Jina 多次登上 GitHub 全球 Trending 排行榜第一名。“所以我们当时意识到软件,不管是底层还是高层,应用性是非常重要的。”
结语
今年 2 月,Jina 发布了 3.0 版本,在云计算准备和云集成方面,有了显著提升,用户可以更轻松地完成项目从本地到云端生产环境的迁移。“再往后,我们大概不会以版本号作为里程碑了,因为从今年开始,更多的是强调生态,包括它的专业度和稳定性。
在商业化公司中,如何通过开源项目赚钱,是绕不开的问题。企业版标品+云上增值订阅服务似乎已经成了一套标准化的答案。开源之后,公司便会失去传统意义上的技术壁垒。开源软件往往的模式是,底层基建+云上增值。将所有增值服务构建在云上,比如托管,或者是数据审核、保护、分析。
Jina AI 目前则是在侧重推行标准化服务的阶段,“如果一年前一家公司找过来,我们可能需要一个月的时间完成定制,但是现在一家公司找过来,我们可能只需要一周或者几天的时间去定制。并不是因为我们人手变多了,而是整个基础设施变强大了,更通用了,那么新来一个项目,研发它的边际成本就会降低。”
在肖涵的认知中,B 轮之前探索出适合自己的商业模式,也是 Jina AI 下一阶段的重要任务。而值得庆贺的是,目前 Jina AI 已完成 A 轮融资,融资总额已经超过 2 亿人民币,这不仅仅代表了投资人对 Jina AI 的看好,同时也是对开源创企的看好。
2022 年,Jina AI 团队仍在持续扩张,算法工程师、前端工程师、Python 工程师等众多岗位虚位以待,加入 Jina AI,与来自世界各地的工程师交流思想碰撞灵感,Work Hard Play Harder,共同打造下一代开源神经搜索框架。
更多岗位详情,请访问:
【创造者说】
OSCHINA 推出全新开源创企访谈栏目【创造者说】。
开源社区需要创造者,他可以是个人,也可以是由个人组成的公司。开源软件发展 20 余年,来自公司的开源贡献者已经成为中坚力量,更是有一批公司围绕开源软件而创办。本栏目将聚焦开源创企和他们的创始人,探讨当下的开源现状,分享开源商业故事,为开源社区添砖加瓦。
【创造者说】专栏面向所有开源创企,欢迎填写下方问卷,向我们推荐那些有创造力的公司:
https://www.wjx.cn/vj/P2FFev2.aspx
往期回顾:
张亮:为发展 ShardingSphere 创办 SphereEx,看好云上订阅制