本篇博客主要以员工贡献度为例,分析不同菜品之间是否存在相关性。最典型的应用就是:啤酒和尿布销售之间的联系
一、周期性分析
探索某个变量是否随着时间变化而呈现出某种周期性变化的趋势。时间尺度相对较长的周期性趋势有:年度周期性趋势,季节性周期性趋势,相对较短的有月度周期性趋势,周度周期性趋势,甚至更短的天,小时的周期性趋势。
import pandas as pd
import matplotlib.pyplot as plt
df_normal=pd.read_excel("D:/S072003Python/05DataMineML/catering_sale.xls")#读入数据
plt.figure(figsize=(20,9))
plt.plot(df_normal["日期"],df_normal["销量"])
plt.xlabel("日期")
plt.ylabel("销量")
# 设置x轴刻度间隔
x_major_locator = plt.MultipleLocator(7)
ax = plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.title("销售趋势")
plt.xticks(rotation=30)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.show() # 展示图片
# 不正常销售趋势分析 - 这里的异常数据其实是使用随机数伪造出来的
df_abnormal = pd.read_excel("D:/S072003Python/05DataMineML/catering_sale (2).xls")
plt.figure(figsize=(20, 9))
plt.xticks(rotation=30)
plt.plot(df_abnormal["日期"],df_abnormal["销量2"]-np.random.randint(1000)) #随机数 np.rand
plt.xlabel("日期")
plt.ylabel("销量2")
# 设置x轴刻度间隔
x_major_locator = plt.MultipleLocator(7)
ax = plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.title("不正常销量趋势")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.show() # 展示图片

二、贡献性分析
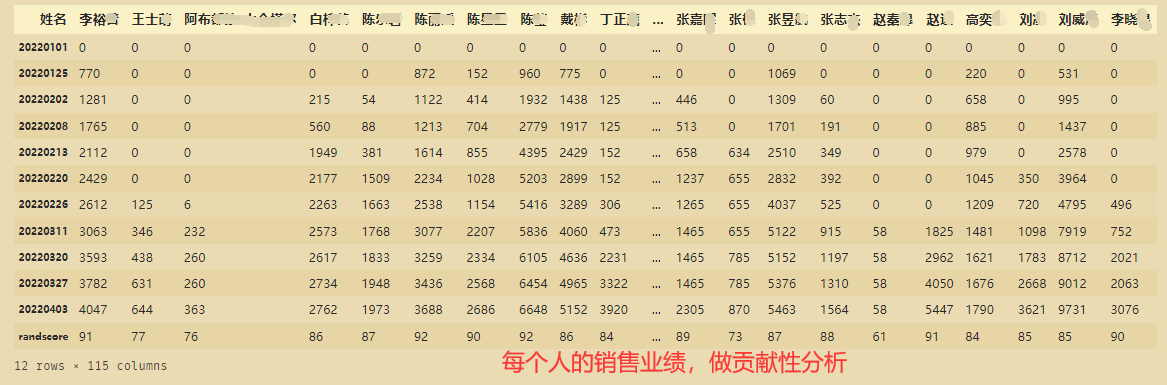
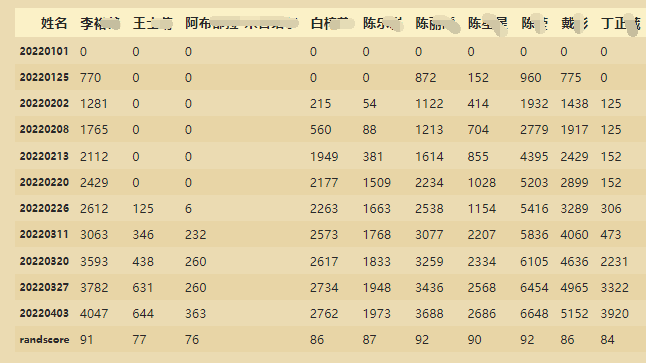
取出到2022年4月3号为止,每个人累计总销售业绩,并进行排序
dfsort=df['20220403']
dfsort2=dfsort.copy()
dfsort2.sort_values(ascending=False,inplace=True)
dfsort2
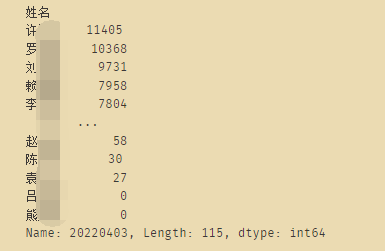
plt.figure(figsize=(20,10))
dfsort2.plot(kind='bar',color='g',alpha=0.6,width=0.7)
plt.ylabel('销售业绩')
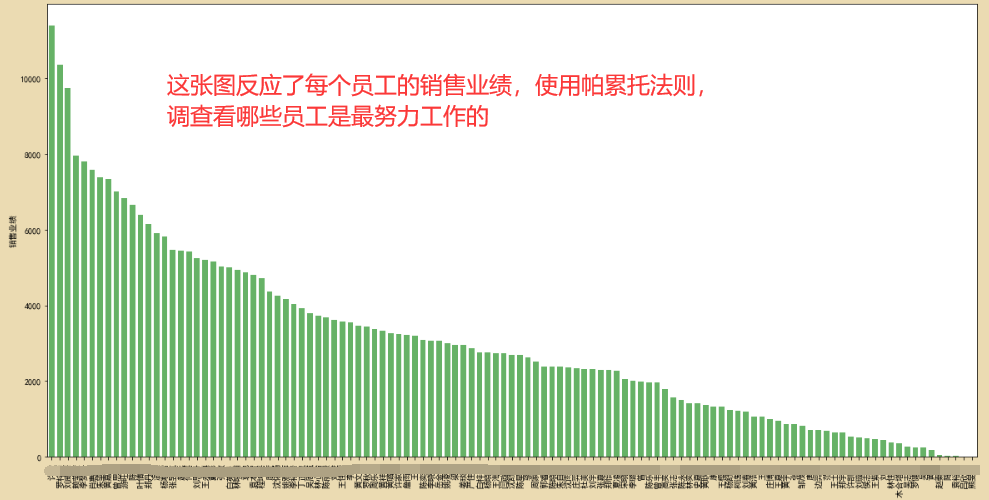
根据帕累托法则,我们需要找出贡献度80%的员工,那么这些员工就是努力工作的员工,当80%这条线越靠近右边,则说明努力的员工越多。如果线越靠近左边,则说明大部分员工的贡献度都很低,根据不同的情况,公司的人力资源管理就需要有不同的解决方法。
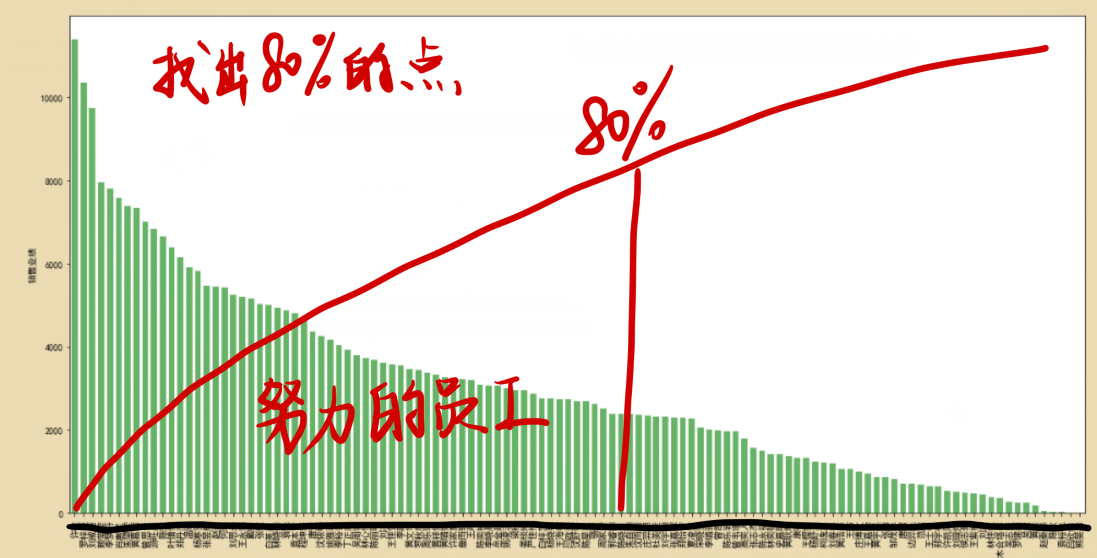
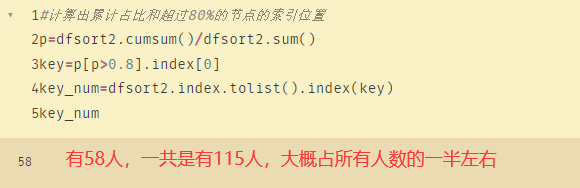
#计算出累计占比和超过80%的节点的索引位置
p=dfsort2.cumsum()/dfsort2.sum()
key=p[p>0.8].index[0]
key_num=dfsort2.index.tolist().index(key)
key_num
找出核心的产出人员:
#核心产出的人员是
key_studys=dfsort2.loc[:key]
key_studys
