点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :新智元
强化学习可以说是最贴近人类学习过程的AI了,通过不断试错进行反馈。由于强化学习在各大领域都取得了非凡成就,也引得巨头们纷纷入局,发论文、办开源节,一文带你回顾2021年各大巨头的工作。
目前机器学习中噱头最高,最吸引人的的领域之一就是强化学习,它的应用范围十分广泛,从数据处理、机器人、制造、推荐系统、能源到围棋、电子游戏等无所不能。
强化学习(RL)与其他算法的不同之处在于它不依赖于历史数据集,它像人类一样通过反复试验学习,也更接近人类的学习过程。
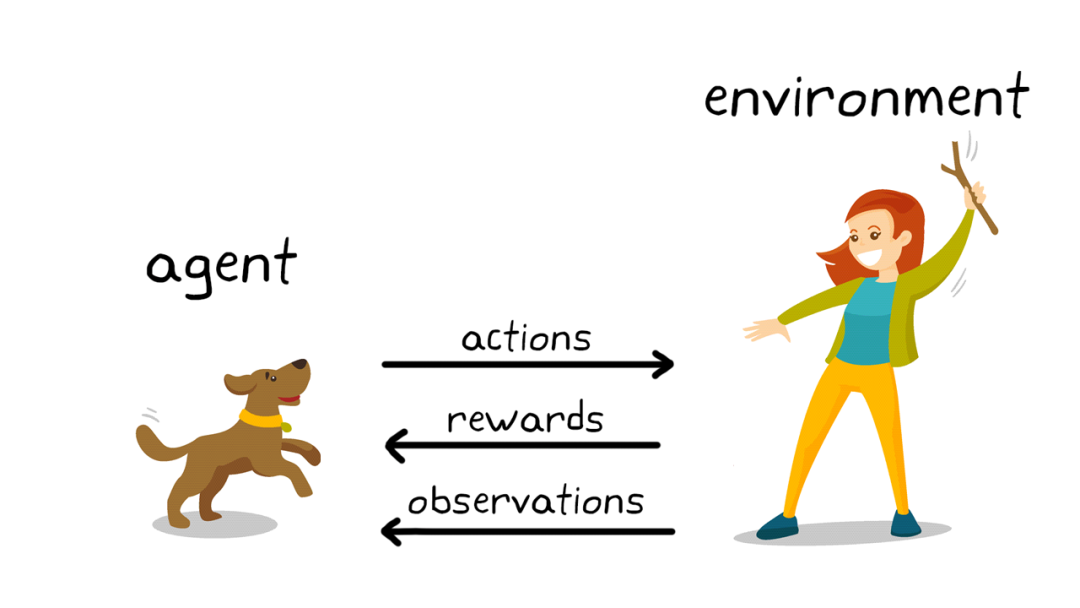
强化学习理论受到行为主义心理学启发,侧重在线学习并试图在探索-利用(exploration-exploitation)间保持平衡。不同于监督学习和非监督学习,强化学习不要求预先给定任何数据,而是通过接收环境对动作的奖励(反馈)获得学习信息并更新模型参数。
强化学习问题在信息论、博弈论、自动控制等领域有得到讨论,被用于解释有限理性条件下的平衡态、设计推荐系统和机器人交互系统。
一些复杂的强化学习算法在一定程度上具备解决复杂问题的通用智能,可以在围棋和电子游戏中达到人类水平。
过去几年在理解和改进RL方面取得了更快的进展,科技界的那些big name,无论是Facebook、Google、Deepmind、Amazon还是Microsoft,他们都在投入大量的时间、金钱和精力来推动RL的创新。
首先是机器人领域,为了使机器人对人类更有用,它们需要执行各种各样的任务。但即使是对使用离线(offline)强化学习的任务进行训练,也需要大量的时间和巨大的计算成本。
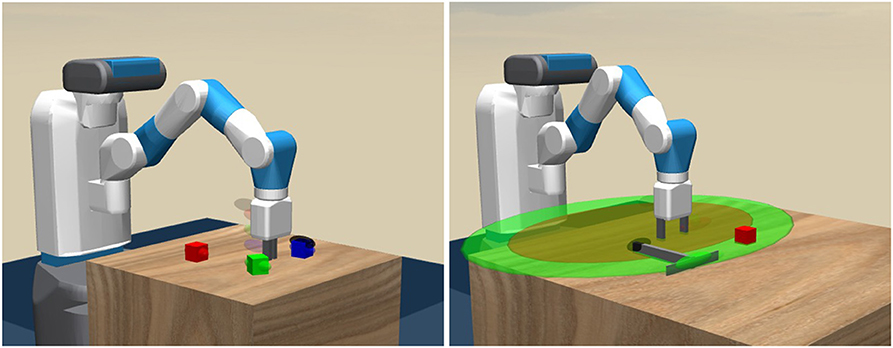
为了解决这个问题,谷歌推出过MT-OPT和可操作模型(Actionable Models)。MT-OPT是一个用于自动数据采集和多任务RL训练的多任务RL系统,后者是一个用于采集真实机器人上各种任务的场景的数据采集机制,能够展示多任务RL的应用成果。
他们还可以帮助机器人更快地学习新任务。
而作为强化学习领域的领导者,DeepMind今年也发布了一些工作,例如它发布了RGB-stacking,可以作为视觉机器人操作的benchmark,主要使用强化学习的方式来训练机器人手臂以平衡和堆叠不同形状的物体。
由于用到的物体是多种多样的,并且所进行的经验评估的数量也使这一强化学习型项目独树一帜。
整个学习pipeline分为三个阶段:
1、使用一个现成可用的RL算法进行仿真训练
2、在只使用真实观察的新策略来仿真训练
3、使用该策略在真实机器人上收集数据,并由此提出改进策略。
在序列学习(Sequential Learning)方面,由于序列决策过程的实现(implementation)对那些致力于强化学习的人至关重要,所以为了简化这一过程,社交媒体巨头Facebook(现在叫Meta)推出了SaLinA。

SaLinA是PyTorch的扩展,在有监督和无监督的情况下都可以使用,并且能够与多CPU和多GPU兼容,这种方法可以在涉及大规模训练样本的系统中使用。
IBM 也在2021年加入了强化学习领域的战场。它发布了一个基于文本的游戏环境TextWorld Commonse(TWC),以解决强化学习注入常识的问题。该方法可以用于训练和评估具有特定常识的强化学习agent,这些知识涉及物体、属性和affordances,主要通过引入几个基线RL agent来解决序列决策问题。

在自监督学习(self-supervised learning)领域,也可以看到了新的学习方法的出现。Google发布了一种称为可逆感知(Reversibility-Aware) RL的方法,在自我监督的RL过程中添加了一个单独的可逆性估计组件。
例如在一个实验中,当玻璃从桌子高度掉下来撞到地板上时,它会碎。在这种情况下,玻璃从位置A(桌子的高度)到位置B(楼的高度),无论试验次数多少,A总是先于B碎。因此,当随机抽样事件对时,找到前置B的对的概率为1,这就表明是一个不可逆转的顺序。
相反,假设一个橡胶球掉下来。在这种情况下,球将从A开始,下降到B,然后(大约)返回到A,也就是会弹跳一次。因此,当对事件进行采样时,找到前缀B仅为0.5的对的概率(与随机对显示在前缀A之前的B的概率相同),并指示出一个可逆的序列。
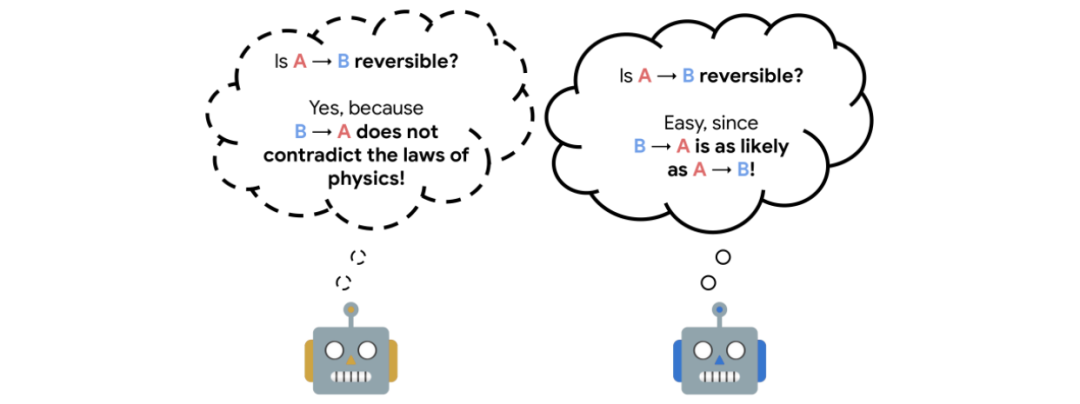
Google表示,这种方法提高了RL agent在包括Sokoban益智游戏在内多个任务上的性能。
强化学习对游戏也有着重要的影响。2021年年中,在强化学习机制的帮助下,深度学习模型可以在不借助任何人工干预的情况下自主进行竞技游戏。
之前的项目如 Alphazero在围棋、Shogi和Go上击败过世界冠军,但他们仍然需要对每一个游戏中单独接受训练,如果不从头开始重复RL程序,就无法学习新的游戏。

通过新的方法,agent能够快速适应新环境,更加灵活地应对新的游戏。这项研究的核心部分是深入研究RL在训练agent时,神经网络扮演的作用。
Google也一直致力于在游戏领域使用RL,2021年初时发布了一种不断进化的强化学习算法,展示了如何通过使用图表示(graph representation)和应用AutoML社区的优化技术来学习可分析解释和可生成的RL算法。

它使用正则化的进化(Regularized Evolution)来对一组简单的训练环境中的计算图进行演化,能够有助于在复杂的视觉环境(如Atari游戏)中更好地使用RL算法。

随着RL 技术的发展,这一领域的也必然会在学生和专业社区中共同成长。
为了满足日益增长的需求,微软组织了强化学习开源节,向同学们介绍开源强化学习程序和软件开发。

来自伦敦大学学院(UCL)的深度学习研究团队为学生提供了现代强化学习的全面介绍,旨在使学生对马尔可夫决策过程、基于样本的学习算法、深度强化学习等主题有一个详细的了解。
虽然在过去几年里强化学习取得了重大进展,但强化学习还有很长的路要走。对于某些行业来说,强化学习的使用可能是会对行业产生重大影响。随着更多的研究进入RL,可以期待在不久的将来看到新的重大突破。
参考资料:
https://analyticsindiamag.com/what-happened-in-reinforcement-learning-in-2021/
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧
