点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :机器之心
这次英伟达发布的,是「元宇宙」开发工具。
元宇宙的最终解释权,还得看英伟达。
几个月前,真假黄仁勋的争论带火了「元宇宙」概念。11 月 9 日,GTC 大会再次开启,英伟达创始人兼 CEO 黄仁勋从自家虚拟的厨房中走来。
那这次是否是「真人」?

在刚刚结束的媒体采访环节中,黄仁勋直面人们的好奇:「Keynote 中的一切都是渲染的,没有真实物体,全部是虚拟的(Everything in the keynote was rendered,nothing was real,everything was virtual)。」
这一说法让接入电话的记者都为之一振。于是一位记者问道,「您刚才说一切都是虚拟的,包括您自己吗?」「哈哈哈,一切都是虚拟的,但除了我自己,我是真的。」黄仁勋补充道。看来,黄仁勋只是用这个大喘气给大家开个玩笑。
回顾此次 GTC Keynote,我们可以发现几个非常重要的点,比如元宇宙和加速计算。
拥抱元宇宙的 Q 版黄仁勋
「我将向大家介绍我们正在进行的重要计划,它将重塑我们所在行业,」黄仁勋说道。
英伟达展示过如何使用 Omniverse 来模拟仓库、工厂、物理与生物系统、5G 通信、机器人、自动驾驶汽车,现在最新的技术可以直接生成全功能的虚拟形象了。
这个 Q 版黄仁勋叫 Toy-Me,可以和人进行自然语言交流。

它使用了目前业界规模最大的预训练自然语言处理模型 Megatron 530B,「借用」了黄仁勋自己的声音、形象和讲话姿态,整个人也带光线追踪特效——最重要的是,所有一切都是实时生成的。几个月前,这还是无法实现的。
为了检验整个虚拟小人是不是真的有用,人们向它提出了几个不太简单的问题,都获得了让人满意的答案:

上知天文下知地理,还懂环境保护问题。
说「互联网改变了一切」现在看来是有些轻描淡写了,今天的我们一直互相连接。互联网本质上是这个世界的数字表达,主要是指 2D 的文本、语音、图像和视频信息。「这个事情要发生变化了,如今我们已经拥有创建全新 3D 世界或为物理世界建模的技术。在虚拟世界中,有真实的物理定律,当然也可以不遵守,」黄仁勋说道。「在那里我们可以是和朋友,也可以是和 AI 在一起。」
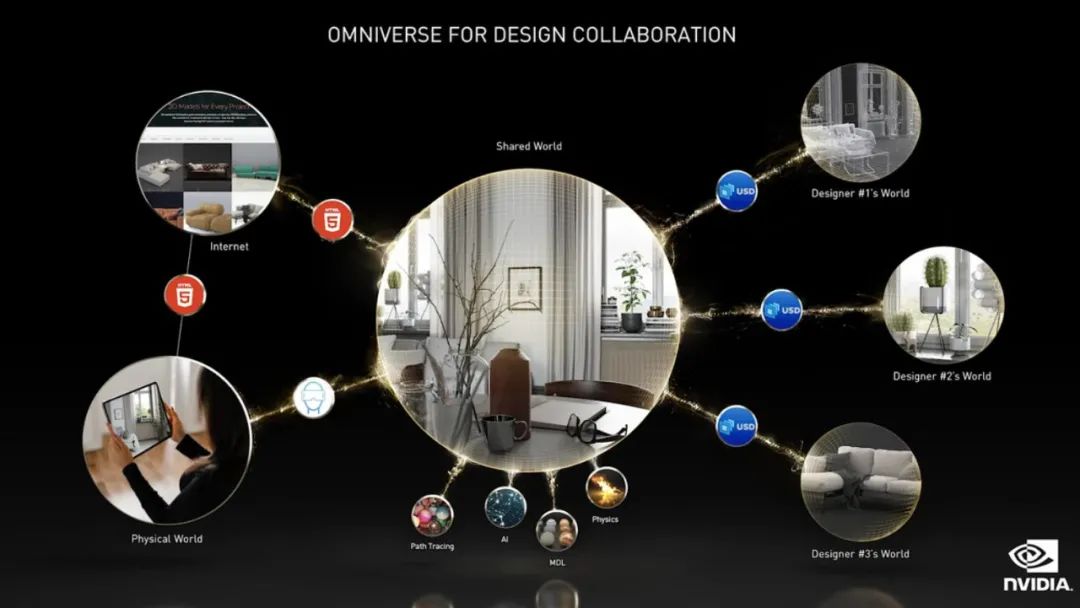
我们将像网络中跳转一样从一个世界切换到另一个世界,这个新世界的规模要比真实世界大得多。我们将购买到 3D 的商品,正如现在买首 2D 歌曲或买书一样。在这个世界中,我们也能购买、持有或出售房产、家具、汽车、奢侈品和艺术品。在虚拟世界中,人们将创造出比物理世界更加丰富多样的东西。
