前言:又到了学校一年一度的数据结构课设的日子,经不住学弟学妹热心地“询问”我数据结构课设的内容,我就在这里把我之前数据结构课设做的东西总结一下
哈夫曼编译码器
我课设选择的题目是哈夫曼编译码器,类似于我们平时用的解压缩软件,可以把大文件压缩成一个较小的文件。
设计目的
数据结构课程设计的主要目的是使学生通过系统分析、系统设计、编程调试、写实验报告等环节,进一步掌握应用系统设计的方法和步骤,灵活运用并深刻理解典型数据结构在软件开发中的应用,进一步提高分析问题和解决问题的能力,提高程序设计水平。
设计内容
哈夫曼编译码器
利用哈夫曼编码进行信息通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本,编写代码实现一个哈夫曼的编/译码器,要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(复原)。
具体功能包括:
- 建立哈夫曼树:读入文件(xxx.souce),统计文件中字符出现的频度,并以这些字符的频度作为权值,建立哈夫曼树。
- 编码:利用已建立好的哈夫曼树,获得各个字符的哈夫曼编码,并对正文进行编码,然后输出编码结果,并存入文件(xxx.code)中。
- 译码:利用已建立好的哈夫曼树将文件( xxx.code)中的代码进行译码,并输出译码结果,并存入文件( xxx.decode)中。
