前言
项目中要用到人头的数据集,而在以前文章中的open image数据集中的人头大多没有俯拍图片,不太适合我的应用场景。一次偶然的机会,在guthub aditya-vora/FCHD-Fully-Convolutional-Head-Detector中发现了brainwash数据集。它的标注文件格式与yolo标注格式有很大的不同,本文旨在实现两者的转换。
准备
- python3
- cmd
- brainwash数据集 网盘链接:https://pan.baidu.com/s/1Vgr6jZByU41TPd2tkiPMwA 提取码:rnk3
brainwash
brainwash数据集是一个密集人头检测数据集,拍摄的是在一个咖啡馆里出现的人群,然后对这群人进行标注而得到的数据集。包含三个部分,训练集:10769张图像81975个人头,验证集:500张图像3318个人头。测试集:500张图像5007个人头。本文只讨论它的训练集。

它的标注文件在几个idl文件中, 如训练集在brainwash_train.idl中,它们的标注格式如下:"图片路径":标注。其中每个box用小括号括起来,坐标与坐标之间用逗号隔开,box与box之间也是用逗号隔开,每一张图片独自占一行,结尾用分号隔开。
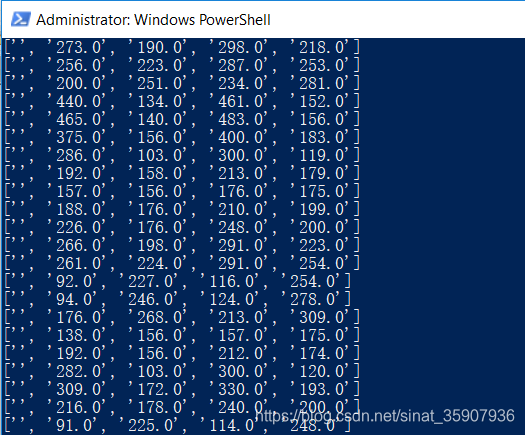
"brainwash_11_13_2014_images/04231500_640x480.png": (316.0, 132.0, 332.0, 150.0), (201.0, 163.0, 221.0, 185.0), (136.0, 167.0, 156.0, 186.0), (349.0, 144.0, 372.0, 166.0), (606.0, 249.0, 639.0, 290.0);
"brainwash_11_13_2014_images/04232000_640x480.png": (485.0, 233.0, 527.0, 273.0), (48+3.0, 198.0, 513.0, 230.0), (291.0, 199.0, 326.0, 239.0), (208.0, 168.0, 242.0, 202.0), (137.0, 168.0, 160.0, 189.0), (197.0, 165.0, 215.0, 186.0), (317.0, 131.0, 332.0, 149.0);
"brainwash_11_24_2014_images/00000500_640x480.jpg": (385.0, 132.0, 399.0, 143.0), (152.0, 162.0, 168.0, 181.0), (120.0, 171.0, 140.0, 196.0), (468.0, 171.0, 490.0, 190.0);
"brainwash_11_24_2014_images/00001000_640x480.jpg": (160.0, 156.0, 176.0, 175.0), (121.0, 175.0, 140.0, 196.0), (357.0, 159.0, 379.0, 184.0);接下来要做的事就是根据这个数据格式把每一行的数据拿出来,然后改成yolo格式:
<类别> <归一化中心坐标x> <归一化中心坐标y> <归一化图片w> <归一化图片h>
<类别> <归一化中心坐标x> <归一化中心坐标y> <归一化图片w> <归一化图片h>
........
