各位同学好,今天和大家分享一下如何使用 注意力机制 和 深度可分离卷积 优化 YOLOV4 的 PANet 特征金字塔。看本篇博客之前,建议大家先看以下几篇:
YOLOV4主干网络:https://blog.csdn.net/dgvv4/article/details/123818580
混合域注意力机制:https://blog.csdn.net/dgvv4/article/details/123888724
轻量化网络:https://blog.csdn.net/dgvv4/article/details/123476899
1. PANet原理
网络在不同深度下提取到的特征图关注的特征的倾向有所区别。高层的特征图更加关注物体整体特征如形状大小,低层的特征图关注物体的细节特征如纹理图案,使用低层特征图中蕴含的信息可以对需要检测的物体进行更好地定位。
由于神经网络的前向计算路径过长,通常有几十层,不利于特征信息从下向上流动,因为特征信息每经过一次卷积就会被稀释一次。
PANet 因此在自上向下的FPN网络结构中额外增加了自底向上的路径聚合模块PAN,将低层特征图的信息又传导到高层中特征图去,同时在自上向下的路径中减少了高层特征图到低层特征图的信息流通需要穿过的卷积层的数量。

2. CBAM 注意力机制
CBAM注意力机制在之前的文章中已经详细讲解过,有疑问的可以看上面开头链接对应的博文。这里简单复习一下。
CBAM 模块将卷积层输出的结果作为输入特征图,先通过一个通道注意力模块,得到加权结果之后,会再经过一个空间注意力模块,随后对上一步中已经经过通道注意力模块处理过的中间特征图再进行加权,最后将注意力分配权重与输入特征图之间相乘就能够实现自适应的特征优化工作
对于一幅给定的输入图像,CBAM 模块的通道注意力部分关注“什么”是有意义的,而空间注意力部分更加关注“哪里”是信息更加丰富的部分,两者之间互相补充,能够更好的帮助网络进行特征提取工作。

代码展示:
#(1)CBAM注意力机制
# 通道注意力
def channel_attenstion(inputs, ratio=0.25):
'''ratio代表第一个全连接层下降通道数的倍数'''
channel = inputs.shape[-1] # 获取输入特征图的通道数
# 分别对输出特征图进行全局最大池化和全局平均池化
# [h,w,c]==>[None,c]
x_max = layers.GlobalMaxPooling2D()(inputs)
x_avg = layers.GlobalAveragePooling2D()(inputs)
# [None,c]==>[1,1,c]
x_max = layers.Reshape([1,1,-1])(x_max) # -1代表自动寻找通道维度的大小
x_avg = layers.Reshape([1,1,-1])(x_avg) # 也可以用变量channel代替-1
# 第一个全连接层通道数下降1/4, [1,1,c]==>[1,1,c//4]
x_max = layers.Dense(channel*ratio)(x_max)
x_avg = layers.Dense(channel*ratio)(x_avg)
# relu激活函数
x_max = layers.Activation('relu')(x_max)
x_avg = layers.Activation('relu')(x_avg)
# 第二个全连接层上升通道数, [1,1,c//4]==>[1,1,c]
x_max = layers.Dense(channel)(x_max)
x_avg = layers.Dense(channel)(x_avg)
# 结果在相叠加 [1,1,c]+[1,1,c]==>[1,1,c]
x = layers.Add()([x_max, x_avg])
# 经过sigmoid归一化权重
x = tf.nn.sigmoid(x)
# 输入特征图和权重向量相乘,给每个通道赋予权重
x = layers.Multiply()([inputs, x]) # [h,w,c]*[1,1,c]==>[h,w,c]
return x
# 空间注意力机制
def spatial_attention(inputs):
# 在通道维度上做最大池化和平均池化[b,h,w,c]==>[b,h,w,1]
# keepdims=Fale那么[b,h,w,c]==>[b,h,w]
x_max = tf.reduce_max(inputs, axis=3, keepdims=True) # 在通道维度求最大值
x_avg = tf.reduce_mean(inputs, axis=3, keepdims=True) # axis也可以为-1
# 在通道维度上堆叠[b,h,w,2]
x = layers.concatenate([x_max, x_avg])
# 1*1卷积调整通道[b,h,w,1]
x = layers.Conv2D(filters=1, kernel_size=(1,1), strides=1, padding='same')(x)
# sigmoid函数权重归一化
x = tf.nn.sigmoid(x)
# 输入特征图和权重相乘
x = layers.Multiply()([inputs, x])
return x
# CBAM注意力
def CBAM_attention(inputs):
# 先经过通道注意力再经过空间注意力
x = channel_attenstion(inputs)
x = spatial_attention(x)
return x3. 深度可分离卷积
普通卷积是一个卷积核处理所有的通道,输入特征图有多少个通道,卷积核就有几个通道,一个卷积核生成一张特征图。
深度可分离卷积 可理解为 深度卷积 + 逐点卷积
深度卷积只处理长宽方向的空间信息;逐点卷积只处理跨通道方向的信息。能大大减少参数量,提高计算效率
深度卷积: 一个卷积核只处理一个通道,即每个卷积核只处理自己对应的通道。输入特征图有多少个通道就有多少个卷积核。将每个卷积核处理后的特征图堆叠在一起。输入和输出特征图的通道数相同。
由于只处理长宽方向的信息会导致丢失跨通道信息,为了将跨通道的信息补充回来,需要进行逐点卷积。
逐点卷积: 是使用1x1卷积对跨通道维度处理,有多少个1x1卷积核就会生成多少个特征图。
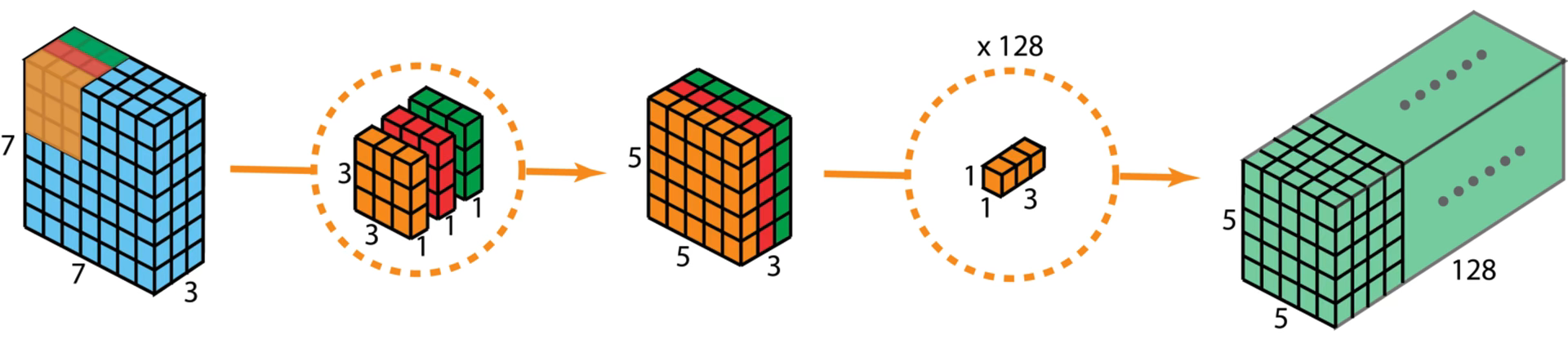
代码展示:
#(2)# 深度可分离卷积+BN+relu
def conv_block(inputs, filters, kernel_size, strides):
# 深度卷积
x = layers.DepthwiseConv2D(kernel_size, strides,
padding='same', use_bias=False)(inputs) # 有BN不要偏置
# 逐点卷积
x = layers.Conv2D(filters, kernel_size=(1,1), strides=1,
padding='same', use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.Activation('relu')(x)
return x
#(3)5次卷积操作提取特征减少参数量
def five_conv(x, filters):
x = conv_block(x, filters, (1,1), strides=1)
x = conv_block(x, filters*2, (3,3), strides=1)
x = conv_block(x, filters, (1,1), strides=1)
x = conv_block(x, filters*2, (3,3), strides=1)
x = conv_block(x, filters, (1,1), strides=1)
return x4. 改进的 PANet 金字塔
采用 CBAM注意力机制 和 深度可分离卷积 优化PANet金字塔。
(1)使用深度可分离卷积块代替所有的标准卷积块。
(2)在上采样Upsample和下采样Downsample之后,对输出特征图使用CBAM注意力机制。

深度可分离卷积可以显著降低模型的计算量和参数量。
由于 CBAM 是轻量级的通用模块,因此可以忽略该模块的开销而将其无缝集成到任何 CNN 架构中,并且可以与基础的卷积神经网络一起进行端到端训练。实验表明,CBAM 模块在各种模型上都能够起到一定的作用,并在分类和检测性能方面对模型起到了较好的改进效果。
主干网络代码如下,p5是经过SPP模块之后的第三个有效特征层,feat1和feat2分别是网络输出的第一和二个有效特征层。
#(4)主干网络
def panet(feat1, feat2, p5):
# 对网络的有效输出特征层采用CBAM注意力
feat1 = CBAM_attention(feat1)
feat2 = CBAM_attention(feat2)
p5 = CBAM_attention(p5)
#(1)
# 对spp结构的输出进行卷积和上采样
# [13,13,512]==>[13,13,256]==>[26,26,256]
p5_upsample = conv_block(p5, filters=256, kernel_size=(1,1), strides=1)
p5_upsample = layers.UpSampling2D(size=(2,2))(p5_upsample)
# 对feat2特征层卷积后再与p5_upsample堆叠
# [26,26,512]==>[26,26,256]==>[26,26,512]
p4 = conv_block(feat2, filters=256, kernel_size=(1,1), strides=1)
# 上采样后使用注意力机制
p4 = CBAM_attention(p4)
# 通道维度上堆叠
p4 = layers.concatenate([p4, p5_upsample])
# 堆叠后进行5次卷积[26,26,512]==>[26,26,256]
p4 = five_conv(p4, filters=256)
#(2)
# 对p4卷积上采样
# [26,26,256]==>[26,26,512]==>[52,52,512]
p4_upsample = conv_block(p4, filters=128, kernel_size=(1,1), strides=1)
p4_upsample = layers.UpSampling2D(size=(2,2))(p4_upsample)
# feat1层卷积后与p4_upsample堆叠
# [52,52,256]==>[52,52,128]==>[52,52,256]
p3 = conv_block(feat1, filters=128, kernel_size=(1,1), strides=1)
# 上采样后使用注意力机制
p3 = CBAM_attention(p3)
# 通道维度上堆叠
p3 = layers.concatenate([p3, p4_upsample])
# 堆叠后进行5次卷积[52,52,256]==>[52,52,128]
p3 = five_conv(p3, filters=128)
# 存放第一个特征层的输出
p3_output = p3
#(3)
# p3卷积下采样和p4堆叠
# [52,52,128]==>[26,26,256]==>[26,26,512]
p3_downsample = conv_block(p3, filters=256, kernel_size=(3,3), strides=2)
# 下采样后使用注意力机制
p3_downsample = CBAM_attention(p3_downsample)
# 通道维度上堆叠
p4 = layers.concatenate([p3_downsample, p4])
# 堆叠后的结果进行5次卷积[26,26,512]==>[26,26,256]
p4 = five_conv(p4, filters=256)
# 存放第二个有效特征层的输出
p4_output = p4
#(4)
# p4卷积下采样和p5堆叠
# [26,26,256]==>[13,13,512]==>[13,13,1024]
p4_downsample = conv_block(p4, filters=512, kernel_size=(3,3), strides=2)
# 下采样后使用注意力机制
p4_downsample = CBAM_attention(p4_downsample)
# 通道维度上堆叠
p5 = layers.concatenate([p4_downsample, p5])
# 堆叠后进行5次卷积[13,13,1024]==>[13,13,512]
p5 = five_conv(p5, filters=512)
# 存放第三个有效特征层的输出
p5_output = p5
# 返回输出层结果
return p3_output, p4_output, p5_output查看网络架构,参数量从原来的两千多万下降到六百万
if __name__ == '__main__':
# 构造输入
feat1 = keras.Input(shape=[52,52,256])
feat2 = keras.Input(shape=[26,26,512])
p5 = keras.Input(shape=[13,13,1024])
# 返回panet结果
p3_output, p4_output, p5_output = panet(feat1, feat2, p5)
inputs = [feat1, feat2, p5]
outputs = [p3_output, p4_output, p5_output]
# 构建网络
model = keras.Model(inputs, outputs)
model.summary()Total params: 6,846,037
Trainable params: 6,826,837
Non-trainable params: 19,200