目录
- 编程题
-
-
-
- 1.字典中保存了一些股票代码(键)及价格(值),用一行代码找出价格最高的股票,输出股票代码。(5分)
- 2.字典中保存了一些股票代码(键)及价格(值),用一行代码对字典按股票价格从高到低进行排序,输出股票代码的列表。(5分)
- 用pandas解决问题1,2
- 3.设计一个函数,生成指定长度的验证码,验证码由大小写英文字母和数字构成。(10分)
- 4. 设计一个函数,统计字符串中英文字母和数字各自出现的次数以二元组形式返回。(10分)
- 5. 设计一个函数,统计一个字符串中出现频率最高的字符及其出现次数,以二元组形式返回,注意频率最高的字符可能不止一个。(10分)
- 6. 列表中有1000000个元素,取值范围是[1000, 10000),设计一个函数返回列表中的重复元素,请将函数的执行效率考虑进去。(10分)
-
-
- 数据库
-
-
-
- 1. 有如下所示的学生表(tb_student)和近视表(tb_myopia),查询没有近视的学生的姓名。(10分)(类似题目力扣183)
- 2. 有如下所示的员工表(tb_emp)和部门表(tb_dept),查询每个部门工资(sal)前三高的员工,要求使用窗口函数。(10分)(力扣185题)
- 3. 有如下所示的表格(tb_sales),要求查出如表(tb_result)所示的结果。(10分)
- 4.有如下所示的表格(tb_record),其中第二列(income)代表每个人的收入,统计收入的众数。(10分)
- 5.有如下所示的表格(tb_login_log),统计连续三天有登录行为的用户(user_id),要求使用窗口函数实现。(10分)
-
-
编程题
prices = {
'AAPL': 191.88,
'GOOG': 1186.96,
'IBM': 149.24,
'ORCL': 48.44,
'ACN': 166.89,
'FB': 208.09,
'SYMC': 21.29
}
1.字典中保存了一些股票代码(键)及价格(值),用一行代码找出价格最高的股票,输出股票代码。(5分)
max(prices,key = lambda x : prices[x]) # 'GOOG'
max(prices,key = prices.get) # 'GOOG'
2.字典中保存了一些股票代码(键)及价格(值),用一行代码对字典按股票价格从高到低进行排序,输出股票代码的列表。(5分)
sorted(prices,key = lambda x:prices[x],reverse = True) # ['GOOG', 'FB', 'AAPL', 'ACN', 'IBM', 'ORCL', 'SYMC']
# reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
sorted(prices,key = prices.get) # ['SYMC', 'ORCL', 'IBM', 'ACN', 'AAPL', 'FB', 'GOOG']
用pandas解决问题1,2
import numpy as np
import pandas as pd
df = pd.DataFrame(data = prices.values(),index = prices.keys() ,columns = ['prices'])
# 1
df.prices.nlargest(1).index # Index(['GOOG'], dtype='object')
# 2
df.prices.sort_values(ascending = False).index # Index(['GOOG', 'FB', 'AAPL', 'ACN', 'IBM', 'ORCL', 'SYMC'], dtype='object')
3.设计一个函数,生成指定长度的验证码,验证码由大小写英文字母和数字构成。(10分)
笨方法:先列举出大小写英文字母和数字,根据指定长度随机数生成索引组成验证码
import random
list1 = ['a','b','c','d','e','f','g','h','i','g','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z','A','B','C','D','E','F','G','H','I','G','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z','1','2','3','4','5','6','7','8','9','0']
length = len(list1)
# print(length)
def func_1(n):
res = []
for _ in range(n):
res.append(list1[random.randint(0,length)])
return ''.join(res)
print(func_1(10))
参考答案:直接调用string中的字母和数字列表,用random.choices选择指定长度的验证码
import string
all_chars = string.ascii_letters + string.digits
def random_code(length = 4):
return ''.join(random.choices(all_chars,k=length))
注意:因为修改的是命名变量,所以修改变量默认参数值的时候需要写”变量名 = 设定值“
for _ in range(10):
print(random_code(length = 7))
"""
LxTjoyk
DK4wI9Q
ASc2jB4
r61h4VY
8vilgaR
mMbxDAq
aY6EoRo
Mvd50Pd
y2kFI9W
96fFYhl
"""
4. 设计一个函数,统计字符串中英文字母和数字各自出现的次数以二元组形式返回。(10分)
利用正则表达式解决问题
import re
def func_2(data):
length = len(data)
num = re.sub(r'\D',"",data) # 将非数字的字符替换为空字符串
return length-len(num),len(num)
data2 = 'abc23543RFGV'
print(func_2(data2)) # (7, 5)
参考答案:定义两个计数器,分别计数字母,数字
def count_(content:str):
letters_count,num_count = 0,0
for x in content:
if 'a' <= x <= 'z' or 'A' <= x <= 'Z':
letters_count+=1
if '0' <= x <= '9':
num_count+=1
return letters_count,num_count
print(count_('abc23543RFGV')) # (7, 5)
5. 设计一个函数,统计一个字符串中出现频率最高的字符及其出现次数,以二元组形式返回,注意频率最高的字符可能不止一个。(10分)
参考答案:
def find_highest_freq(content:str):
info={
}
for ch in content:
info[ch] = info.get(ch,0) + 1 # 挨个获取字符串的每个字符,以字符为键获取对应的值,值+1 更新字典相应键对应的值
max_count = max(info.values())
return [key for key,value in info.items() if value == max_count],max_count
# 字典.get(key,默认值) - 获取字典中指定key对应的值,key不存在返回默认值
验证
find_highest_freq('aabbccaacc') # (['a', 'c'], 4)
相关题目 :力扣 217 (题目链接)
class Solution:
def containsDuplicate(self, nums: List[int]) -> bool:
haxi = {}
for x in nums:
haxi[x] = haxi.get(x,0)+1
if haxi[x]>=2: return True
return False
6. 列表中有1000000个元素,取值范围是[1000, 10000),设计一个函数返回列表中的重复元素,请将函数的执行效率考虑进去。(10分)
参考答案:以空间换时间
def find_duplicates(nums):
counters = [0]*10000 # 创建一个长度为10000,元素为0的数组,数组下标对应的数值为该下标值在给定数组中的出现次数
for num in nums:
counters[num] += 1 # 取出每个数,修改计数数组相应下标的值加1
return [index for index,item in enumerate(counters) if item >1] # 返回计数数组中,值>1的下标值
验证
find_duplicates([1111,1111,1112,1113,1112]) # [1111 , 1112]
数据库
1. 有如下所示的学生表(tb_student)和近视表(tb_myopia),查询没有近视的学生的姓名。(10分)(类似题目力扣183)
#
# tb_student
# +---------+-----------+
# | stu_id | stu_name |
# +---------+-----------+
# | 1 | Alice |
# | 2 | Bob |
# | 3 | Jack |
# | 4 | Jerry |
# | 5 | Tom |
# +---------+-----------+
#
# tb_myopia
# +------+------------+
# | mid | stu_id |
# +------+------------+
# | 1 | 3 |
# | 2 | 2 |
# | 3 | 5 |
# +------+------------+
建表
create table tb_student
(
stu_id int unsigned auto_increment,
stu_name varchar(20) not null ,
primary key (stu_id)
);
create table tb_myopia
(
`mid` int unsigned auto_increment,
stu_id int not null,
primary key (`mid`)
);
insert into tb_student (stu_id,stu_name)
values
(1,'Alice'),
(2,'Bob'),
(3,'Jack'),
(4,'Jerry'),
(5,'Tom');
insert into tb_myopia (`mid`,stu_id)
values
(1,3),
(2,2),
(3,5);
法一:子查询 + not in
思路:选择 stu_id 不在近视表中的学生姓名
select stu_name from tb_student
where stu_id not in (select stu_id from tb_myopia);
法二:左外连接
思路:最终选择的是左表有的,右表没有的,选择左外连接,条件where mid is null / where stu_id is null 都可以
select stu_name from tb_student t1 left join tb_myopia t2 on t1.stu_id=t2.stu_id where mid is null;
或
select stu_name from tb_student t1 left join tb_myopia t2 on t1.stu_id=t2.stu_id where t2.stu_id is null;
2. 有如下所示的员工表(tb_emp)和部门表(tb_dept),查询每个部门工资(sal)前三高的员工,要求使用窗口函数。(10分)(力扣185题)
#
# tb_emp
# +-----+--------+--------+--------+
# | eno | ename | sal | dno |
# +-----+--------+--------+--------+
# | 1 | Alice | 85000 | 1 |
# | 2 | Amy | 80000 | 2 |
# | 3 | Bob | 65000 | 2 |
# | 4 | Betty | 90000 | 2 |
# | 5 | Jack | 69000 | 1 |
# | 6 | Jerry | 85000 | 1 |
# | 7 | Martin | 72000 | 2 |
# | 8 | Vera | 75000 | 1 |
# +-----+--------+--------+--------+
#
# tb_dept
# +----+-------+
# | id | name |
# +----+-------+
# | 1 | R&D |
# | 2 | Sales |
# +----+-------+
建表
create table tb_emp
(
eno int unsigned auto_increment,
ename varchar(20) not null,
sal int not null,
dno int not null,
primary key (eno)
);
create table tb_dept
(
id int not null,
name varchar(20)
);
insert into tb_emp (eno,ename,sal,dno)
values
(1,'Alice',85000,1),
(2,'Amy',80000,2),
(3,'Bob',65000,2),
(4,'Betty',90000,2),
(5,'Jack',69000,1),
(6,'Jerry',85000,1),
(7,'Martin',72000,2),
(8,'Vera',75000,1);
insert into tb_dept (id,name)
values
(1,'R&D'),
(2,'Sales');
思路:窗函数+子查询
select name `Department`,ename `Employee`,sal `Salary`
from
(
select name,ename,sal,
dense_rank() over (partition by id order by sal desc) as rn
from tb_emp t1, tb_dept t2
where t1.dno = t2.id
) temp
where rn<=3;
中间过程(子查询):
select name,ename,sal,
dense_rank() over (partition by id order by sal desc) as rn
from tb_emp t1, tb_dept t2
where t1.dno = t2.id;
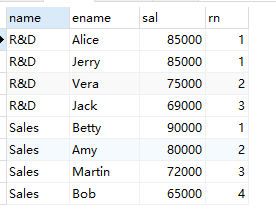
3. 有如下所示的表格(tb_sales),要求查出如表(tb_result)所示的结果。(10分)
# tb_sales
# +------+---------+--------+
# | year | quarter | amount |
# +------+---------+--------+
# | 2020 | 2 | 11 |
# | 2020 | 2 | 12 |
# | 2020 | 3 | 13 |
# | 2020 | 3 | 14 |
# | 2020 | 4 | 15 |
# | 2021 | 1 | 16 |
# | 2021 | 1 | 17 |
# | 2021 | 2 | 18 |
# | 2021 | 3 | 19 |
# | 2021 | 4 | 18 |
# | 2021 | 4 | 17 |
# | 2021 | 4 | 16 |
# | 2022 | 1 | 15 |
# | 2022 | 1 | 14 |
# +------+---------+--------+
#
# tb_result
#
# +------+--------+--------+--------+--------+
# | year | Q1 | Q2 | Q3 | Q4 |
# +------+--------+--------+--------+--------+
# | 2020 | 0 | 23 | 27 | 15 |
# | 2021 | 33 | 18 | 19 | 51 |
# | 2022 | 29 | 0 | 0 | 0 |
# +------+--------+--------+--------+--------+
建表:
create table tb_sales
(
year int not null,
quarter int not null,
amount int not null
);
delete from tb_sales;
insert into tb_sales
values
(2020,2,11),
(2020,2,12),
(2020,3,13),
(2020,3,14),
(2020,4,15),
(2021,1,16),
(2021,1,17),
(2021,2,18),
(2021,3,19),
(2021,4,18),
(2021,4,17),
(2021,4,16),
(2022,1,15),
(2022,1,14);
思路:聚合函数 + (case when then else end)
宽表变窄表
select year,
sum(case quarter when 1 then amount else 0 end) as 'Q1',
sum(case quarter when 2 then amount else 0 end) as 'Q2',
sum(case quarter when 3 then amount else 0 end) as 'Q3',
sum(case quarter when 4 then amount else 0 end) as 'Q4'
from tb_sales
group by year;
4.有如下所示的表格(tb_record),其中第二列(income)代表每个人的收入,统计收入的众数。(10分)
# tb_record
# +--------+--------+
# | name | income |
# +--------+--------+
# | Alice | 85000 |
# | Amy | 65000 |
# | Bob | 65000 |
# | Betty | 90000 |
# | Jack | 82000 |
# | Jerry | 65000 |
# | Martin | 82000 |
# | Vera | 85000 |
# +--------+--------+
建表
create table tb_record
(
name varchar(20) not null,
income int unsigned not null
);
insert into tb_record (`name` , income)
values
('Alice',85000),
('Amy',65000),
('Bob',65000),
('Betty',90000),
('Jack',82000),
('Jerry',65000),
('Martin',82000),
('Vera',85000);
思路:ALL: 与子查询返回的所有值比较为true 则返回true
select income from tb_record group by income
having count(*) >= all(select count(*) from tb_record group by income);
5.有如下所示的表格(tb_login_log),统计连续三天有登录行为的用户(user_id),要求使用窗口函数实现。(10分)
建表
create table tb_login_log
(
user_id varchar(10) not null,
login_date date not null
);
insert into tb_login_log(user_id,login_date)
values
('A','2019-09-02'),
('A','2019-09-03'),
('A','2019-09-04'),
('B','2018-11-25'),
('B','2018-12-31'),
('C','2019-01-01'),
('C','2019-04-04'),
('C','2019-09-03'),
('C','2019-09-04'),
('C','2019-09-05');
思路:窗函数 + 子查询
select distinct user_id
from (
select user_id,login_date,
row_number() over (partition by user_id order by login_date) as rn
from tb_login_log
) temp
group by user_id,subdate(login_date,rn)
having count(*) >= 3;