- 利用位操作,实现文件的压缩与解压。(选作)
概要设计
压缩解压缩界面:
这是一个使用JavaFx编写的一个简单的图形界面,可以进行压缩和解压缩文件的选择,选择完即可对被选择的文件进行压缩或解压缩。
压缩功能
压缩功能是按照文件里面的各个元素按照权值(即元素出现的次数)形成哈夫曼树,再通过遍历形成的哈夫曼树形成哈夫曼编码,再对形成的哈夫曼编码进行按位压缩(即每8位形成一个字节),最后将按位压缩后的编码、哈夫曼树的元素以及这些元素对应的权值和该文件的名字格式写入压缩文件里面方便进行下一次解压缩操作。
解压缩功能
解压缩功能流程跟压缩的流程差不多,同样是读取文件,将压缩时存进文件里面的信息读取出来,首先根据读取到字节数组重新恢复哈夫曼编码,然后根据读取到的哈夫曼树的信息重新创建哈夫曼树,再遍历哈夫曼树重新形成哈夫曼编码集合,遍历哈夫曼编码重新形成字符数组,根据字符数组恢复原来的字节数组,最后使用得出的字节数组恢复原来的文件即可得到压缩前的文件。
功能模块图

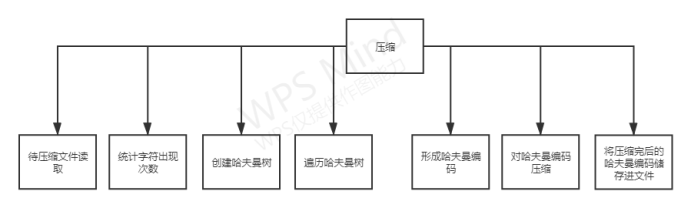
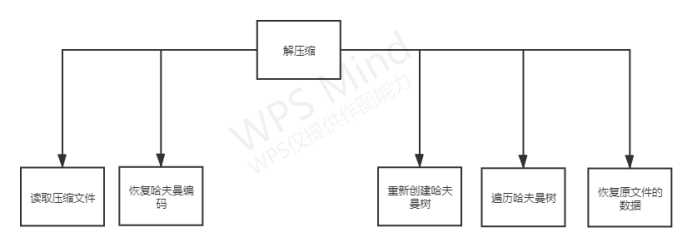
各个模块详细的功能描述
压缩
待压缩文件读取:
读取选取的待压缩文件,并将里面的数据用字节数组转化为字符数组,最后返回该字符数组;
统计字符出现的次数:
统计文件读取出来字符数组里面各个字符出现的次数,将他们储存在Map集合里面;
