代码基于ceph nautilus版本
MDS关键概念
想要理解MDS切换过程,首先需要理清一些基本概念。
MDSMAP
- 包含整个ceph集群的所有mds的状态信息:fs个数、fs名称、各mds状态、数据池、元数据池信息,等等
- 包含当前的MDS map epoch(纪元),即地图创建的时间,以及它最后一次改变的时间。它还包含用于储存元数据的池,元数据服务器的列表,以及哪些元数据服务器up和in。要查看MDS map,请执行ceph fs dump。
RANK
- rank定义了多mds直接对元数据负载的划分,每个mds最多只能持有一个rank,每个rank对应一个目录子树,rank id从0开始。
- Ranks定义了元数据工作负载在 多个元数据服务器守护进程(multiple Metadata Server (MDS) daemons)之间的共享方式。ranks的数量是MDS守护进程的最大数量,可以在同一时间活动。每个MDS守护进程 handles分配给该rank的Ceph文件系统元数据的一个子集(a subset of the Ceph File System metadata。
- 每个MDS守护程序最初启动时都没有rank。Monitor会给守护进程分配一个rank。一个MDS守护进程在同一时间只能拥有一个rank。守护进程只有在它们被停止时才会失去rank。
这里注意一种特殊情况,即stand-replay状态下的mds也是持有rank的,s且 id和其follow的active mds的rank id相同,如下图所示

MDS JOURNAL
- cephfs的journal是用于记录元数据事件的日志
- journal以event形式存放在rados的metadata pool中
- 在处理每个io行为时,先写journal再执行实际的io操作
- 每个active mds维护自己的journal
- journal被分割为多个object
- mds会修剪(trim)不需要的journal条目
- journal event 查看:cephfs-journal-tool --rank=<fs>:<rank> event get list
(cephfs-journal-tool — Ceph Documentation 中文:https://www.bookstack.cn/read/ceph-10-zh/8a5dc6d87f084b2a.md)
下面是一个journal event示例(中间还有很多内容被折叠了):

CAPS
即cephfs实现的分布式锁,详见https://docs.ceph.com/docs/master/cephfs/client-auth/