<类别> <归一化中心坐标x> <归一化中心坐标y> <归一化图片w> <归一化图片h>
然后把这些放在以图片名命名的txt文件中。
格式转换
分割:
经过观察,我们发现有的东西是不需要的,而有的东西是应该作为文件名,而有的东西是应该作为文件内容,所以我们首先应该进行分割,然后对每一部分做不同处理。我先将每一行分割成两部分,即图片路径部分和图片标注部分,注意到两部分用的“:”进行分割,而每一行末尾却用的“;”分割,我们可以先将“:”替换成“;”然后按照“;”进行分割,就可以去掉这两个多余符号。
import os
idl_file_dir = "brainwash_train.idl" #相对地址
txt_files_dir = "txt_files"
if not os.path.exists(txt_files_dir):
os.mkdir(txt_files_dir) #用于存生成的txt文件
f1=open(idl_file_dir,'r+')
lines=f1.readlines()
#print(range(len(lines)))
for i in range(len(lines)):
line = lines[i]
line = line.replace(":",";") #用;替换:
#print(line)执行上述操作之后整个标注文件就变成了两个部分,路径存在line.split(";")[0]中,标注存在line.split(";")[1]中。先处理路径部分,注意到路径两边有分号,而这时多余符号,所以先把它删除,然后再通过“/”进行分割便可得到图片名字,最后再通过“.”进行分割便可得到不带后缀的图片名字。当然,这个名字也是后面标注文件的不带后缀文件名。
img_dir = line.split(";")[0]
#print(img_dir)
img_boxs = line.split(";")[1]
img_dir = img_dir.replace('"',"") #删除分号
#print(img_dir)
img_name = img_dir.split("/")[1]
txt_name = img_name.split(".")[0] #得到后缀名与文件名
img_extension = img_name.split(".")[1]
#print(txt_name)
#print(img_extension)执行上述操作之后,文件名和后缀名都有了,前者将是标注文件的文件名,后者将成为一种筛选条件。现在,我们来分割标注部分,标注部分长下面这个样子。 首先把全部的“,”删除(因为原标注文件每个“,”前都有空格,如果把“,”换成空格,那么最后分割之后会多出空格项)。然后删除“(”的括号,最后用“)”分割不同的框。
(316.0, 132.0, 332.0, 150.0), (201.0, 163.0, 221.0, 185.0), (136.0, 167.0, 156.0, 186.0), (349.0, 144.0, 372.0, 166.0), (606.0, 249.0, 639.0, 290.0);
(485.0, 233.0, 527.0, 273.0), (48+3.0, 198.0, 513.0, 230.0), (291.0, 199.0, 326.0, 239.0), (208.0, 168.0, 242.0, 202.0), (137.0, 168.0, 160.0, 189.0), (197.0, 165.0, 215.0, 186.0), (317.0, 131.0, 332.0, 149.0);
(385.0, 132.0, 399.0, 143.0), (152.0, 162.0, 168.0, 181.0), (120.0, 171.0, 140.0, 196.0), (468.0, 171.0, 490.0, 190.0);
(160.0, 156.0, 176.0, 175.0), (121.0, 175.0, 140.0, 196.0), (357.0, 159.0, 379.0, 184.0); img_boxs = img_boxs.replace(",","") #删除“,”
#print(img_boxs)
img_boxs = img_boxs.replace("(","") #删除“(”
img_boxs = img_boxs.split(")") #删除“)”
#print(img_boxs)到现在基本上已经将数据分割出来了,一张图片一个img_boxs,每一个框都是img_boxs的一个维度,框的个数也就是img_boxs的总维度。注意到每个img_boxs最后一项都是空格项,通过只遍历到len(img_boxs)-1减一来消除这个项(不然后面访问img_boxs[m],m>0时会出现list index out of range的错误)。
if(img_extension == 'jpg'):
for n in range(len(img_boxs)-1): #消除空格项影响
box = img_boxs[n]