创建哈夫曼树:
根据统计出来字符次数的集合来创建哈夫曼树;
遍历哈夫曼树:
创建完哈夫曼树之后将哈夫曼树遍历得到各个叶子节点的编码,并将这些编码储存到集合里面;
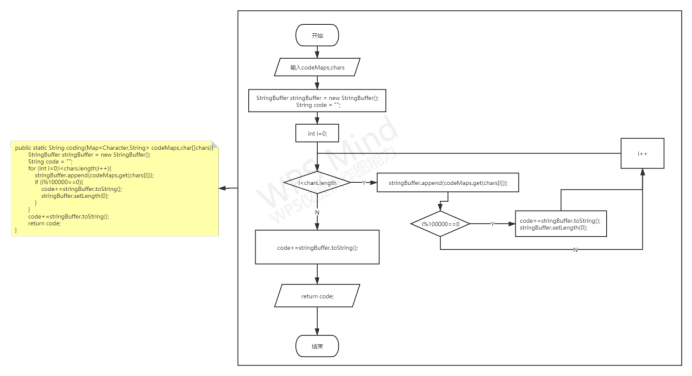
形成哈夫曼编码:
根据叶子节点的编码遍历字符数组得到哈夫曼编码,并返回编码字符串;
对哈夫曼编码压缩:
将哈夫曼编码字符串按位压缩成字节数组,并返回该字节数组;
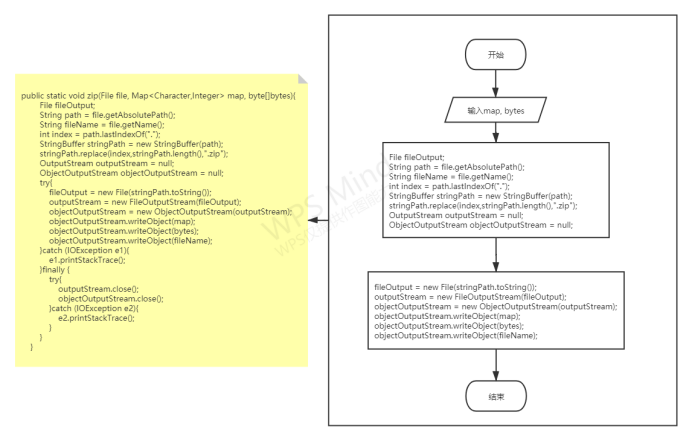
将压缩完的哈夫曼编码存进文件:
将哈夫曼编码压缩完后返回的字节数组给储存进压缩文件里面;
解压缩
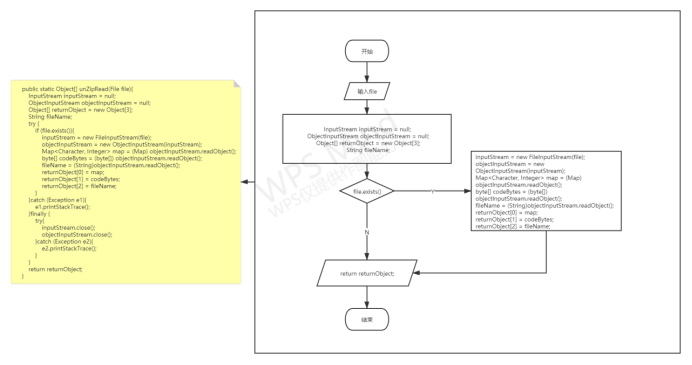
读取压缩文件:
读取待解压缩的文件,将哈夫曼树、哈夫曼编码字节数组、原文件名和格式返回;
恢复哈夫曼编码:
对读取到的哈夫曼编码的字节数组重新转为字符串,即将字节重新恢复成二进制字符串;
重新创建哈夫曼树:
根据读取到的哈夫曼树的叶子和权值信息重新创建哈夫曼树;
遍历哈夫曼树:
遍历哈夫曼树得到叶子的编码,然后根据哈夫曼编码字符串遍历,获得原来的字符数组,再将支付数组转为字节数组返回;
恢复原文件数据:
根据返回的字节数组和之前读取到的原文件的格式和名字,重新创建文件,并往里面写入信息来恢复原来的文件信息。
详细设计
功能函数的调用关系
