回首往事不可睡

1引言
最近一直 整理研究和总结 之前的一些推文,把相似的功能整理为一个小软件,方便大家使用,不必再一句一句复制代码运行了。也方便大家进行科研活动减少不必要的时间。
GetTransTool:
这个软件名字为 GetTransTool ,含有 四种 不同的功能,可以根据不同数据库 ucsc/gencode/ensembl 的 GTF 文件或者 转录本 fasta 文件 来提取最长转录本 fasta 结果或者 CDS 最长的 fasta 结果,可以查看我的 githup:
地址: https://github.com/junjunlab/GetTransTool
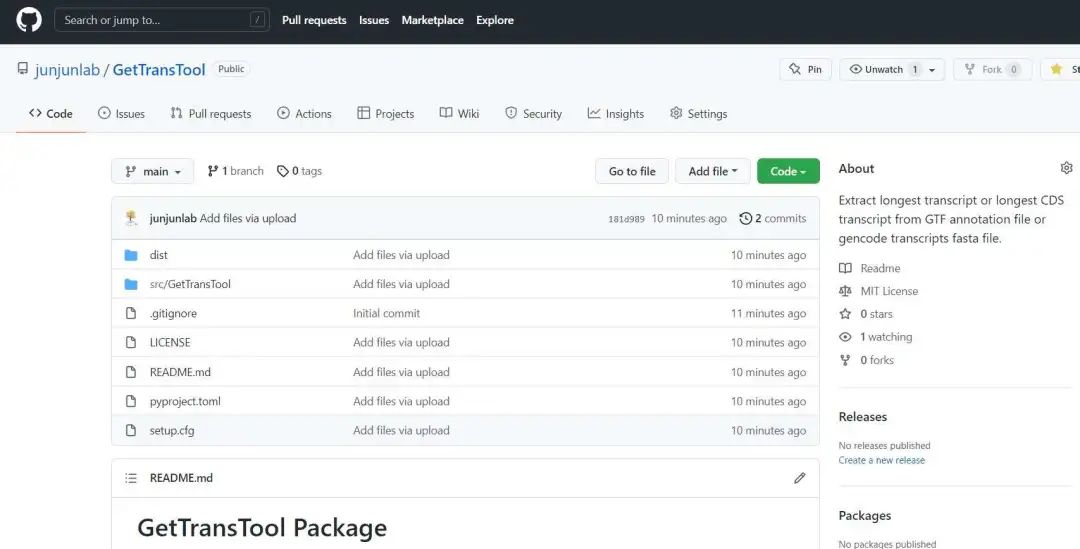
觉得有用的小伙伴可以给我点个小星星!
此外之前也写过两个小功能在我的 githup 上,分别是:
GetGeneLength
地址: https://github.com/junjunlab/GetGeneLength
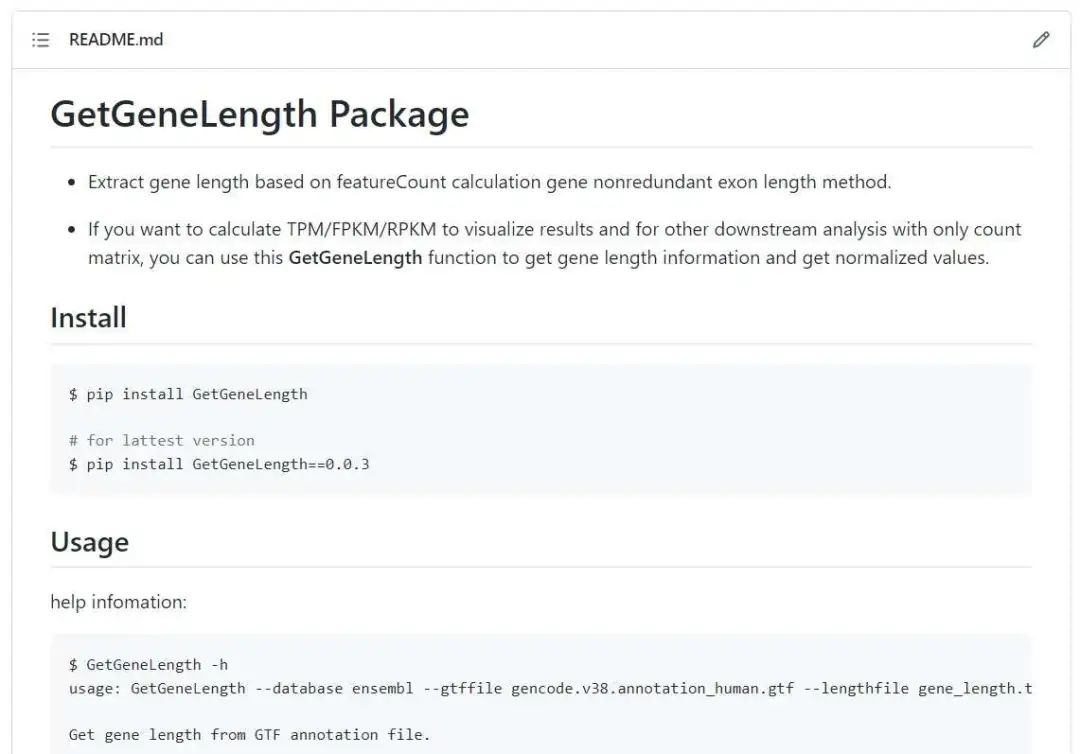
GetTsite地址: https://github.com/junjunlab/GetTsite
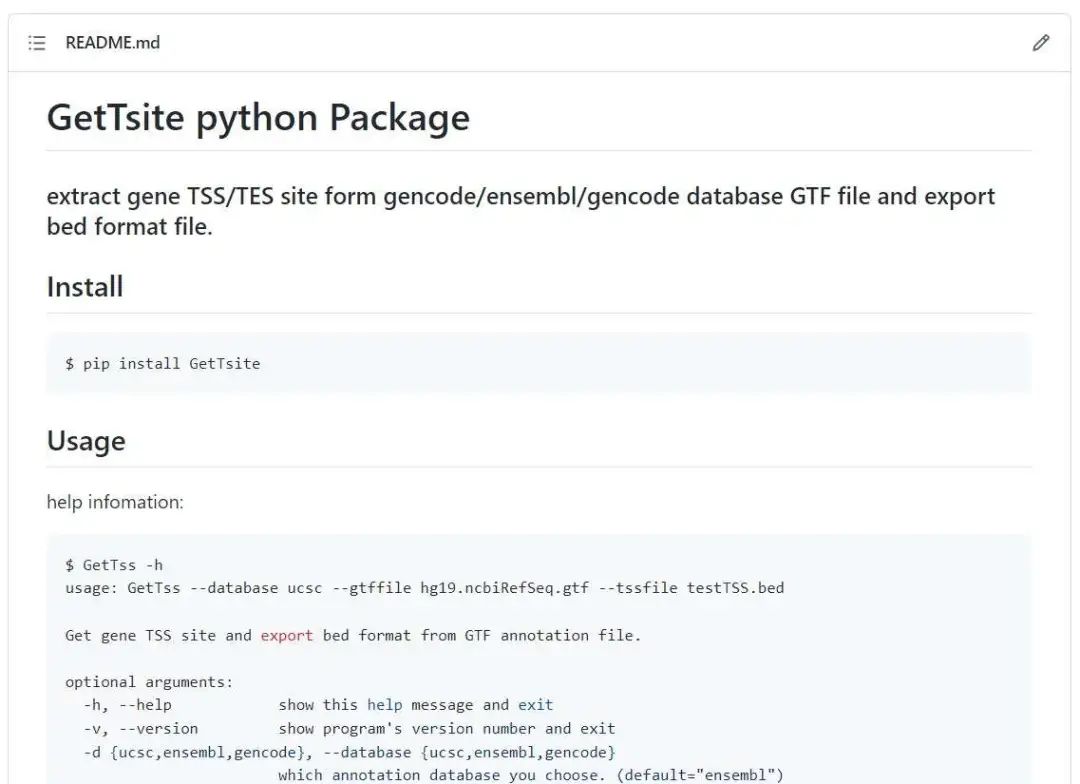
欢迎大家下载使用。
2GetTransTool 使用介绍
GetTransTool Package
There are four types of methods to extract longest transcript or longest CDS regeion with longest transcript from transcripts fasta file or GTF file.
1.Extract longest transcript from gencode transcripts fasta file.
2.Extract longest transcript from gtf format annotation file based on gencode/ensembl/ucsc database.
3.Extract longest CDS regeion with longest transcript from gencode database transcripts fasta file.
4.Extract longest CDS regeion with longest transcript from gtf format annotation file based on ensembl/ucsc database.
3Install
$ pip install GetTransTool4Usage
1. get longest transcript from gencode transcripts fasta file:
help infomation:
$ GetLongestTransFromGencode -h
usage: GetLongestTransFromGencode --file gencode.vM28.transcripts.fa.gz --outfile longest_trans.fa
Get longest transcripts from gencode transcripts fasta file.
optional arguments:
-h, --help show this help message and exit
-v, --version show program's version number and exit
-f transfile, --file transfile
input your transcripts file with ".gz" format. (gencode.vM28.transcripts.fa.gz)
-o longestfile, --outfile longestfile
output your longest transcript file. (longest_trans.fa)
Thank your for your support, if you have any questions or suggestions please contact me: [email protected].usage:
$ GetLongestTransFromGencode --file gencode.vM28.transcripts.fa.gz --outfile longest_trans_gencode.fa
Your job is running, please wait...
Your job is done!
Running with 32.33 seconds!there will be three files produced including name_changed.fa, longest_transcripts_info.csv, longest_trans_gencode.fa.
name_changed.fa:
>4933401J01Rik_ENSMUSG00000102693.2_ENSMUST00000193812.2_1070
AAGGAAAGAGGATAACACTTGAAATGTAAATAAAGAAAATACCTAATAAAAATAAATAAA
AACATGCTTTCAAAGGAAATAAAAAGTTGGATTCAAAAATTTAACTTTTGCTCATTTGGT
ATAATCAAGGAAAAGACCTTTGCATATAAAATATATTTTGAATAAAATTCAGTGGAAGAA
...longest_transcripts_info.csv:
this is the longest transcripts exon length information.
fullname,gene_name,translength
snoZ196_ENSMUSG00002074855.1_ENSMUST00020182568.1_35,snoZ196,35
snoZ159_ENSMUSG00002075734.1_ENSMUST00020182611.1_87,snoZ159,87
n-R5s93_ENSMUSG00000119639.1_ENSMUST00000240071.1_119,n-R5s93,119
...longest_trans_gencode.fa:
this is the filtered longest transcript fasta file.
>4933401J01Rik_ENSMUSG00000102693.2_ENSMUST00000193812.2_1070
AAGGAAAGAGGATAACACTTGAAATGTAAATAAAGAAAATACCTAATAAAAATAAATAAA
AACATGCTTTCAAAGGAAATAAAAAGTTGGATTCAAAAATTTAACTTTTGCTCATTTGGT
ATAATCAAGGAAAAGACCTTTGCATATAAAATATATTTTGAATAAAATTCAGTGGAAGAA
...2. Extract longest transcript from gtf format annotation file based on gencode/ensembl/ucsc database:
help infomation:
$ GetLongestTransFromGTF -h
usage: GetLongestTransFromGTF --database ensembl --gtffile Homo_sapiens.GRCh38.101.gtf.gz --genome Homo_sapiens.GRCh38.dna.primary_assembly.fa.gz --outfile longest_trans.fa
Extract longest transcript from gtf format annotation file based on gencode/ensembl/ucsc database.
optional arguments:
-h, --help show this help message and exit
-v, --version show program's version number and exit
-d databse, --database databse
which annotation database you choose. (default="ensembl", ucsc/ensembl/gencode)
-g gtffile, --gtffile gtffile
input your GTF file with ".gz" format.
-fa genome, --genome genome
your genome fasta file matched with your GTF file with ".gz" format. (Homo_sapiens.GRCh38.dna.primary_assembly.fa.gz)
-o longestfile, --outfile longestfile
output your longest transcript file. (longest_trans.fa)
Thank your for your support, if you have any questions or suggestions please contact me: [email protected].usage:
$ GetLongestTransFromGTF --database ensembl --gtffile Homo_sapiens.GRCh38.103.gtf.gz --genome Homo_sapiens.GRCh38.dna.primary_assembly.fa.gz --outfile longest_trans_ensembl.fa
Your job is running, please wait...
Your job is done!
Running with 159.51 seconds!there will be three files produced including longest_transcripts_info.csv, longest_trans.gtf, longest_trans_ensembl.fa.
longest_transcripts_info.csv:
,transcript_length,gene_name
snoZ196_ENSG00000281780_ENST00000625269_snoRNA,89,snoZ196
hsa-mir-423_ENSG00000266919_ENST00000586878_lncRNA,94,hsa-mir-423
hsa-mir-1253_ENSG00000272920_ENST00000609567_lncRNA,105,hsa-mir-1253
...longest_trans.gtf:
this is the gtf information for the longest transcripts.
1 havana gene 11869 14409 . + . gene_id "ENSG00000223972"; gene_version "5"; gene_name "DDX11L1"; gene_source "havana"; gene_biotype "transcribed_unprocessed_pseudogene";
1 havana transcript 11869 14409 . + . gene_id "ENSG00000223972"; gene_version "5"; transcript_id "ENST00000456328"; transcript_version "2"; gene_name "DDX11L1"; gene_source "havana"; gene_biotype "transcribed_unprocessed_pseudogene"; transcript_name "DDX11L1-202"; transcript_source "havana"; transcript_biotype "processed_transcript"; tag "basic"; transcript_support_level "1";
1 havana exon 11869 12227 . + . gene_id "ENSG00000223972"; gene_version "5"; transcript_id "ENST00000456328"; transcript_version "2"; exon_number "1"; gene_name "DDX11L1"; gene_source "havana"; gene_biotype "transcribed_unprocessed_pseudogene"; transcript_name "DDX11L1-202"; transcript_source "havana"; transcript_biotype "processed_transcript"; exon_id "ENSE00002234944"; exon_version "1"; tag "basic"; transcript_support_level "1";
1 havana exon 12613 12721 . + . gene_id "ENSG00000223972"; gene_version "5"; transcript_id "ENST00000456328"; transcript_version "2"; exon_number "2"; gene_name "DDX11L1"; gene_source "havana"; gene_biotype "transcribed_unprocessed_pseudogene"; transcript_name "DDX11L1-202"; transcript_source "havana"; transcript_biotype "processed_transcript"; exon_id "ENSE00003582793"; exon_version "1"; tag "basic"; transcript_support_level "1";
1 havana exon 13221 14409 . + . gene_id "ENSG00000223972"; gene_version "5"; transcript_id "ENST00000456328"; transcript_version "2"; exon_number "3"; gene_name "DDX11L1"; gene_source "havana"; gene_biotype "transcribed_unprocessed_pseudogene"; transcript_name "DDX11L1-202"; transcript_source "havana"; transcript_biotype "processed_transcript"; exon_id "ENSE00002312635"; exon_version "1"; tag "basic"; transcript_support_level "1";
1 havana gene 14404 29570 . - . gene_id "ENSG00000227232"; gene_version "5"; gene_name "WASH7P"; gene_source "havana"; gene_biotype "unprocessed_pseudogene";longest_trans_ensembl.fa:
>DDX11L1_ENSG00000223972_ENST00000456328_transcribed_unprocessed_pseudogene
GTTAACTTGCCGTCAGCCTTTTCTTTGACCTCTTCTTTCTGTTCATGTGTATTTGCTGTC
TCTTAGCCCAGACTTCCCGTGTCCTTTCCACCGGGCCTTTGAGAGGTCACAGGGTCTTGA
TGCTGTGGTCTTCATCTGCAGGTGTCTGACTTCCAGCAACTGCTGGCCTGTGCCAGGGTG
...for ucsc:
$ GetLongestTransFromGTF --database ucsc --gtffile hg19.ncbiRefSeq.gtf.gz --genome hg19.fa.gz --outfile longest_trans_ucsc.fa3. Extract longest CDS regeion with longest transcript from gencode database transcripts fasta file.
help infomation:
$ GetCDSLongestFromGencode -h
usage: GetCDSLongestFromGencode --file gencode.vM28.pc_transcripts.fa.gz --outfile longest_cds_trans.fa
Extract longest CDS regeion with longest transcript from gencode database transcripts fasta file.
optional arguments:
-h, --help show this help message and exit
-v, --version show program's version number and exit
-f transfile, --file transfile
input your protein-coding transcripts file with ".gz" format. (gencode.vM28.pc_transcripts.fa.gz)
-o longestfile, --outfile longestfile
output your longest transcript file. (longest_cds_trans.fa)
Thank your for your support, if you have any questions or suggestions please contact me: [email protected].usage:
$ GetCDSLongestFromGencode --file gencode.vM28.pc_transcripts.fa.gz --outfile longest_cds_trans_gencode.fa
Your job is running, please wait...
Your job is done!
Running with 17.67 seconds!there will be four files produced including name_changed.fa, All_transcripts_cds_info.csv, longest_cds_transcripts_info.csv, longest_cds_trans_gencode.fa.
name_changed.fa:
>Xkr4_ENSMUSG00000051951.6_ENSMUST00000070533.5_151_2094_3634
GCGGCGGCGGGCGAGCGGGCGCTGGAGTAGGAGCTGGGGAGCGGCGCGGCCGGGGAAGGA
AGCCAGGGCGAGGCGAGGAGGTGGCGGGAGGAGGAGACAGCAGGGACAGGTGTCAGATAA
AGGAGTGCTCTCCTCCGCTGCCGAGGCATCATGGCCGCTAAGTCAGACGGGAGGCTGAAG
...All_transcripts_cds_info.csv:
this is the all transcripts cds and exon length information.
fullname,gene_name,translength,cdslength
>mt-Nd6_ENSMUSG00000064368.1_ENSMUST00000082419.1_1_519_519,>mt-Nd6,519,519
>mt-Nd5_ENSMUSG00000064367.1_ENSMUST00000082418.1_1_1824_1824,>mt-Nd5,1824,1824
>mt-Nd4l_ENSMUSG00000065947.1_ENSMUST00000084013.1_1_297_297,>mt-Nd4l,297,297
...longest_cds_transcripts_info.csv:
fullname,gene_name,translength,cdslength
>mt-Nd6_ENSMUSG00000064368.1_ENSMUST00000082419.1_1_519_519,>mt-Nd6,519,519
>mt-Nd5_ENSMUSG00000064367.1_ENSMUST00000082418.1_1_1824_1824,>mt-Nd5,1824,1824
>mt-Nd4l_ENSMUSG00000065947.1_ENSMUST00000084013.1_1_297_297,>mt-Nd4l,297,297
...longest_cds_trans_gencode.fa:
>Xkr4_ENSMUSG00000051951.6_ENSMUST00000070533.5_151_2094_3634
GCGGCGGCGGGCGAGCGGGCGCTGGAGTAGGAGCTGGGGAGCGGCGCGGCCGGGGAAGGA
AGCCAGGGCGAGGCGAGGAGGTGGCGGGAGGAGGAGACAGCAGGGACAGGTGTCAGATAA
AGGAGTGCTCTCCTCCGCTGCCGAGGCATCATGGCCGCTAAGTCAGACGGGAGGCTGAAG
...4. Extract longest CDS regeion with longest transcript from gtf format annotation file based on ensembl/ucsc database.
help infomation:
$ GetCDSLongestFromGTF -h
usage: GetCDSLongestFromGTF --database ensembl --gtffile Homo_sapiens.GRCh38.101.gtf.gz --genome Homo_sapiens.GRCh38.dna.primary_assembly.fa.gz --outfile longest_cds_trans.fa
Extract longest CDS regeion with longest transcript from gtf format annotation file based on ensembl/ucsc database.
optional arguments:
-h, --help show this help message and exit
-v, --version show program's version number and exit
-d databse, --database databse
which annotation database you choose. (default="ensembl", ucsc/ensembl)
-g gtffile, --gtffile gtffile
input your GTF file with ".gz" format.
-fa genome, --genome genome
your genome fasta file matched with your GTF file with ".gz" format. (Homo_sapiens.GRCh38.dna.primary_assembly.fa.gz)
-o cdslongestfile, --outfile cdslongestfile
output your longest transcript file. (longest_cds_trans.fa)
Thank your for your support, if you have any questions or suggestions please contact me: [email protected].usage:
$ GetCDSLongestFromGTF --database ensembl --gtffile Homo_sapiens.GRCh38.103.gtf.gz --genome Homo_sapiens.GRCh38.dna.primary_assembly.fa.gz --outfile longest_cds_trans_ensembl.fa
Your job is running, please wait...
Your job is done!
Running with 152.38 seconds!there will be four files produced including CDS_longest_trans.gtf, All_transcripts_cds_info.csv, longest_cds_transcripts_info.csv, longest_cds_trans_ensembl.fa.
CDS_longest_trans.gtf:
1 ensembl_havana gene 65419 71585 . + . gene_id "ENSG00000186092"; gene_version "6"; gene_name "OR4F5"; gene_source "ensembl_havana"; gene_biotype "protein_coding";
1 havana transcript 65419 71585 . + . gene_id "ENSG00000186092"; gene_version "6"; transcript_id "ENST00000641515"; transcript_version "2"; gene_name "OR4F5"; gene_source "ensembl_havana"; gene_biotype "protein_coding"; transcript_name "OR4F5-202"; transcript_source "havana"; transcript_biotype "protein_coding"; tag "basic";
1 havana exon 65419 65433 . + . gene_id "ENSG00000186092"; gene_version "6"; transcript_id "ENST00000641515"; transcript_version "2"; exon_number "1"; gene_name "OR4F5"; gene_source "ensembl_havana"; gene_biotype "protein_coding"; transcript_name "OR4F5-202"; transcript_source "havana"; transcript_biotype "protein_coding"; exon_id "ENSE00003812156"; exon_version "1"; tag "basic";
1 havana exon 65520 65573 . + . gene_id "ENSG00000186092"; gene_version "6"; transcript_id "ENST00000641515"; transcript_version "2"; exon_number "2"; gene_name "OR4F5"; gene_source "ensembl_havana"; gene_biotype "protein_coding"; transcript_name "OR4F5-202"; transcript_source "havana"; transcript_biotype "protein_coding"; exon_id "ENSE00003813641"; exon_version "1"; tag "basic";
1 havana CDS 65565 65573 . + 0 gene_id "ENSG00000186092"; gene_version "6"; transcript_id "ENST00000641515"; transcript_version "2"; exon_number "2"; gene_name "OR4F5"; gene_source "ensembl_havana"; gene_biotype "protein_coding"; transcript_name "OR4F5-202"; transcript_source "havana"; transcript_biotype "protein_coding"; protein_id "ENSP00000493376"; protein_version "2"; tag "basic";
1 havana start_codon 65565 65567 . + 0 gene_id "ENSG00000186092"; gene_version "6"; transcript_id "ENST00000641515"; transcript_version "2"; exon_number "2"; gene_name "OR4F5"; gene_source "ensembl_havana"; gene_biotype "protein_coding"; transcript_name "OR4F5-202"; transcript_source "havana"; transcript_biotype "protein_coding"; tag "basic";
1 havana exon 69037 71585 . + . gene_id "ENSG00000186092"; gene_version "6"; transcript_id "ENST00000641515"; transcript_version "2"; exon_number "3"; gene_name "OR4F5"; gene_source "ensembl_havana"; gene_biotype "protein_coding"; transcript_name "OR4F5-202"; transcript_source "havana"; transcript_biotype "protein_coding"; exon_id "ENSE00003813949"; exon_version "1"; tag "basic";
1 havana CDS 69037 70005 . + 0 gene_id "ENSG00000186092"; gene_version "6"; transcript_id "ENST00000641515"; transcript_version "2"; exon_number "3"; gene_name "OR4F5"; gene_source "ensembl_havana"; gene_biotype "protein_coding"; transcript_name "OR4F5-202"; transcript_source "havana"; transcript_biotype "protein_coding"; protein_id "ENSP00000493376"; protein_version "2"; tag "basic";
1 havana stop_codon 70006 70008 . + 0 gene_id "ENSG00000186092"; gene_version "6"; transcript_id "ENST00000641515"; transcript_version "2"; exon_number "3"; gene_name "OR4F5"; gene_source "ensembl_havana"; gene_biotype "protein_coding"; transcript_name "OR4F5-202"; transcript_source "havana"; transcript_biotype "protein_coding"; tag "basic";
1 havana five_prime_utr 65419 65433 . + . gene_id "ENSG00000186092"; gene_version "6"; transcript_id "ENST00000641515"; transcript_version "2"; gene_name "OR4F5"; gene_source "ensembl_havana"; gene_biotype "protein_coding"; transcript_name "OR4F5-202"; transcript_source "havana"; transcript_biotype "protein_coding"; tag "basic";
1 havana five_prime_utr 65520 65564 . + . gene_id "ENSG00000186092"; gene_version "6"; transcript_id "ENST00000641515"; transcript_version "2"; gene_name "OR4F5"; gene_source "ensembl_havana"; gene_biotype "protein_coding"; transcript_name "OR4F5-202"; transcript_source "havana"; transcript_biotype "protein_coding"; tag "basic";
1 havana three_prime_utr 70009 71585 . + . gene_id "ENSG00000186092"; gene_version "6"; transcript_id "ENST00000641515"; transcript_version "2"; gene_name "OR4F5"; gene_source "ensembl_havana"; gene_biotype "protein_coding"; transcript_name "OR4F5-202"; transcript_source "havana"; transcript_biotype "protein_coding"; tag "basic";
1 ensembl_havana gene 450740 451678 . - . gene_id "ENSG00000284733"; gene_version "2"; gene_name "OR4F29"; gene_source "ensembl_havana"; gene_biotype "protein_coding";
...All_transcripts_cds_info.csv:
this is the all transcripts cds and exon length information.
cdslength,ID,translength,utr5length,gene_name
2709,ZZZ3_ENSG00000036549_ENST00000370801,6412,476,ZZZ3
1227,ZZZ3_ENSG00000036549_ENST00000370798,2468,486,ZZZ3
173,ZZZ3_ENSG00000036549_ENST00000433749,603,430,ZZZ3
...longest_cds_transcripts_info.csv:
cdslength,ID,translength,utr5length,gene_name
2709,ZZZ3_ENSG00000036549_ENST00000370801,6412,476,ZZZ3
8883,ZZEF1_ENSG00000074755_ENST00000381638,11466,135,ZZEF1
1716,ZYX_ENSG00000159840_ENST00000322764,2228,80,ZYX
...longest_cds_trans_gencode.fa:
>OR4F5_ENSG00000186092_ENST00000641515_61_1038_2618
CCCAGATCTCTTCAGTTTTTATGCCTCATTCTGTGAAAATTGCTGTAGTCTCTTCCAGTT
ATGAAGAAGGTAACTGCAGAGGCTATTTCCTGGAATGAATCAACGAGTGAAACGAATAAC
TCTATGGTGACTGAATTCATTTTTCTGGGTCTCTCTGATTCTCAGGAACTCCAGACCTTC
...for ucsc:
$ GetCDSLongestFromGTF --database ucsc --gtffile hg19.ncbiRefSeq.gtf.gz --genome hg19.fa.gz --outfile longest_cds_trans_ensembl.fa5END
有什么建议或者想法可以发我邮件 [email protected].

欢迎加入生信交流群。加我微信我也拉你进 微信群聊 老俊俊生信交流群 哦,数据代码已上传至QQ群,欢迎加入下载。
群二维码:

老俊俊微信:

知识星球:

所以今天你学习了吗?
欢迎小伙伴留言评论!
点击我留言!
今天的分享就到这里了,敬请期待下一篇!
最后欢迎大家分享转发,您的点赞是对我的鼓励和肯定!
如果觉得对您帮助很大,赏杯快乐水喝喝吧!
往期回顾
◀argparse 传参之 add_argument() 方法
◀argparse 传参之 ArgumentParser 对象
◀...