box = box.split(" ")
#print(box)
#print(box[4])

最后一步就是将brainwash的[xmin, ymin, xmax, ymax]格式转换成yolo的<类别> <归一化中心坐标x> <归一化中心坐标y> <归一化图片w> <归一化图片h>,需要将算出归一化的坐标,归一化的宽高,然后将一幅图像的标注文件添加到以图片名命名的txt文件中,到此数据类型转换完成。结果如下图所示。完整代码见附录。
with open(txt_files_dir+"/"+txt_name+".txt",'a') as f:
f.write(' '.join(['0', str((float(box[1]) + float(box[3]))/(2*640)),str((float(box[2]) + float(box[4]))/(2*480)),str((float(box[3]) - float(box[1]))/640),str((float(box[4]) - float(box[2]))/480)])+'\n')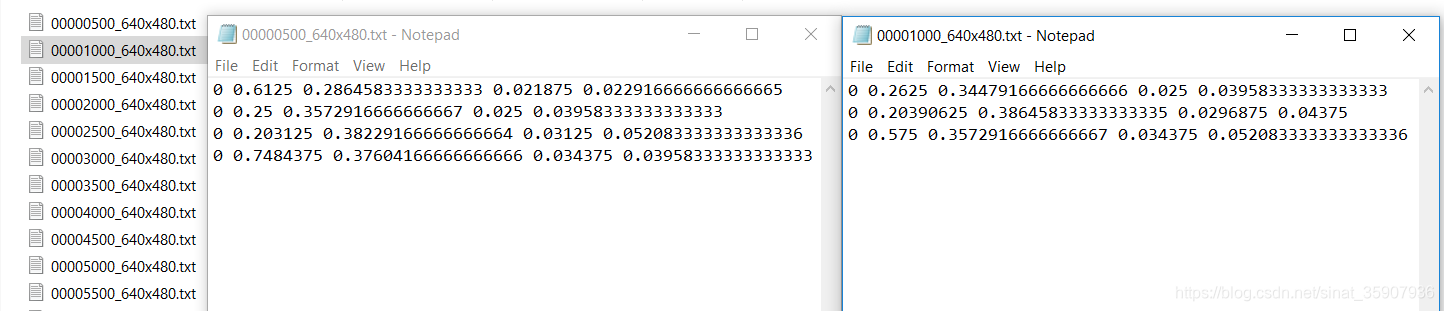
yolo_mark验证
yolo_mark的标注和图片是在同一个文件夹内的,而我们现在标注和图片在不同的文件夹里,而且这里的标注是经过筛选的,所以用我在另一篇文章里写的脚本可以很容易的以标注为基准将两个文件夹的内容合并到一起。然后打开yolo_mark验证,yolo_mark使用方法参见我的另一篇文章。随机参看了两张,可以看到标注没有问题,说明转换成功。
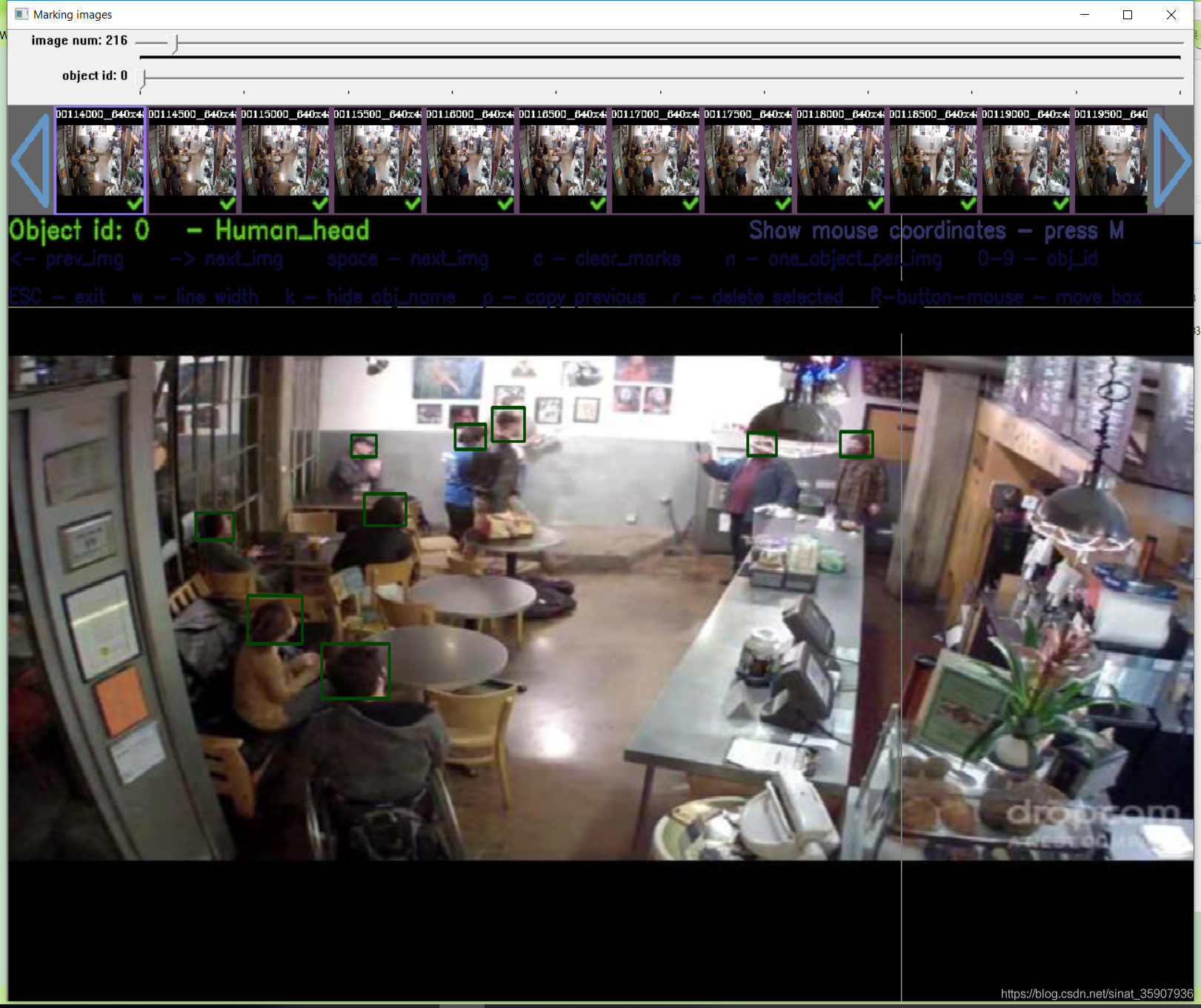
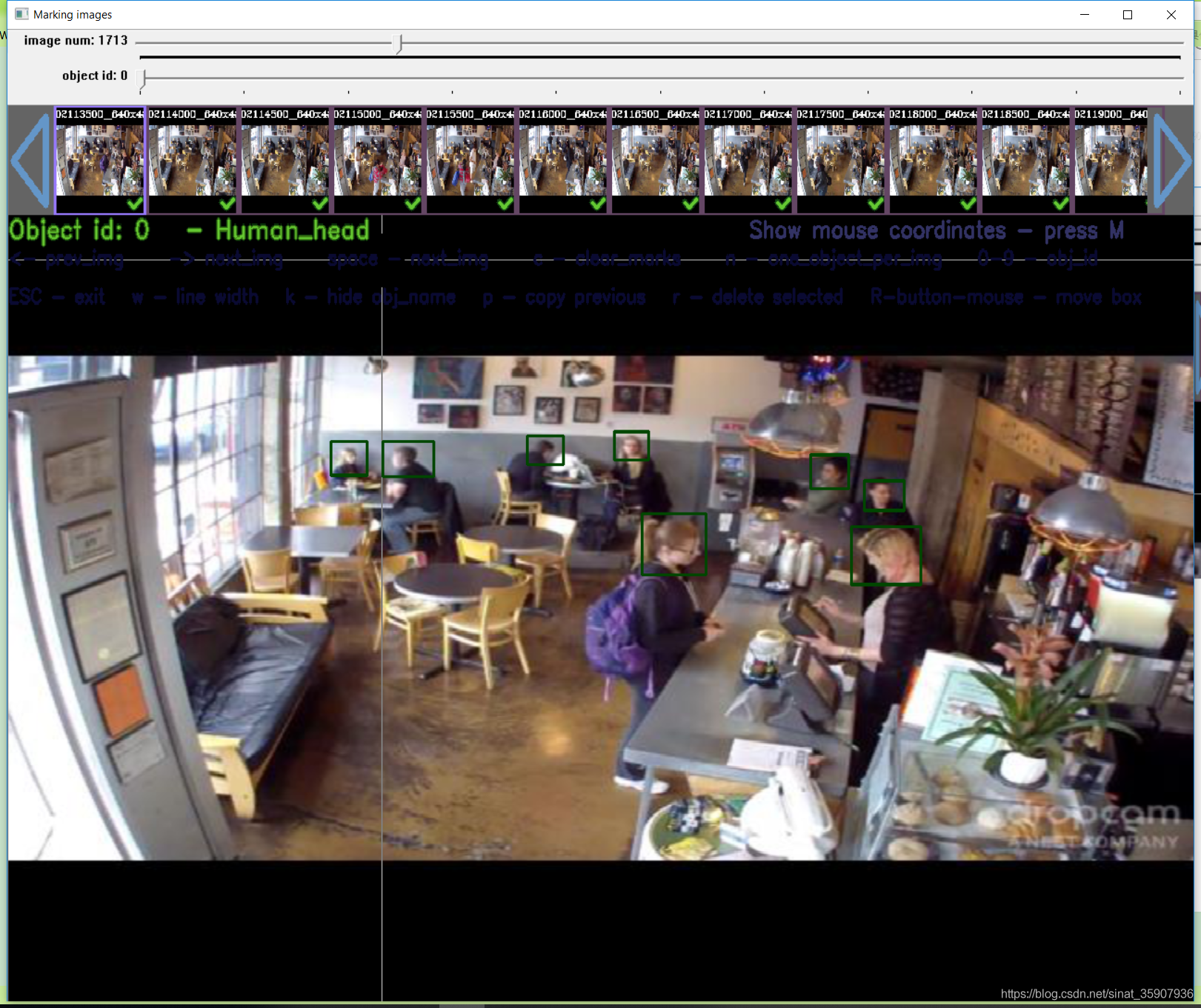
小结
数据标注格式间的转换,无非就是按照一定的规则切分数据,然后通过计算,重新排列数据而得到另一种标注数据,以上,如果有朋友有缘读到本文,真的是倍感荣幸,如果有什么问题欢迎在下方留言讨论,我看到后就会回复。
参考
https://blog.csdn.net/sinat_35907936/article/details/88911770
https://blog.csdn.net/sinat_35907936/article/details/89605978
https://blog.csdn.net/sinat_35907936/article/details/89086081
http://arxiv.org/abs/1506.04878
附录
import os
idl_file_dir = "brainwash_train.idl"
txt_files_dir = "txt_files"
if not os.path.exists(txt_files_dir):
os.mkdir(txt_files_dir)
f1=open(idl_file_dir,'r+')
lines=f1.readlines()
#print(range(len(lines)))
for i in range(len(lines)):
line = lines[i]
line = line.replace(":",";")
#print(line)
img_dir = line.split(";")[0]
#print(img_dir)
img_boxs = line.split(";")[1]
img_dir = img_dir.replace('"',"")
#print(img_dir)
img_name = img_dir.split("/")[1]
txt_name = img_name.split(".")[0]
img_extension = img_name.split(".")[1]
#print(txt_name)
#print(img_extension)
img_boxs = img_boxs.replace(",","")
#print(img_boxs)
img_boxs = img_boxs.replace("(","")
img_boxs = img_boxs.split(")")
#print(img_boxs)
if(img_extension == 'jpg'):
for n in range(len(img_boxs)-1):
box = img_boxs[n]
box = box.split(" ")
#print(box)
#print(box[4])
with open(txt_files_dir+"/"+txt_name+".txt",'a') as f:
f.write(' '.join(['0', str((float(box[1]) + float(box[3]))/(2*640)),str((float(box[2]) + float(box[4]))/(2*480)),str((float(box[3]) - float(box[1]))/640),str((float(box[4]) - float(box[2]))/480)])+'\n')
