cntext中文文本分析库,可对文本进行词频统计、词典扩充、情绪分析、相似度、可读性等
功能模块含
-
[x] stats 文本统计指标
-
[x] 词频统计
-
[x] 可读性
-
[x] 内置pkl词典
-
[x] 情感分析
-
[x] dictionary 构建词表(典)
-
[x] Sopmi 互信息扩充词典法
-
[x] W2Vmodels 词向量扩充词典法
-
[x] similarity 文本相似度
-
[x] cos相似度
-
[x] jaccard相似度
-
[x] 编辑距离相似度
-
[ ] bias 待开发
喜欢记得收藏、关注、点赞。
⚠️ 【注】资料、代码、交流,文末获取
安装
pip install cntext==1.6
QuickStart
import cntext as ct
help(ct)
Run
Help on package cntext:
NAME
cntext
PACKAGE CONTENTS
bias
dictionary
similarity
stats
一、stats
目前stats内置的函数有
-
readability 文本可读性
-
term_freq 词频统计函数
-
dict_pkl_list 获取cntext内置词典列表(pkl格式)
-
load_pkl_dict 导入pkl词典文件
-
diction 情感分析
import cntext as ct
text = '如何看待一网文作者被黑客大佬盗号改文,因万分惭愧而停更。'
ct.term_freq(text)
Run
Counter({
'看待': 1,
'网文': 1,
'作者': 1,
'黑客': 1,
'大佬': 1,
'盗号': 1,
'改文因': 1,
'万分': 1,
'惭愧': 1,
'停': 1})
1.1 readability
文本可读性,指标越大,文章复杂度越高,可读性越差。
readability(text, language=‘chinese’)
-
text: 文本字符串数据
-
language: 语言类型,“chinese"或"english”,默认"chinese"
中文可读性 算法参考自
徐巍,姚振晔,陈冬华.中文年报可读性:衡量与检验[J].会计研究,2021(03):28-44.
readability1 —每个分句中的平均字数
readability2 —每个句子中副词和连词所占的比例
readability3 —参考Fog Index, readability3=(readability1+readability2)×0.5
以上三个指标越大,都说明文本的复杂程度越高,可读性越差。
import cntext as ct
text = '如何看待一网文作者被黑客大佬盗号改文,因万分惭愧而停更。'
ct.readability(text, language='chinese')
Run
{
'readability1': 13.5,
'readability2': 0.08333333333333333,
'readability3': 6.791666666666667}
1.2 term_freq
词频统计函数,返回Counter类型
import cntext as ct
text = '如何看待一网文作者被黑客大佬盗号改文,因万分惭愧而停更。'
ct.term_freq(text)
Run
Counter({
'看待': 1,
'网文': 1,
'作者': 1,
'黑客': 1,
'大佬': 1,
'盗号': 1,
'改文因': 1,
'万分': 1,
'惭愧': 1,
'停': 1})
1.3 dict_pkl_list
获取cntext内置词典列表(pkl格式)
import cntext as ct
# 获取cntext内置词典列表(pkl格式)
ct.dict_pkl_list()
Run
['DUTIR.pkl',
'HOWNET.pkl',
'sentiws.pkl',
'ChineseFinancialFormalUnformalSentiment.pkl',
'ANEW.pkl',
'LSD2015.pkl',
'NRC.pkl',
'geninqposneg.pkl',
'HuLiu.pkl',
'AFINN.pkl',
'ADV_CONJ.pkl',
'LoughranMcDonald.pkl',
'STOPWORDS.pkl']
词典对应关系, 部分情感词典资料整理自 quanteda.sentiment
| pkl文件 | 词典 | 语言 | 功能 |
|---|---|---|---|
| DUTIR.pkl | 大连理工大学情感本体库 | 中文 | 七大类情绪,哀, 好, 惊, 惧, 乐, 怒, 恶 |
| HOWNET.pkl | 知网Hownet词典 | 中文 | 正面词、负面词 |
| sentiws.pkl | SentimentWortschatz (SentiWS) | 英文 | 正面词、负面词; |
| 效价 | |||
| ChineseFinancialFormalUnformalSentiment.pkl | 金融领域正式、非正式;积极消极 | 中文 | formal-pos、 |
formal-neg;
unformal-pos、
unformal-neg |
| ANEW.pkl | 英语单词的情感规范Affective Norms for English Words (ANEW) | 英文 | 词语效价信息 |
| LSD2015.pkl | Lexicoder Sentiment Dictionary (2015) | 英文 | 正面词、负面词 |
| NRC.pkl | NRC Word-Emotion Association Lexicon | 英文 | 细粒度情绪词; |
| geninqposneg.pkl |
|
|
|
| HuLiu.pkl | Hu&Liu (2004)正、负情感词典 | 英文 | 正面词、负面词 |
| AFINN.pkl | 尼尔森 (2011) 的“新 ANEW”效价词表 | 英文 | 情感效价信息valence |
| LoughranMcDonald.pkl | 会计金融LM词典 | 英文 | 金融领域正、负面情感词 |
| ADV_CONJ.pkl | 副词连词 | 中文 |
|
| STOPWORDS.pkl |
| 中、英 | 停用词 |
注意:
-
如果用户情绪分析时使用DUTIR词典发表论文,请在论文中添加诸如“使用了大连理工大学信息检索研究室的情感词汇本体” 字样加以声明。参考文献中加入引文“徐琳宏,林鸿飞,潘宇,等.情感词汇本体的构造[J]. 情报学报, 2008, 27(2): 180-185.”
-
如果大家有制作的词典,可以上传至百度网盘,并在issue中留下词典的网盘链接。如词典需要使用声明,可连同文献出处一起issue
1.4 load_pkl_dict
导入pkl词典文件,返回字典样式数据。
import cntext as ct
# 导入pkl词典文件,
print(ct.load_pkl_dict('DUTIR.pkl'))
Run
{
'DUTIR': {
'哀': ['怀想', '治丝而棼', ...],
'好': ['进贤黜奸', '清醇', '放达', ...],
'惊': ['惊奇不已', '魂惊魄惕', '海外奇谈',...],
'惧': ['忸忸怩怩', '谈虎色变', '手忙脚乱', '刿目怵心',...],
'乐': ['百龄眉寿', '娱心', '如意', '喜糖',...],
'怒': ['饮恨吞声', '扬眉瞬目',...],
'恶': ['出逃', '鱼肉百姓', '移天易日',]
}
1.5 sentiment
sentiment(text, diction, language=‘chinese’) 使用diy词典进行情感分析,计算各个情绪词出现次数; 未考虑强度副词、否定词对情感的复杂影响,
-
text: 待分析中文文本
-
diction: 情感词字典;
-
language: 语言类型,“chinese"或"english”,默认"chinese"
import cntext as ct
text = '我今天得奖了,很高兴,我要将快乐分享大家。'
ct.sentiment(text=text,
diction=ct.load_pkl_dict('DUTIR.pkl')['DUTIR'])
Run
{
'哀_num': 0,
'好_num': 0,
'惊_num': 0,
'惧_num': 0,
'乐_num': 3,
'怒_num': 0,
'恶_num': 0,
'stopword_num': 7,
'sentence_num': 1,
'word_num': 13}
如果不适用pkl词典,可以自定义自己的词典,例如
import cntext as ct
diction = {
'pos': ['高兴', '快乐', '分享'],
'neg': ['难过', '悲伤'],
'adv': ['很', '特别']}
text = '我今天得奖了,很高兴,我要将快乐分享大家。'
ct.sentiment(text, diction)
Run
{
'pos_num': 7,
'neg_num': 0,
'adv_num': 1,
'stopword_num': 7,
'sentence_num': 1,
'word_num': 13}
二、dictionary
本模块用于构建词表(典),含
-
SoPmi 共现法扩充词表(典)
-
W2VModels 词向量word2vec扩充词表(典)
2.1 SoPmi 共现法
import cntext as ct
import os
sopmier = ct.SoPmi(cwd=os.getcwd(),
input_txt_file='data/sopmi_corpus.txt', #原始数据,您的语料
seedword_txt_file='data/sopmi_seed_words.txt', #人工标注的初始种子词
)
sopmier.sopmi()
Run
Step 1/4:...预处理 语料 ...
Loading model cost 0.543 seconds.
Prefix dict has been built successfully.
Step 2/4:...收集 共现词线索 ...
Step 3/4:...计算 互信息 ...
Step 4/4:...保存 候选词 ...
完成! 耗时 49.50996398925781 s
2.2 W2VModels 词向量
特别要注意代码需要设定lang语言参数
import cntext as ct
import os
#初始化模型,需要设置lang参数。
model = ct.W2VModels(cwd=os.getcwd(),
lang='english') #语料数据 w2v_corpus.txt
model.train(input_txt_file='data/w2v_corpus.txt')
#根据种子词,筛选出没类词最相近的前100个词
model.find(seedword_txt_file='data/w2v_seeds/integrity.txt',
topn=100)
model.find(seedword_txt_file='data/w2v_seeds/innovation.txt',
topn=100)
model.find(seedword_txt_file='data/w2v_seeds/quality.txt',
topn=100)
model.find(seedword_txt_file='data/w2v_seeds/respect.txt',
topn=100)
model.find(seedword_txt_file='data/w2v_seeds/teamwork.txt',
topn=100)
Run
Step 1/4:...预处理 语料 ...
Step 2/4:...训练 word2vec模型 ...
Step 3/4:...准备 每个seed在word2vec模型中的相似候选词...
Step 4/4 完成! 耗时 60 s
Step 3/4:...准备 每个seed在word2vec模型中的相似候选词...
Step 4/4 完成! 耗时 60 s
Step 3/4:...准备 每个seed在word2vec模型中的相似候选词...
Step 4/4 完成! 耗时 60 s
Step 3/4:...准备 每个seed在word2vec模型中的相似候选词...
Step 4/4 完成! 耗时 60 s
Step 3/4:...准备 每个seed在word2vec模型中的相似候选词...
Step 4/4 完成! 耗时 60 s
需要注意
训练出的w2v模型可以后续中使用。
from gensim.models import KeyedVectors
w2v_model = KeyedVectors.load(w2v.model路径)
#找出word的词向量
#w2v_model.get_vector(word)
#更多w2_model方法查看
#help(w2_model)
2.3 co_occurrence_matrix
词共现矩阵
import cntext as ct
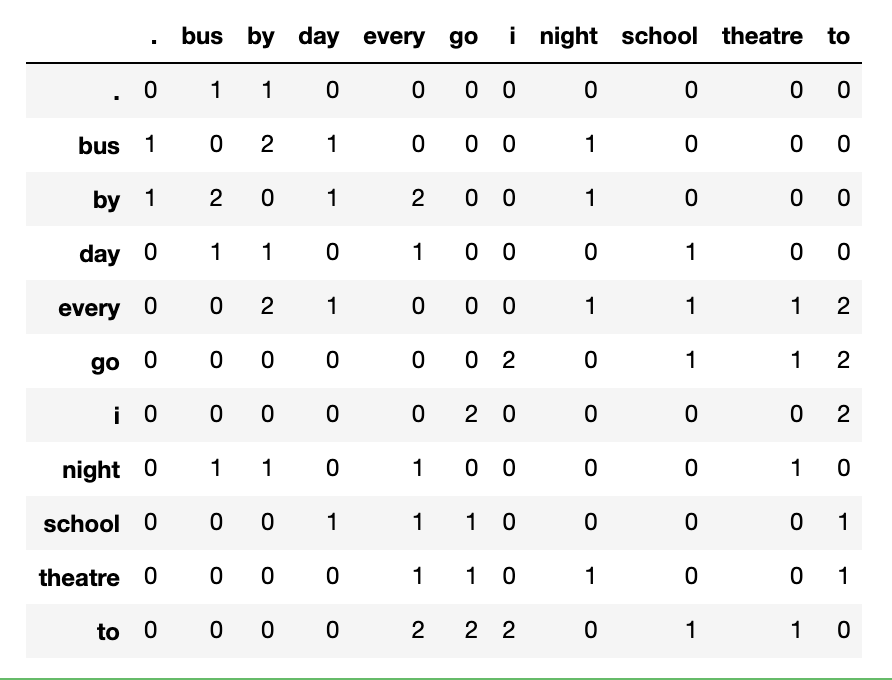
documents = ["I go to school every day by bus .",
"i go to theatre every night by bus"]
ct.co_occurrence_matrix(documents,
window_size=2,
lang='english')
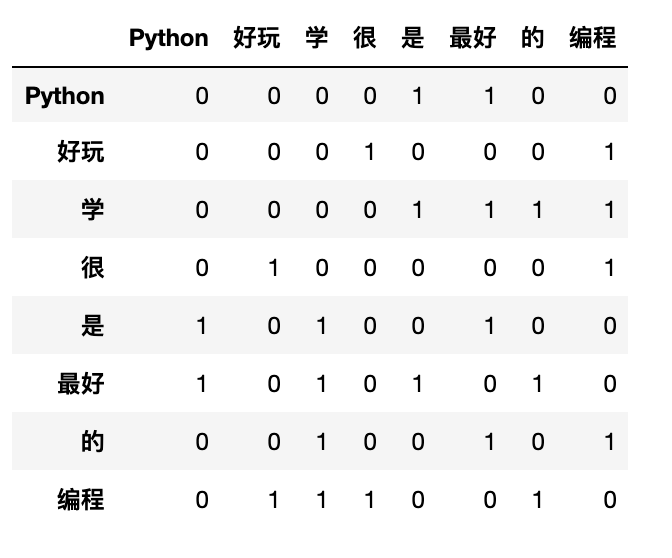
documents2 = ["编程很好玩",
"Python是最好学的编程"]
ct.co_occurrence_matrix(documents2,
window_size=2,
lang='chinese')
三、similarity
四种相似度计算函数
-
cosine_sim(text1, text2) cos余弦相似
-
jaccard_sim(text1, text2) jaccard相似
-
minedit_sim(text1, text2) 最小编辑距离相似度;
-
simple_sim(text1, text2) 更改变动算法
算法实现参考自 Cohen, Lauren, Christopher Malloy, and Quoc Nguyen. Lazy prices. No. w25084. National Bureau of Economic Research, 2018.
import cntext as ct
text1 = '编程真好玩编程真好玩'
text2 = '游戏真好玩编程真好玩'
print(ct.cosine_sim(text1, text2))
print(ct.jaccard_sim(text1, text2))
print(ct.minedit_sim(text1, text2))
print(ct.simple_sim(text1, text2))
Run
0.9999999999999998
1.0
1
0.84375
推荐文章
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