与游戏不同的是,Omniverse 是面向数据中心设计的,有朝一日或许可以形成全球的规模。Omniverse 的门户是「数字虫洞」,将人和计算机链接到 Omniverse 上,然后再联通所有虚拟世界。这些虚拟世界中,你可以设计飞机,运行虚拟工厂。「现实世界工厂的运行是虚拟世界的复制品,这就是数字孪生概念。」
在 Keynote 中,英伟达还展示了 Omniverse 的一系列新功能,包括 Showroom,负责展示图形、物理、材质和 AI。Farm,一个系统层,用于协调跨多系统,工作站、服务器、裸机或虚拟化的批处理作业。Omniverse AR 可以将图形串流到手机和 AR 眼镜上。Omniverse VR 是首款全帧率交互式光线追踪 VR。
11 天训练 GPT-3,Megatron 530B 推理时间降至半秒,老黄祭出大模型神器
构建虚拟世界中的 AI 需要构建强大的模型,并让它们具备实时的推理能力,这就需要与以往完全不同的技术了。
近年来,自然语言处理中基于 Transformer 的语言模型在大规模计算、大型数据集以及用于训练这些模型的高级算法和软件的推动下发展迅速。具有大量参数、更多数据和更多训练时间的语言模型可以获得更丰富、更细致的语言理解。因此,它们可以很好地泛化为有效的零样本(zero-shot)或少样本(few-shot)学习器,在许多 NLP 任务和数据集上具有很高的准确性。
在昨天的 GTC 大会上,NVIDIA 推出了为训练具有数万亿参数的语言模型而优化的 NVIDIA NeMo Megatron 框架、为新领域和语言进行训练的可定制大型语言模型(LLM)Megatron 530B 以及具有多 GPU、多节点分布式推理功能的 NVIDIA Triton 推理服务器。这些工具与 NVIDIA DGX 系统相结合,提供了一个可部署到实际生产环境的企业级解决方案,以简化大型语言模型的开发和部署。
「训练大型语言模型需要极大的勇气:耗资上亿美元的系统、持续数月在数 PB 数据上训练万亿参数模型,离不开强大的信念、深厚的专业知识和优化的堆栈,」黄仁勋在演讲中说到。因此,他们创建了一个专门训练拥有数万亿参数的语音、语言模型的框架——NeMo Megatron。NeMo Megatron 是在 Megatron 的基础上发展起来的开源项目,由 NVIDIA 研究人员主导,研究大型 Transformer 语言模型的高效训练。该框架已经经过优化,可水平扩展至大规模系统并保持很高的计算效率。

黄仁勋介绍说,他们的研究人员曾在 NVIDIA 的 500 节点 Selene DGX SuperPOD 上进行过测试,结果表明,NeMo Megatron 仅用了 11 天就完成了 GPT-3 的训练。此外,他们还和微软一起在 6 周内完成了 Megatron MT-NLG 5300 亿参数模型的训练。「借助 Nemo Megatron,任何公司都可以训练最先进的大型语言模型。」黄仁勋表示。