MDS状态机
理解mds的切换首先需要认识清除mds有哪些状态,以及可以进行哪些状态跃迁。有关mds状态机的知识在官网上有详细的介绍:https://docs.ceph.com/docs/master/cephfs/mds-states/
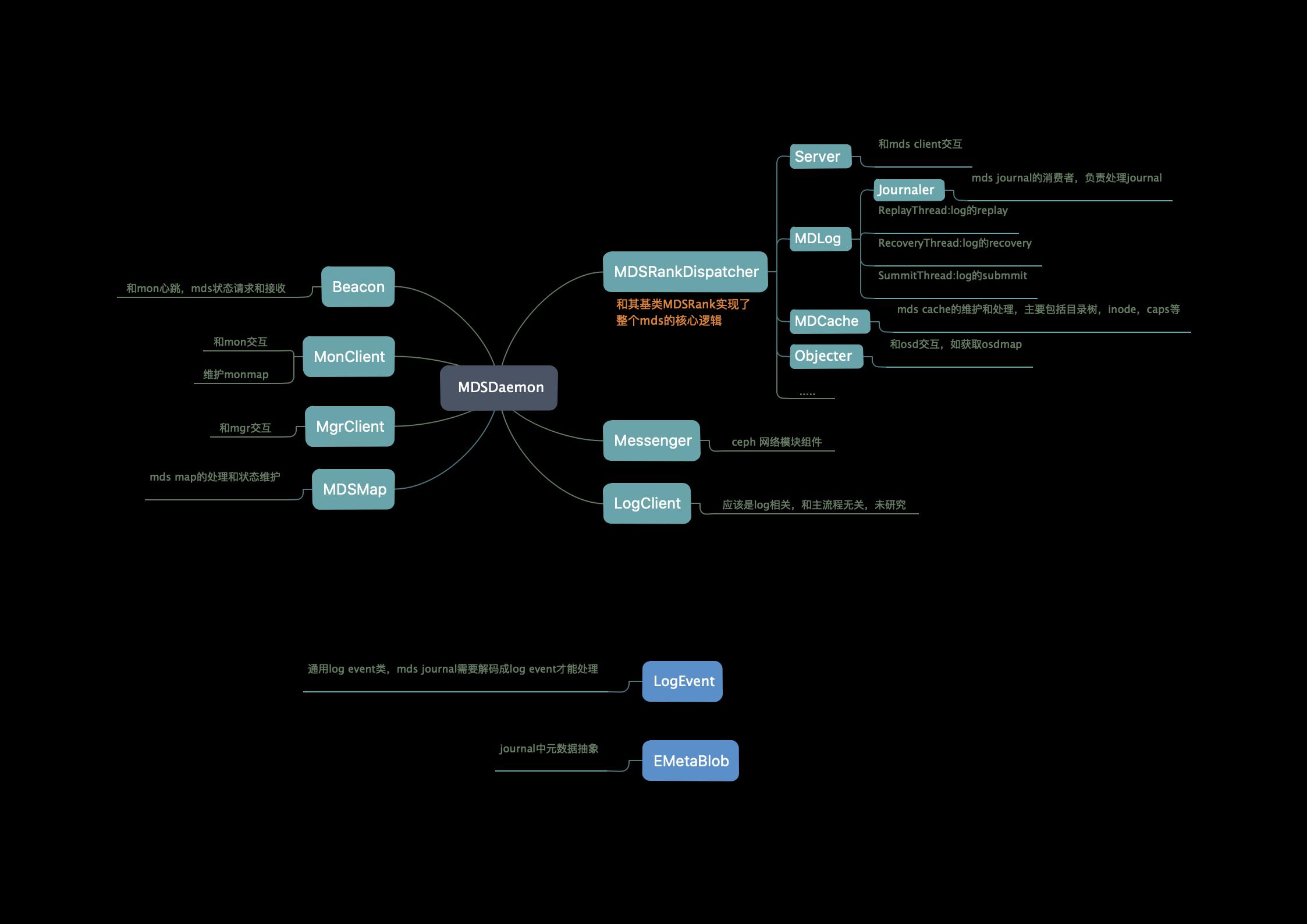
MDS类图
参考下图:注意图中仅列出了mds部分架构和核心类,实际的组成更复杂,涉及的类和逻辑也更多。
冷备OR热备
-
冷备:默认配置下,除active mds外其余MDS均处于standby状态,除了保持和mon的心跳,其他什么都不做,cache为空,无rank。
-
热备:配置allow_standby_replay为true,每个active mds都会有一个专属standby-replay mds在follow,持有和active mds相同的rank id,不断从rados中读取journal加载到cache中以尽可能和actvie mds保持同步。
显然在热备状态下会有一个standby-replay的mds一直在更新cache,这样在切换发生时其切换流程会更快。
切换流程分析
首先分析切换过程之前,先明确MDS切换的两个核心思想:
- 新的active的mds的选举,是由mon来决定的,整个切换过程涉及mon和mds的多次交互
- 所有切换过程均是通过mdsmap来驱动的,mdsmap中标记了对当前集群中各mds状态的规划,mds每处理完一个阶段的规划后会主动向mon请求下一个阶段
上文中已介绍了mds的消息分发处理,而在切换流程中,mon和mds的交互都是mdsmap,下面先看一下mdsmap的处理流程:
MDSDaemon::handle_mds_map:
MDSRankDispatcher::handle_mds_map:
逻辑太多,只截取了部分代码
void MDSRankDispatcher::handle_mds_map(
const MMDSMap::const_ref &m,
const MDSMap &oldmap)
{
// I am only to be passed MDSMaps in which I hold a rank
ceph_assert(whoami != MDS_RANK_NONE);
// 当前状态为oldstate,从mds map中获取新的状态为state,
// 如果两者不相等,则更新last_state和incarnation,incarnation表示rank当前在哪个dameon?
MDSMap::DaemonState oldstate = state;
mds_gid_t mds_gid = mds_gid_t(monc->get_global_id());
state = mdsmap->get_state_gid(mds_gid);
if (state != oldstate) {
last_state = oldstate;
incarnation = mdsmap->get_inc_gid(mds_gid);
}
version_t epoch = m->get_epoch();
// note source's map version
// 当前mds集群状态已经准备变更,进入了新的epoch,那么需要更新其他mds的epoch值
if (m->get_source().is_mds() &&
peer_mdsmap_epoch[mds_rank_t(m->get_source().num())] < epoch) {
dout(15) << " peer " << m->get_source()
<< " has mdsmap epoch >= " << epoch
<< dendl;
peer_mdsmap_epoch[mds_rank_t(m->get_source().num())] = epoch;
}
// Validate state transitions while I hold a rank
// 根据新旧状态进行校验,如果是invalid的状态跃迁则重启,哪些状态跃迁是合法的:
// 参考https://docs.ceph.com/docs/master/cephfs/mds-states/#mds-states中的图
if (!MDSMap::state_transition_valid(oldstate, state)) {
derr << "Invalid state transition " << ceph_mds_state_name(oldstate)
<< "->" << ceph_mds_state_name(state) << dendl;
respawn();
}
// mdsmap and oldmap can be discontinuous. failover might happen in the missing mdsmap.
// the 'restart' set tracks ranks that have restarted since the old mdsmap
set<mds_rank_t> restart;
// replaying mds does not communicate with other ranks
// 如果新的状态>=resolve,则进行一堆逻辑处理,resolve只会在多active mds中存在,目前不关注
if (state >= MDSMap::STATE_RESOLVE) {
// did someone fail?
// new down?
set<mds_rank_t> olddown, down;
oldmap.get_down_mds_set(&olddown);
mdsmap->get_down_mds_set(&down);
for (const auto& r : down) {
if (oldmap.have_inst(r) && olddown.count(r) == 0) {
messenger->mark_down_addrs(oldmap.get_addrs(r));
handle_mds_failure(r);
}
}
// did it change?
if (oldstate != state) {
dout(1) << "handle_mds_map state change "
<< ceph_mds_state_name(oldstate) << " --> "
<< ceph_mds_state_name(state) << dendl;
beacon.set_want_state(*mdsmap, state);
// 如果当前是standby-replay状态,则无需走下面的大串分支,直接走到最后
if (oldstate == MDSMap::STATE_STANDBY_REPLAY) {
dout(10) << "Monitor activated us! Deactivating replay loop" << dendl;
assert (state == MDSMap::STATE_REPLAY);
} else {
// did i just recover?
if ((is_active() || is_clientreplay()) &&
(oldstate == MDSMap::STATE_CREATING ||
oldstate == MDSMap::STATE_REJOIN ||
oldstate == MDSMap::STATE_RECONNECT))
recovery_done(oldstate);
// 根据新的mdsmap中的状态来决定接下来的过程
if (is_active()) {
active_start();
} else if (is_any_replay()) {
// standby状态下的mds收到将其标记为stand-replay的mdsmap后也会走此分支
replay_start();
} else if (is_resolve()) {
resolve_start();
} else if (is_reconnect()) {
reconnect_start();
} else if (is_rejoin()) {
rejoin_start();
} else if (is_clientreplay()) {
clientreplay_start();
} else if (is_creating()) {
boot_create();
} else if (is_starting()) {
boot_start();
} else if (is_stopping()) {
ceph_assert(oldstate == MDSMap::STATE_ACTIVE);
stopping_start();
}
}
}
// RESOLVE
// is someone else newly resolving?
if (state >= MDSMap::STATE_RESOLVE) {
// recover snaptable
if (mdsmap->get_tableserver() == whoami) {
}
if ((!oldmap.is_resolving() || !restart.empty()) && mdsmap->is_resolving()) {
set<mds_rank_t> resolve;
mdsmap->get_mds_set(resolve, MDSMap::STATE_RESOLVE);
dout(10) << " resolve set is " << resolve << dendl;
calc_recovery_set();
mdcache->send_resolves();
}
}
// REJOIN
// is everybody finally rejoining?
if (state >= MDSMap::STATE_REJOIN) {
// did we start?
if (!oldmap.is_rejoining() && mdsmap->is_rejoining())
rejoin_joint_start();
// did we finish?
if (g_conf()->mds_dump_cache_after_rejoin &&
oldmap.is_rejoining() && !mdsmap->is_rejoining())
mdcache->dump_cache(); // for DEBUG only
if (oldstate >= MDSMap::STATE_REJOIN ||
oldstate == MDSMap::STATE_STARTING) {
// ACTIVE|CLIENTREPLAY|REJOIN => we can discover from them.
}
if (oldmap.is_degraded() && !cluster_degraded && state >= MDSMap::STATE_ACTIVE) {
dout(1) << "cluster recovered." << dendl;
auto it = waiting_for_active_peer.find(MDS_RANK_NONE);
if (it != waiting_for_active_peer.end()) {
queue_waiters(it->second);
waiting_for_active_peer.erase(it);
}
}
// did someone go active?
if (state >= MDSMap::STATE_CLIENTREPLAY &&
oldstate >= MDSMap::STATE_CLIENTREPLAY) {
set<mds_rank_t> oldactive, active;
oldmap.get_mds_set_lower_bound(oldactive, MDSMap::STATE_CLIENTREPLAY);
mdsmap->get_mds_set_lower_bound(active, MDSMap::STATE_CLIENTREPLAY);
for (const auto& r : active) {
if (r == whoami)
continue; // not me
if (!oldactive.count(r) || restart.count(r)) // newly so?
handle_mds_recovery(r);
}
}
if (is_clientreplay() || is_active() || is_stopping()) {
// did anyone stop?
set<mds_rank_t> oldstopped, stopped;
oldmap.get_stopped_mds_set(oldstopped);
mdsmap->get_stopped_mds_set(stopped);
for (const auto& r : stopped)
if (oldstopped.count(r) == 0) { // newly so?
mdcache->migrator->handle_mds_failure_or_stop(r);
if (mdsmap->get_tableserver() == whoami)
snapserver->handle_mds_failure_or_stop(r);
}
}
// 唤醒所有waiting_for_mdsmap中的线程,并将其从中移出
{
map<epoch_t,MDSContext::vec >::iterator p = waiting_for_mdsmap.begin();
while (p != waiting_for_mdsmap.end() && p->first <= mdsmap->get_epoch()) {
MDSContext::vec ls;
ls.swap(p->second);
waiting_for_mdsmap.erase(p++);
// 唤醒ls
queue_waiters(ls);
}
}
if (is_active()) {
// Before going active, set OSD epoch barrier to latest (so that
// we don't risk handing out caps to clients with old OSD maps that
// might not include barriers from the previous incarnation of this MDS)
set_osd_epoch_barrier(objecter->with_osdmap(
std::mem_fn(&OSDMap::get_epoch)));
/* Now check if we should hint to the OSD that a read may follow */
if (mdsmap->has_standby_replay(whoami))
mdlog->set_write_iohint(0);
else
mdlog->set_write_iohint(CEPH_OSD_OP_FLAG_FADVISE_DONTNEED);
}
if (oldmap.get_max_mds() != mdsmap->get_max_mds()) {
purge_queue.update_op_limit(*mdsmap);
}
mdcache->handle_mdsmap(*mdsmap);
}
冷备主从切换

热备主从切换
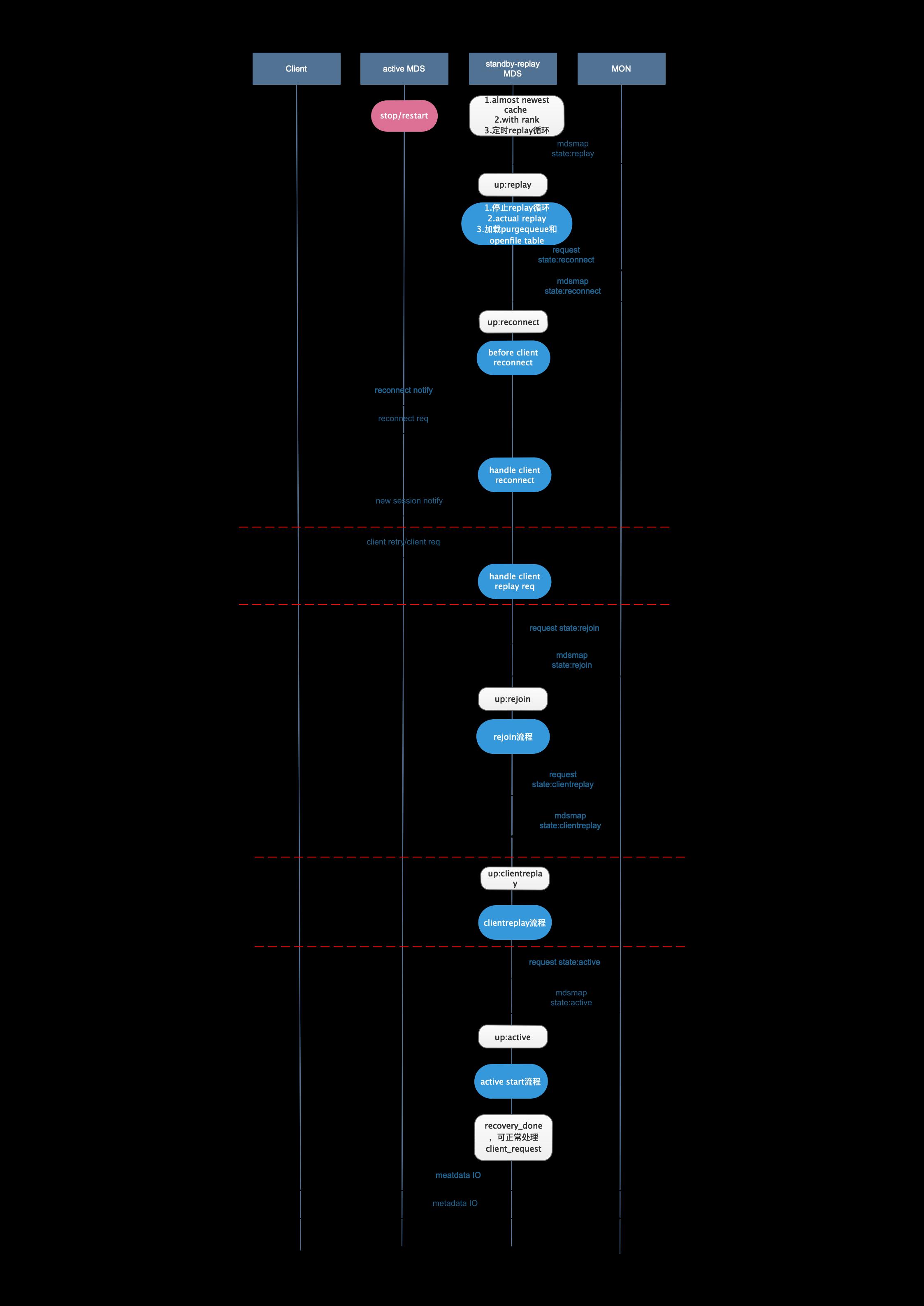
可以看到,冷备和热备的切换流程的不同主要体现在切换前和replay两个阶段,其余流程基本相同。
具体切换流程
UP:REPLAY
REPLAY START
replay流程由MDSRank::replay_start()触发,其触发boot start过程以及获取新的osdmap
void MDSRank::replay_start()
{
dout(1) << "replay_start" << dendl;
if (is_standby_replay())
standby_replaying = true;
// 解释见上方
calc_recovery_set();
// Check if we need to wait for a newer OSD map before starting
// 触发从第一阶段开始的boot start(boot start共分4个阶段,每个阶段完成后会自动调用下一阶段)
Context *fin = new C_IO_Wrapper(this, new C_MDS_BootStart(this, MDS_BOOT_INITIAL));
// 根据最后一次失败的osdmap的epoch获取新的osdmap
bool const ready = objecter->wait_for_map(
mdsmap->get_last_failure_osd_epoch(),
fin);
// 获取到了osdmap之后则已经ready去replay了,调用boot_start进行replay
if (ready) {
delete fin;
boot_start();
} else {
dout(1) << " waiting for osdmap " << mdsmap->get_last_failure_osd_epoch()
<< " (which blacklists prior instance)" << dendl;
}
}
BOOT START
- 发生在standby mds进行actual replay之前
- 从journal中读取inode table、session map、purge queue、openfile table、snap table加载到cache中,创建recovery thread、submit thread
- cache中新建0x01和0x100+rank id的两个inode,其中0x01为根目录inode
- 调用mdlog进行replay,其中会启动一个replay线程完成actual replay步骤
ACTUAL REPLAY
replay线程的逻辑:
while(1)
{
1、读取一条journal记录,如果满足条件则flush
2、解码成logEvent格式
3、replay:根据journal信息在内存中重建CInode,CDir,CDentry等信息,并根据journal内容对dentry进行各种设置
}
UP:RECONNECT
BEFORE CLIENT RECONNECT
从osdmap获取黑名单
以某种方式通知非黑名单的client发起重连(未关注)
MDSRank::reconnect_start():
void MDSRank::reconnect_start()
{
dout(1) << "reconnect_start" << dendl;
if (last_state == MDSMap::STATE_REPLAY) {
reopen_log();
}
// Drop any blacklisted clients from the SessionMap before going
// into reconnect, so that we don't wait for them.
// 通过osdmap获取blacklist(命令行下可通过ceph osd blacklist ls查看),并与
// sessionmap进行对比,如果sessionmap中存在blacklist中的client,则kill掉这些session,并且不对其进行reconnect
objecter->enable_blacklist_events();
std::set<entity_addr_t> blacklist;
epoch_t epoch = 0;
objecter->with_osdmap([&blacklist, &epoch](const OSDMap& o) {
o.get_blacklist(&blacklist);
epoch = o.get_epoch();
});
auto killed = server->apply_blacklist(blacklist);
dout(4) << "reconnect_start: killed " << killed << " blacklisted sessions ("
<< blacklist.size() << " blacklist entries, "
<< sessionmap.get_sessions().size() << ")" << dendl;
if (killed) {
set_osd_epoch_barrier(epoch);
}
// 对其他的sessionmap中的合法的client进行reconnect,最终是由client发起reconnect
server->reconnect_clients(new C_MDS_VoidFn(this, &MDSRank::reconnect_done));
finish_contexts(g_ceph_context, waiting_for_reconnect);
}
HANDLE CLIENT REPLAY REQ
在切换之前可能会有client有未完成的元数据请求,在切换后这些client会重新发送replay请求或者retry请求(不准确)到新的mds,新mds则记录这些client的信息(need clientreplay)
void Server::dispatch(const Message::const_ref &m)
{
......
// 满足条件的client加入到replay_queue中,replay_queue不为空则需要经历client_replay阶段
if (queue_replay) {
req->mark_queued_for_replay();
mds->enqueue_replay(new C_MDS_RetryMessage(mds, m));
return;
}
}
......
}
HANDLE CLIENT RECONNECT
处理client重连请求,重新建立session,并遍历client的caps:
1)client caps对应inode在cahce中,则直接在cahce中重建caps
2)client caps对应的inode不在cache中,则先记录下来
Server::handle_client_reconnect部分代码:
UP:REJOIN
-
打开openfile table中的所有inode,记录在cache中的opening inode map中
(前者是用于加速切换过程的,后者是真正维护的opening inode) -
处理reconnect阶段记录的caps,根据reconnect阶段记录的caps、session等信息,在cache中为这些client重建caps
-
遍历cache中的inode和其对应的所有可写client(inode cahce中维护了每个inode有哪些client可写以及可写的范围),如果某个client可写但是没有caps则记录下来
bool MDCache::process_imported_caps()
{
// 按梯度依次打开inode,通过mdcache->open_ino
/* 共有4种state:
enum {
DIR_INODES = 1,
DIRFRAGS = 2,
FILE_INODES = 3,
DONE = 4,
};
根据此pr介绍:https://github.com/ceph/ceph/pull/20132
For inodes that need to open for reconnected/imported caps. First open
directory inodes that are in open file table. then open regular inodes
that are in open file table. finally open the rest ones.
*/
if (!open_file_table.is_prefetched() &&
open_file_table.prefetch_inodes()) {
open_file_table.wait_for_prefetch(
new MDSInternalContextWrapper(mds,
new FunctionContext([this](int r) {
ceph_assert(rejoin_gather.count(mds->get_nodeid()));
process_imported_caps();
})
)
);
return true;
}
// reconnect阶段处理client reconnect请求的时候,那些有caps但是不在cache中的inode会加到cap_imports中
for (auto p = cap_imports.begin(); p != cap_imports.end(); ++p) {
CInode *in = get_inode(p->first);
// 如果在caps_imports中的inode则从cap_imports_missing中去除
if (in) {
ceph_assert(in->is_auth());
cap_imports_missing.erase(p->first);
continue;
}
if (cap_imports_missing.count(p->first) > 0)
continue;
cap_imports_num_opening++;
// 对所有在cap_imports但不在inode_map和cap_imports_missing中的inode执行open_ino操作
dout(10) << " opening missing ino " << p->first << dendl;
open_ino(p->first, (int64_t)-1, new C_MDC_RejoinOpenInoFinish(this, p->first), false);
if (!(cap_imports_num_opening % 1000))
mds->heartbeat_reset();
}
if (cap_imports_num_opening > 0)
return true;
// called by rejoin_gather_finish() ?
// 初次进入rejoin阶段时在rejoin_start函数中将本节点加入rejoin_gather中,所以rejoin时
// 在send rejoin之前是不会走此分支的
if (rejoin_gather.count(mds->get_nodeid()) == 0) {
// rejoin_client_map在处理client reconnect时填充,rejoin_session_map在一开始是为空的
if (!rejoin_client_map.empty() &&
rejoin_session_map.empty()) {
// https://github.com/ceph/ceph/commit/e5457dfbe21c79c1aeddcae8d8d013898343bb93
// 为rejoin imported caps打开session
C_MDC_RejoinSessionsOpened *finish = new C_MDC_RejoinSessionsOpened(this);
// prepare_force_open_sessions中会根据rejoin_client_map来填充finish->session_map
version_t pv = mds->server->prepare_force_open_sessions(rejoin_client_map,
rejoin_client_metadata_map,
finish->session_map);
ESessions *le = new ESessions(pv, std::move(rejoin_client_map),
std::move(rejoin_client_metadata_map));
mds->mdlog->start_submit_entry(le, finish);
mds->mdlog->flush();
rejoin_client_map.clear();
rejoin_client_metadata_map.clear();
return true;
}
// process caps that were exported by slave rename
// 多mds相关的,不考虑
for (map<inodeno_t,pair<mds_rank_t,map<client_t,Capability::Export> > >::iterator p = rejoin_slave_exports.begin();
p != rejoin_slave_exports.end();
++p) {
......