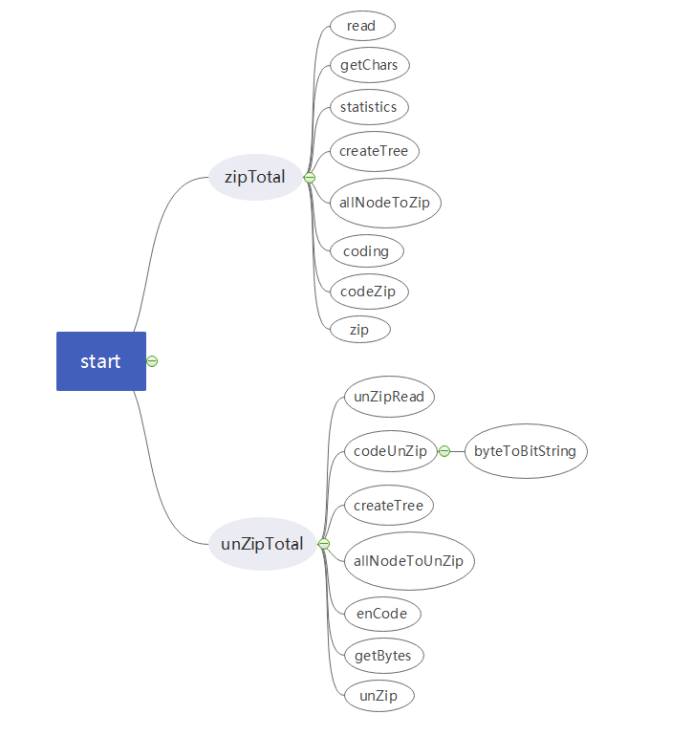
各功能函数的数据流程图
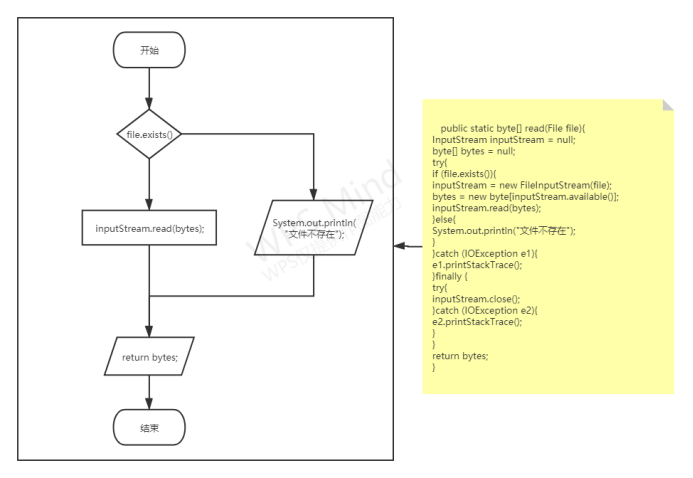
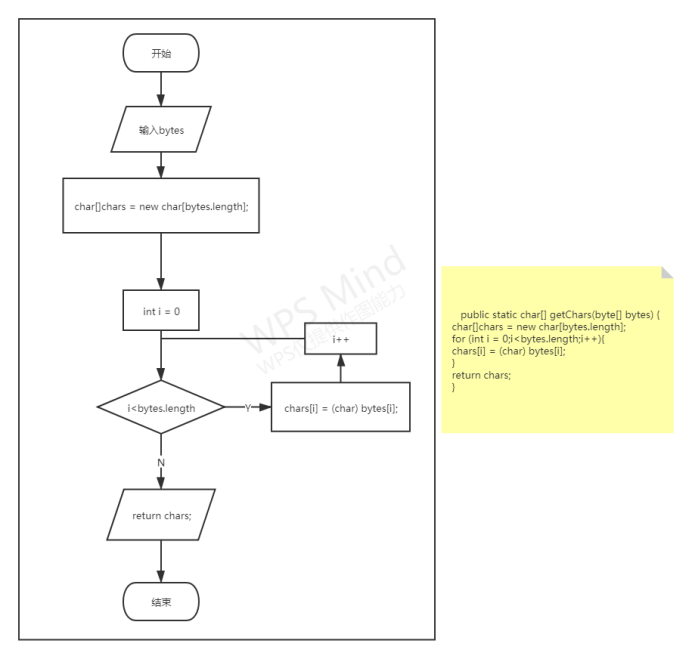
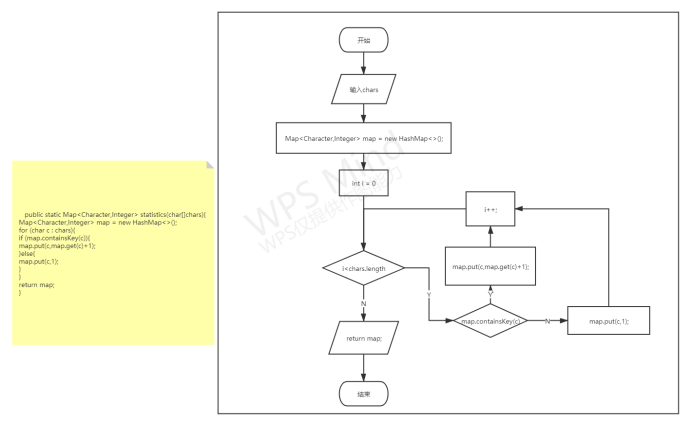
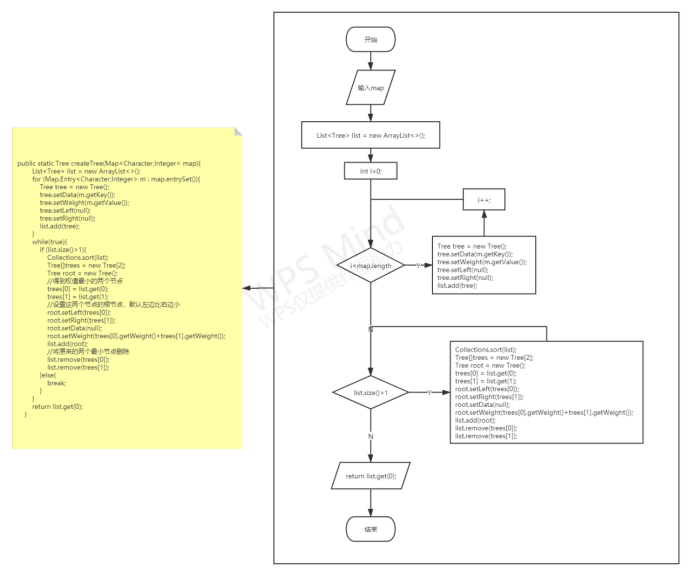
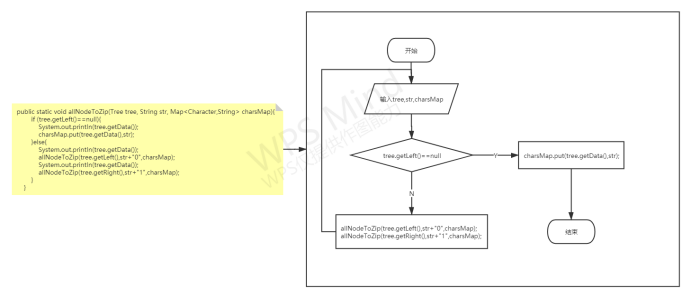

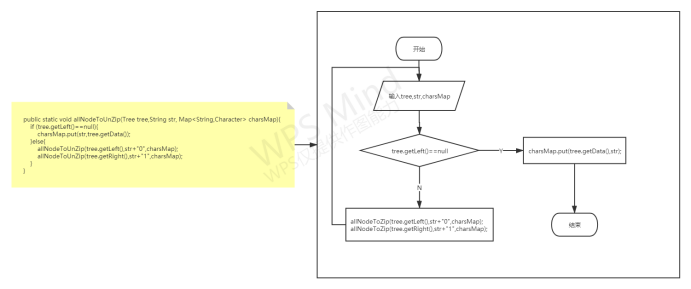
重点设计及编码
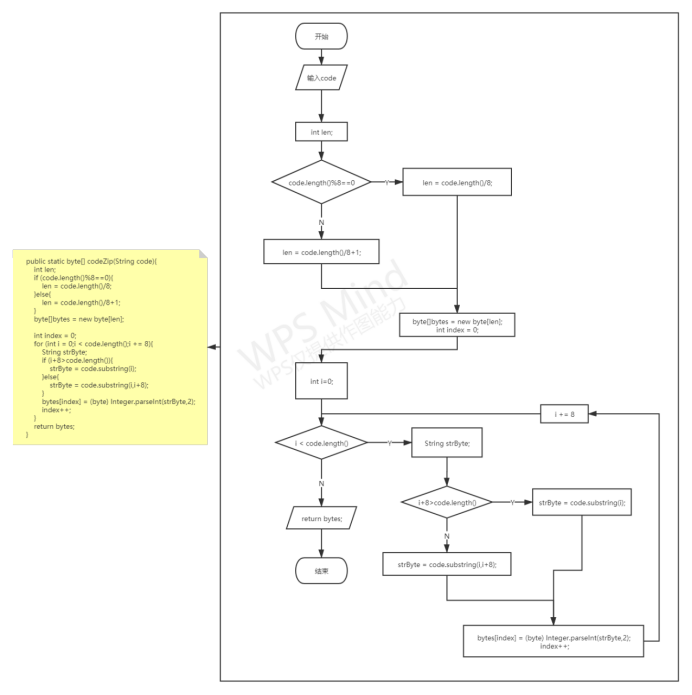
将哈夫曼编码按位进行压缩的操作
public static byte[] codeZip(String code){
int len;
if (code.length()%8==0){
len = code.length()/8;
}else{
len = code.length()/8+1;
}
byte[]bytes = new byte[len];
int index = 0;
for (int i = 0;i < code.length();i += 8){
String strByte;
if (i+8>code.length()){