完成训练后,如何运行大型语言模型呢?这就要用到专门的推理服务器了。在生产环境中,大模型的推理需要极低的延迟才能达到可用的程度。「在高端双 Xeon Platinum CPU 服务器上,Megatron 530B 的推理需要超过一分钟的时间。对于很多应用而言,这基本上是不可用的。」黄仁勋举例说,「GPU 加速的模型也很有挑战性,因为模型尺寸要求远远高于 GPU 的显存。」GPT-3 有 1750 亿参数,至少需要 350GB 的内存,Megatron 参数更多,内存需求高达 1TB。
为了解决大模型推理问题,NVIDIA 创建了 Triton 推理服务器。黄仁勋表示,Triton 是世界上第一个分布式推理服务器,可以在多个 GPU 和多个节点之间进行分布式推理。有了 Triton,GPT-3 可以轻松运行在 8-GPU 服务器上;Megatron 530B 可以分布部署在两个 DGX 系统中,推理时间从 1 分钟缩短至半秒。
超大规模语言模型对于未来非常重要,它可以回答复杂问题,理解和总结长长的文档,实现翻译,组织语言、编写故事、写代码、理解人们的意图,也可以在没有人类监督的情况下自动完成训练,还可以无需样本,这意味着它们可以支持很多种不同领域的任务。
为超大规模语言模型构建系统,可能是未来最大的超算应用。由于算力需求远远超过 GPU 的能力发展速度,英伟达找到了几条新路。
「科学领域中,基于深度学习的软件革命正在发生,这个过程终将产生重要影响。在计算科学上三个相互关联的动态系统会让我们取得数百万倍的算力飞跃,」黄仁勋说道。
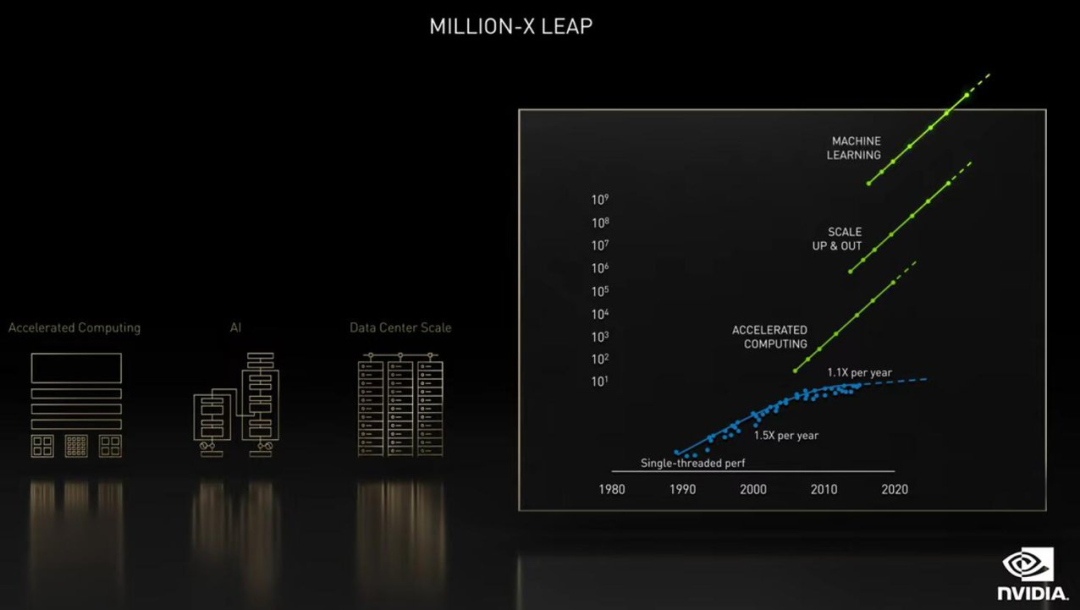
这三重加速,首先是计算加速,芯片、系统和加速库,再到应用的全栈式计算将会为我们带来 50 倍的速度提升。
其次是推动力,深度学习的兴起引发了现代 AI 革命,从根本上改变了软件。深度学习编写的软件具有高度并行性,这使其有助于通过 GPU 进行加速,而且可以扩展到多 GPU 和多接点。扩展到 DGX SuperPOD 这样的大型系统可以让速度再提高 5000 倍。
最后,通过深度学习编写的 AI 软件预测结果的速度能够比人类编写的软件快 1000 至 10000 倍,这彻底改写了我们解决问题的方式,甚至可以解决的问题。
「最高可以达到 2.5 亿倍,当然大家获得的结果会有所不同,这取决于你投资的规模。但如果问题能因此解决,投资就会到来。」黄仁勋说道。
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧
