一. 明确几个概念:
1. 目标分割(Target Segmentation):任务是把目标对应部分分割出来。
像素级的前景与背景的分类问题,将背景剔除。
举例:(以对视频中的小明同学进行跟踪为例,列举处理过程)
第一步进行目标分割,采集第一帧视频图像,因为人脸部的肤色偏黄,因此可以通过颜色特征将人脸与背景分割出来。
2. 目标检测(Target Detection):
定位目标,确定目标位置和大小。检测目标的有无。
检测有明确目的性,需要检测什么就去获取样本,然后训练得到模型,最后直接去图像上进行匹配,其实也是识别的过程。
举例:第二步进行目标识别,分割出来后的图像有可能不仅仅包含人脸,可能还有部分环境中颜色也偏黄的物体,此时可以通过一定的形状特征将图像中所有的人脸准确找出来,确定其位置及范围。
3.目标识别(Target Recognition):定性目标,确定目标的具体模式(类别)。
举例:第三步进行目标识别,将图像中的所有人脸与小明的人脸特征进行对比,找到匹配度最好的,从而确定哪个是小明。
4.目标跟踪(Target Tracking):追踪目标运动轨迹。
举例:第四步进行目标跟踪,之后的每一帧就不需要像第一帧那样在全图中对小明进行检测,而是可以根据小明的运动轨迹建立运动模型,通过模型对下一帧小明的位置进行预测,从而提升跟踪的效率。
二. 目标识别
参考博客; http://blog.csdn.net/liuheng0111/article/details/52348874
(一)目标识别的任务:
识别出图像中有什么物体,并报告出这个物体在图像表示的场景中的位置和方向。对一个给定的图片进行目标识别,首先要判断目标有没有,如果目标没有,则检测和识别结束,如果有目标,就要进一步判断有几个目标,目标分别所在的位置,然后对目标进行分割,判断哪些像素点属于该目标。
(二)目标识别的过程:
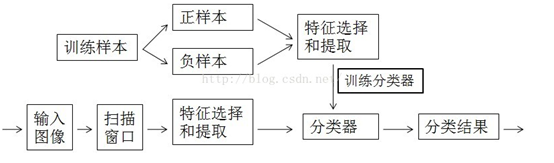
1. 目标识别框架
目标识别往包含以下几个阶段:预处理,特征提取,特征选择,建模,匹配,定位。目前物体识别方法可以归为两类:一类是基于模型的或者基于上下文识别的方法,另一类是二维物体识别或者三维物体识别方法。对于物体识别方法的评价标准,Grimson总结出了大多数研究者主要认可的4个标准:健壮性(robustness)、正确性(correctness)、效率(efficiency)和范围(scope)。
2. 训练样本的创建
训练样本包括正样本和负样本;其中正例样本是指待检目标样本(例如人脸或汽车等),负样本指其它不包含目标的任意图片(如背景等),所有的样本图片都被归一化为同样的尺寸大小(例如,20x20)。
3. 预处理
预处理通常包括五种基本运算:
(1)编码:实现模式的有效描述,适合计算机运算。
(2)阀值或者滤波运算:按需要选出某些函数,抑制另一些。
(3)模式改善:排除或修正模式中的错误,或不必要的函数值。
(4)正规化:使某些参数值适应标准值,或标准值域。
(5)离散模式运算:离散模式处理中的特殊运算。
4.特征提取
一般我们把原始数据组成的空间叫测量空间,把分类识别赖以进行的空间叫做特征空间,通过变换,可把在维数较高的测量空间中表示的模式变为在维数较低的特征空间中表示的模式。特征提取是物体识别的第一步,也是识别方法的一个重要组成部分,好的图像特征使得不同的物体对象在高维特征空间中有着较好的分离性,从而能够有效地减轻识别算法后续步骤的负担,达到事半功倍的效果,下面是对一些常用的特征提取方法:
(1)颜色特征。颜色特征描述了图像或图像区域所对应的景物的表面性质,常用的颜色特征有图像片特征、颜色通道直方图特征等。
(2)纹理特征。纹理通常定义为图像的某种局部性质,或是对局部区域中像素之间关系的一种度量。纹理特征提取的一种有效方法是以灰度级的空间相关矩阵即共生矩阵为基础的,其他方法还有基于图像友度差值直方图的特征提取和基于图像灰度共生矩阵的特征提取。
(3)形状特征。形状是刻画物体的基本特征之一,用形状特征区别物体非常直观,利用形状特征检索图像可以提高检索的准确性和效率,形状特征分析在模式识别和视觉检测中具有重要的作用。通常情况下,形状特征有两类表示方法,一类是形状轮廓特征描述,另一类是形状区域特征。形状轮廓特征主要有:直线段描述、样条拟合曲线、博立叶描述子、内角直方图以及高斯参数曲线等等,形状区域特征主要有:形状的无关矩、区域的面积、形状的纵横比等。
(4)空间特征。空间特征是指图像中分割出来的多个目标之间的相互的空间位置或者相对方向关系,有相对位置信息,比如上下左右,也有绝对位置信息,常用的提取空间特征的方法的基本思想为对图像进行分割后,提取出特征后,对这些特征建立索引。
目标比较盛行的有:Haar特征、LBP特征、HOG特征和Shif特征等;他们各有千秋,得视你要检测的目标情况而定。
5.特征选择(可选步骤)
6.建模
7.训练分类器
训练分类器可以理解为分类器(大脑)通过对正样本和负样本的观察(学习),使其具有对该目标的检测能力(未来遇到该目标能认出来)。
8.匹配
在得到训练结果之后(在描述、生成或者区分模型中常表现为一簇参数的取值,在其它模型中表现为一组特征的获得与存储),接下来的任务是运用目前的模型去识别新的图像属于哪一类物体,并且有可能的话,给出边界,将物体与图像的其它部分分割开。一般当模型取定后,匹配算法也就自然而然地出现。在描述模型中,通常是对每类物体建模,然后使用极大似然或是贝叶斯推理得到类别信息;生成模型大致与此相同,只是通常要先估出隐变量的值,或者将隐变量积分,这一步往往导致极大的计算负荷;区分模型则更为简单,将特征取值代入分类器即得结果。
一般匹配过程是这样的:用一个扫描子窗口在待检测的图像中不断的移位滑动,子窗口每到一个位置,就会计算出该区域的特征,然后用我们训练好的分类器对该特征进行筛选,判定该区域是否为目标。然后因为目标在图像的大小可能和你训练分类器时使用的样本图片大小不一样,所以就需要对这个扫描的子窗口变大或者变小(或者将图像变小),再在图像中滑动,再匹配一遍。
9.目标识别
物体识别方法就是使用各种匹配算法,根据从图像已提取出的特征,寻找出与物体模型库中最佳的匹配,它的输入为图像与要识别物体的模型库,输出为物体的名称、姿态、位置等等。
三.利用TensorFlow进行目标识别
目标:利用TensorFlow基于ImageNet数据库的一个子集构建一个用于图像分类的CNN模型。训练CNN模型需要使用TensorFlow处理图像并理解卷积神经网络的使用方法。
使用Stanford's Dogs Dataset(ImageNet的一个子集),数据集包括不同品种的狗的图像及其品种标签。建模目标是给定一幅图像时可以精确预测其中包含的狗的品种。
卷积神经网络(CNN):适用于稠密的输入,输入分量大部分非0
滤波器/卷积核 (训练目标是调节这些卷积核的权值,直到与训练数据精确匹配)
CNN架构:图像输入(image_batch)——卷积层(tf.nn.conv2d)——修正线性单元/激活函数(tf.nn.relu)——池化层(tf.nn.max_pool)——全连接层(tf.matmul(x,W)+b)
激活函数为神经网络引入非线性,能对更复杂的模式进行描述。
池化层可减少过拟合,并通过减小输入的尺寸提高性能,对输入降采样。
卷积
输入与卷积核(kernel):
输入向量格式 [image_size,image_height,image_width,image_channels]
跨度(strides):
卷积核跳过输入中的一些固定数目的元素,降低输出的维数。Strides参数的格式与输入向量相同。
边界填充(paddiing=SAME或VALID):卷积核与图像尺寸不匹配时零填充或错误状态
补充:循环神经网络(RNN)