}
rejoin_slave_exports.clear();
rejoin_imported_caps.clear();
// process cap imports
// ino -> client -> frommds -> capex
// 遍历cap_imports中的且已经存在于cache中的inode
for (auto p = cap_imports.begin(); p != cap_imports.end(); ) {
CInode *in = get_inode(p->first);
if (!in) {
dout(10) << " still missing ino " << p->first
<< ", will try again after replayed client requests" << dendl;
++p;
continue;
}
ceph_assert(in->is_auth());
for (auto q = p->second.begin(); q != p->second.end(); ++q) {
Session *session;
{
// 寻找该inode也有对应的session
auto r = rejoin_session_map.find(q->first);
session = (r != rejoin_session_map.end() ? r->second.first : nullptr);
}
for (auto r = q->second.begin(); r != q->second.end(); ++r) {
if (!session) {
if (r->first >= 0)
(void)rejoin_imported_caps[r->first][p->first][q->first]; // all are zero
continue;
}
//添加caps并设置,一份添加到CInode::client_caps,一份添加到MDCache::reconnected_caps
Capability *cap = in->reconnect_cap(q->first, r->second, session);
add_reconnected_cap(q->first, in->ino(), r->second);
// client id>=0,即合法client id,client_t默认构造为-2
if (r->first >= 0) {
if (cap->get_last_seq() == 0) // don't increase mseq if cap already exists
cap->inc_mseq();
// 构建caps
do_cap_import(session, in, cap, r->second.capinfo.cap_id, 0, 0, r->first, 0);
// 并将建立的caps存在rejoin_imported_caps中
Capability::Import& im = rejoin_imported_caps[r->first][p->first][q->first];
im.cap_id = cap->get_cap_id();
im.issue_seq = cap->get_last_seq();
im.mseq = cap->get_mseq();
}
}
}
cap_imports.erase(p++); // remove and move on
}
}
else {
trim_non_auth();
ceph_assert(rejoin_gather.count(mds->get_nodeid()));
rejoin_gather.erase(mds->get_nodeid());
ceph_assert(!rejoin_ack_gather.count(mds->get_nodeid()));
// 如果rejoin被pending了,则重新发起rejoin
maybe_send_pending_rejoins();
}
return false;
}
void MDCache::rejoin_send_rejoins()
{
map<mds_rank_t, MMDSCacheRejoin::ref> rejoins;
// if i am rejoining, send a rejoin to everyone.
// otherwise, just send to others who are rejoining.
for (set<mds_rank_t>::iterator p = recovery_set.begin();
p != recovery_set.end();
++p) {
if (*p == mds->get_nodeid()) continue; // nothing to myself!
if (rejoin_sent.count(*p)) continue; // already sent a rejoin to this node!
if (mds->is_rejoin())
// 正常走这里,rejoins表里记录recovery_set中每个mds的rank编号和MMDSCacheRejoin
rejoins[*p] = MMDSCacheRejoin::create(MMDSCacheRejoin::OP_WEAK);
else if (mds->mdsmap->is_rejoin(*p))
rejoins[*p] = MMDSCacheRejoin::create(MMDSCacheRejoin::OP_STRONG);
}
// 根据cap_exports来填充rejoins,单活mds不涉及cap_exports
if (mds->is_rejoin()) {
......
}
// check all subtrees
// 重建子树,单活mds无子树划分
for (map<CDir*, set<CDir*> >::iterator p = subtrees.begin();
p != subtrees.end();
++p) {
......
}
// rejoin root inodes, too
for (auto &p : rejoins) {
if (mds->is_rejoin()) {
// weak
......
}
if (!mds->is_rejoin()) {
// i am survivor. send strong rejoin.
// note request remote_auth_pins, xlocks
}
UP:CLIENTREPLAY
对rejoin最后记录的那些文件inode进行recover
clientreplay主要是对那些切换前有些client的请求原mds已经回复了,但是还没有存journal(会是哪些请求?猜测是client cache写?)。这些请求在reconneect阶段重新发起,也就是前面提到的handle client replay req。这个阶段记录下的client请求信息在replay_queue中,在clientreplay阶段对这些请求进行replay,并对涉及的inode进行recover。
总结
- mds的主从切换是由mon调度,mdsmap驱动,涉及mon、osd、mds、cephfs client等多个组件协调完成
- mds热备(standby-replay)会尽可能同步cache,可以加速切换过程,且目前看来没什么弊端
- 切换流程
- up:replay:读取rados中的比自己的cache更新的journal,将这些journal解码并回放,完善cache
- up:reconnect:通知所有非黑名单的client进行重连,client端发起重连请求,携带自己的caps、openfile、path等众多信息。mds处理这些请求后重建与合法client的session,并对在cache中的inode重建caps,否则记录
- up:rejoin:重新打开open file记录在cache中,并对reconnect阶段记录的caps进行处理
- up:clientreplay(非必经状态):重放恢复那些mds已经回复了,但是还没有存journal的请求涉及的inode
版权声明:本文为jiang4357291原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。