YOLO(you look only once)是检测PascalVOC2007/2012数据集内对象/目标的系统,能够检测出20种Pascal对象,是一个准确率较高,速度较快的实时图像检测方法。
(20种对象:人 动物 交通工具 静物)
原文翻译:http://www.jianshu.com/p/ebce76db119b
YOLO9000即YOLOv2 是新版本的YOLO,据称 mAP 和速度都提升了不少,更是可以检测9000多种物体,且不要求同样的分辨率。(mAP:mean average precision衡量识别精度,多个类别物体检测中,每一个类别都可以根据recall和precision绘制一条曲线,AP就是该曲线下的面积,mAP是多个类别AP的平均值)
官网;https://pjreddie.com/darknet/yolo/
yolo代码:https://github.com/gliese581gg/YOLO_tensorflow
YOLO使用工具:
-
DarkNet:开源的神经网络框架,使用C语言和CUDA编写,安装快速简单,支持CPU/GPU计算。https://pjreddie.com/darknet/
-
PascalVOC为图像识别和分类提供了一整套标准化数据集,2005-2012每年举行一场图像识别challenge。YOLO测试中用到VOC 2007/2012.
VOC数据集的介绍:http://blog.csdn.net/zhangjunbob/article/details/52769381
YOLO相关算法:RCNN,fast/faster-RCNN,SSD http://nooverfit.com/wp/2017/07/
-
RCNN系列:region proposal+CNN
-
传统方法:区域选择(设置不同尺度滑动窗口对整幅图像进行遍历,对目标位置进行定位)—>特征提取(手工设计的特征eg:HOG,SIFT)—>分类(使用训练好的分类器进行分类,常用SVM,Adaboost)
-
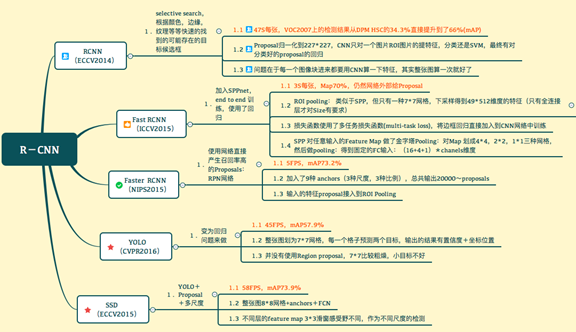
R-CNN:区域选择(对测试图像利用选择搜索算法提取2000个候选区)—>缩放(将候选区缩放成227*227大小输入CNN,fc7层输出为特征)—>分类(将CNN提取到的特征输入SVM分类)—>边框回归
-
Fast R-CNN: 在RCNN基础上改进:在最后一层卷积层上加一个ROI pooling;使用多任务损失函数;将边框回归加入CNN中训练
-
Faster R-CNN : 使用RPN(卷积神经网络直接产生候选区域)
-
-
基于回归方法:
-
YOLO(实时性高,但没有了region proposal机制目标不能精准定位,检测精度不是很高),v2版本应该提高了…
-
SSD:结合了YOLO中的回归思想和Faster R-CNN中的anchor机制,使用全图各个位置的多尺度区域特征进行回归,同时保证了实时性与精度。
-
YOLO算法:
-
Resize:成448*448,图片分割成7*7网格
-
CNN提取特征及预测:
YOLO检测网络包括24个卷积层和2个全连接层,其中,卷积层用来提取图像特征,全连接层用来预测图像位置(7*7*2=98个bounding box的坐标x,y,w,h,confidence)和类别概率值(7*7=49个网格所属20个物体的概率)。
3.过滤bbox(通过nms)
图解YOLO:https://zhuanlan.zhihu.com/p/24916786?refer=xiaoleimlnote
问题:
-
YOLO基于VOC给定的20种分类,如何实现自己的目标识别呢?
-
若每个格子中包含多个物体时仅能检测出一个?