strByte = code.substring(i);
}else{
strByte = code.substring(i,i+8);
}
//Integer.parseInt(strByte, 2)方法的作用是输出二进制strByte数变成十进制后的数
//如:1010变为十进制后为10
bytes[index] = (byte) Integer.parseInt(strByte,2);
index++;
}
return bytes;
}
对哈夫曼编码重新恢复成字符数组的操作
public static char[] enCode(String code, Map<String,Character> map){
List<Character> list = new ArrayList<>();
for(int i = 0; i < code.length(); ) {
int count = 1;
boolean flag = true;
Character b = null;
String key = null;
while(flag) {
if (i+count<=code.length()){
key = code.substring(i, i + count);
}else{
//如果到了结尾而且key还找不到匹配的值,就对key进行补零的操作
key="0"+key;
System.out.println(key);
}
b = map.get(key);
if (b == null) {
++count;
} else {
flag = false;
}
}
list.add(b);
i+=count;
}
char[]chars = new char[list.size()];
for (int i=0;i<chars.length;i++){
chars[i] = list.get(i);
}
return chars;
}
测试数据及运行结果
正常测试数据和运行结果
解压缩txt文件
压缩前:
压缩完:

解压后:
控制台输出:
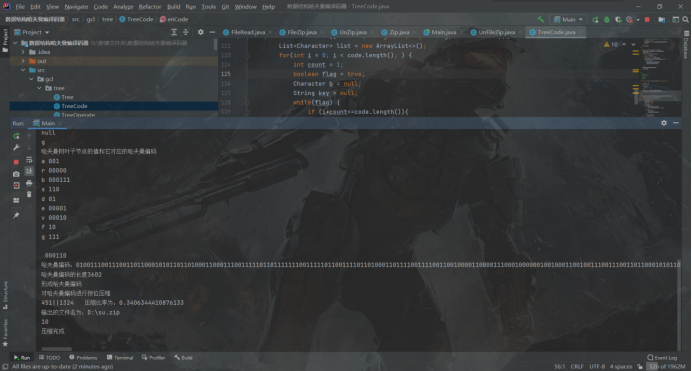
输出哈夫曼树节点信息、哈夫曼编码、哈夫曼编码长度、压缩比率等
解压缩mp4文件
解压前:
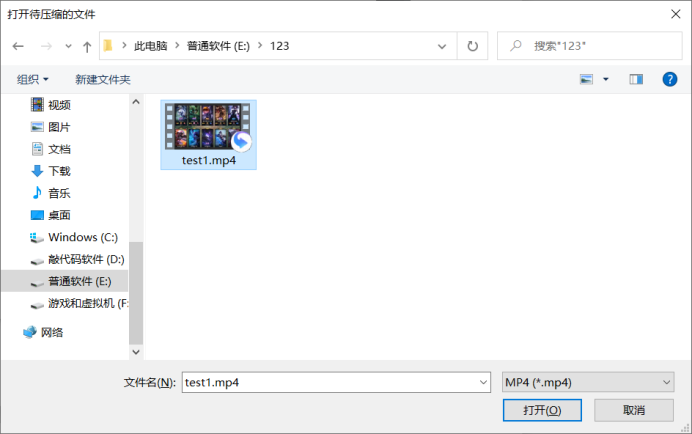
压缩后:
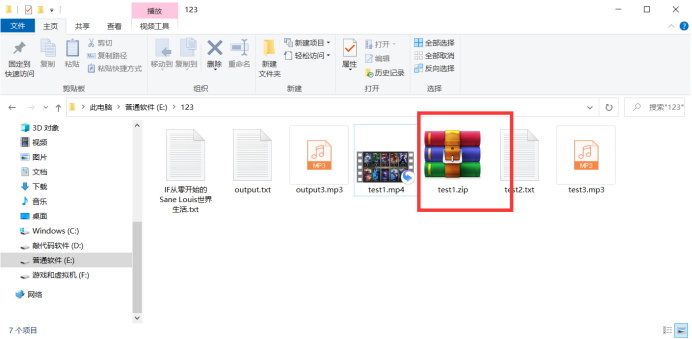
解压后:
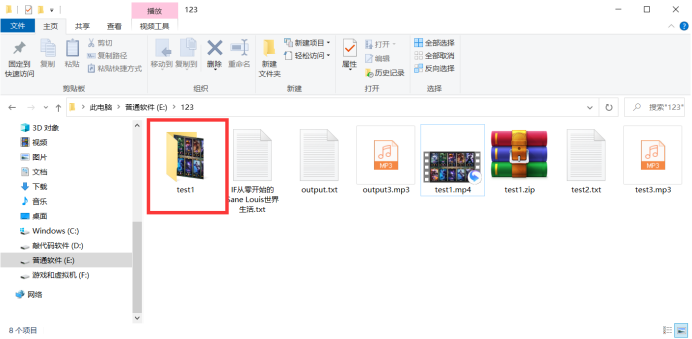
控制台输出:
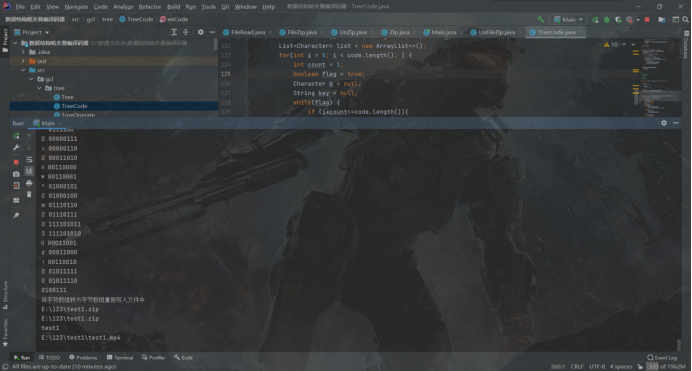
输出哈夫曼树节点信息、哈夫曼编码、哈夫曼编码长度、压缩比率等
异常测试数据及运行结果
压缩大文件
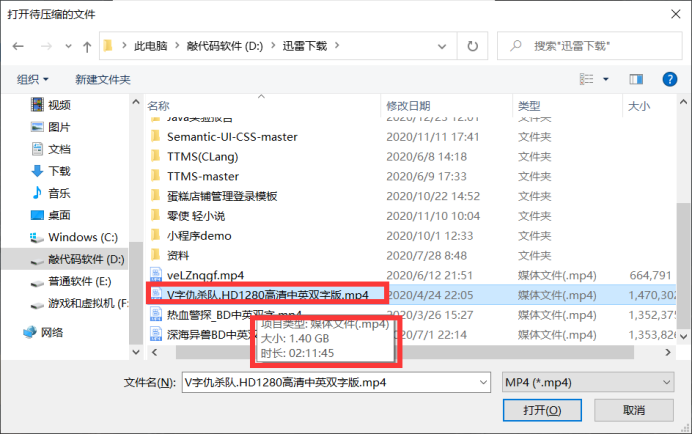
报错:
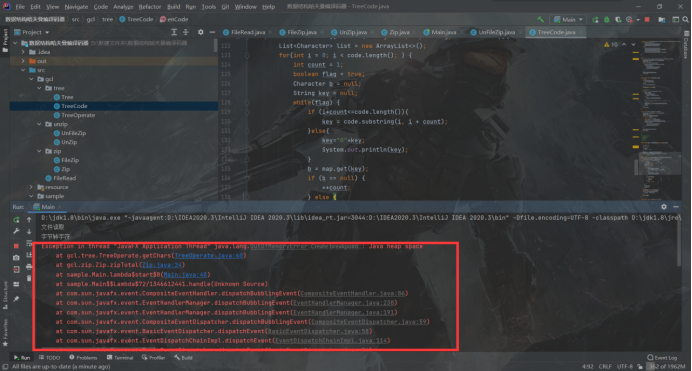
这是因为 Java 虚拟机的堆内存不足导致的报错,这个我得吐槽一下,当初做的匆忙,直接用 String 类型存的编码,导致压缩不了太大的文件…
压缩空文件
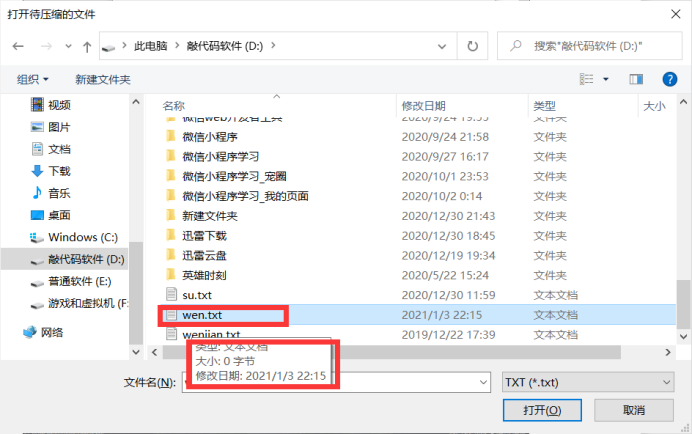
报错:
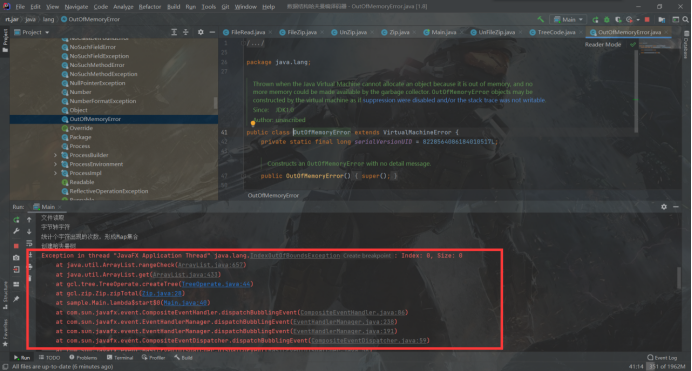
这是因为没有加入文件判空的判断(因为当时想着不会有人压缩一个空文件…吧,好吧,还真有人会压缩空文件)
调试情况,设计技巧及体会
改进方案
现在的哈夫曼编译码器基本实现了实验要求的功能,但是还是有一定的不足和改进的空间的,如下:
- 加上对文件判空的判断,以免当压缩空文件的时候编译器报错;
- 对压缩大文件时 Java 虚拟机内存溢出的解决方法,可以将使用IO流来解决,可以设置一个限值,当读入了 10M 的数据时,一边读取文件一边进行文件数据的操作,对文件数据操作完之后再将操作完的数据输出到压缩文件里面,读取完这10M再继续依照上面的流程进行读取操作,即分片段读写。这样可以大大减少对虚拟机内存的占用,加快虚拟机处理数据的速度。
- JavaFx 编写的界面的美化度还有待提高,可以加上进度条,表示压缩进行到哪一步了,这样可以给人更直观的感受你压缩与解压缩的过程,毕竟不是人人都能看到软件运行时控制台的输出信息的。
体会