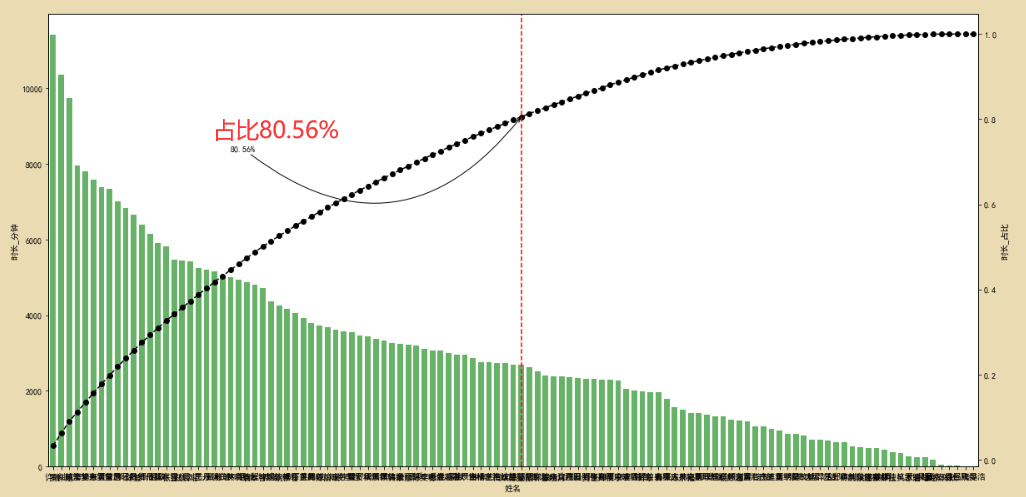
绘图:
plt.figure(figsize=(20,10))
dfsort2.plot(kind='bar',color='g',alpha=0.6,width=0.7)
plt.ylabel('时长_分钟')
p.plot(style='--ko',secondary_y=True)
plt.axvline(key_num,color='r',linestyle='--')
# plt.text(key_num+0.5,p[key],'累计占比为:%.3f%%' % (p[key]*100),color='r')
plt.annotate(format(p[key_num],'.2%'),xy=(key_num,p[key_num]),xytext=(22,p[key_num]*0.9),arrowprops=dict(arrowstyle="->",connectionstyle="arc3,rad=0.5"))
# dfsort2.plot(kind='bar',color='g',alpha=0.6,width=0.7)
plt.ylabel('时长_占比')
三、相关性分析
1、探究不同菜品之间的相关性
还是拿餐饮的菜品,来分析不同菜品之间是否存在相关性。
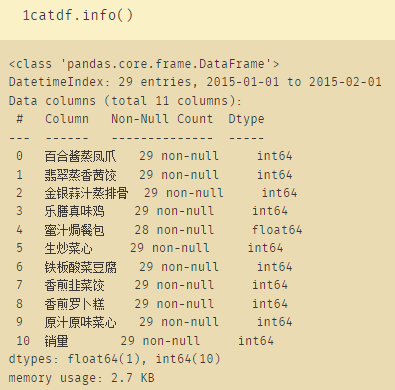
a=catdf.corr()
b=catdf.corr()['生炒菜心']
b
就类似于推荐系统,通过相关性分析,可以为用户继续推荐(想到了淘宝的猜你喜欢(≧∇≦)ノ)

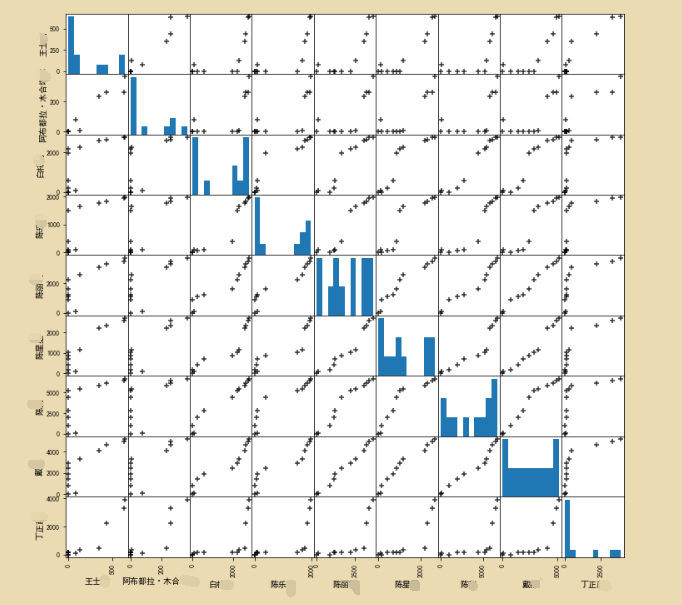
2、探究不同学生之间的相关性
选取十名同学的学习时长,看看同学直接是否有影响。
#数据集太大会导致耗时过长,调整切片
pd.plotting.scatter_matrix(dfddiffT.iloc[:,1:10],figsize=(12,12),
c='k',
marker='+',
diagonal='hist',
alpha=0.8,
range_padding=0.1)