这次课设令我收获颇多,将课上学习到的哈夫曼树的知识应用到实际上并做出了一个程序,知道了如何使用代码创建哈夫曼树,创建完后如何将哈夫曼树转为哈夫曼编码,课设之前以为转化为哈夫曼编码再存到文件里面就能实现文件的压缩了,但在写程序的时候才发现这样反而使得文件变得更大了,想要达到压缩的要求,还需要对获得的哈夫曼编码进行按位压缩,按位压缩即将”01”哈夫曼编码按照8位重新压缩成一个字节,理论上数据重复度非常高的时候能使内存减少7到8倍,这样才能使文件达到压缩的效果,而且为了能解压缩,还要往文件里面记录哈夫曼树的信息来恢复哈夫曼树。
参考文献
参考文献多是学校教材…虽然我好像多数是直接上百度查的…
[1] 王曙燕.数据结构与算法. 北京:高等教育出版社. 2019
[2] 王曙燕.数据结构与算法. 北京:人民邮电出版社. 2013
[3] 耿国华.数据结构C语言描述. 北京:高等教育出版社. 2011
[4] 严蔚敏.数据结构. 北京:清华大学出版社. 2012
[5] 王曙燕.C语言程序设计教程. 北京:人民邮电出版社. 2014
最后
项目地址如下:
Github 地址:https://github.com/guanchanglong/HuffmanEncoder/tree/master
麻烦各位可否在看代码的时候顺手给一颗星 ^ _ ^,举手之劳感激不尽。
PS:也可以到我的个人博客查看更多内容
个人博客地址:小关同学的博客