本文转自:https://zhuanlan.zhihu.com/p/32702868,若侵即删。这篇文章,偏工程实用,不是学术界意义上的检测综述,所以,有些阐述,过于绝对化。挑着看吧。
- 《人脸检测背景介绍和常用数据库》,介绍人脸检测的背景,常用数据库和评价指标,重点介绍各类算法的发展现状和各数据库上目前算法的性能速度水平;
- 《非深度学习的人脸检测》,介绍以VJ为代表的非深度学习人脸检测算法,重点介绍速度比较快的简单特征级联系列,和性能比较好的通道特征系列,DPM系列速度太慢会略过;
- 《深度学习的人脸检测》,介绍近3-4年深度学习相关的人脸检测算法,重点是速度比较快的级联CNN系列,和SSD/RPN系列,Faster-RCNN系列速度太慢可能会略过;
- 《将级联CNN人脸检测的速度做到极致》,包括级联CNN的论文复现,算法层面优化,CNN压缩和加速等,分析该系列的优缺点,重点是介绍如何将级联CNN在ARM(单核1.2G)上做到14 fps(VGA@48),重点的重点是为MTCNN https://github.com/kpzhang93/MTCNN_face_detection_alignment和ncnn Tencent/ncnn打call;
- 《CNN模型压缩之DeepCompression和模型加速之MobileNet v1&2》,介绍CNN模型仅压缩方向最好的方法DeepCompression,和从加速角度来说最好的方法MobileNet v1&2,分享CNN算法落地的关键问题和经验技术。
背景介绍

- 人脸检测是所有现代基于视觉的人与电脑,和人与机器人,交互系统的初始步骤。
- 主流商业数码相机都内嵌人脸检测,辅助自动对焦。
- 很多社交网络如FaceBook,用人脸检测机制实现图像/人物标记。

从问题的领域来看,人脸检测属于目标检测领域,目标检测通常有两大类:
- 通用目标检测:检测图像中多个类别的目标,比如ILSVRC2017的VID任务检测200类目标,VOC2012检测20类目标,通用目标检测核心是n(目标)+1(背景)=n+1分类问题。这类检测通常模型比较大,速度较慢,很少有STOA方法能做到CPU real-time。
- 特定类别目标检测:仅检测图像中某一类特定目标,如人脸检测,行人检测,车辆检测等等,特定类别目标检测核心是1(目标)+1(背景)=2分类问题。这类检测通常模型比较小,速度要求非常高,这里问题的基本要求就是CPU real-time。
从发展历史来看,深度学习在其中的作用非常明显:
- 非深度学习阶段:这段时间经典检测算法都是针对特定目标提出的,比如CVPR 2001的Viola-Jones (VJ)是针对人脸检测问题,CVPR 2005的HOG+SVM是针对行人检测问题,TPAMI 2010的DPM,虽然可以检测各类目标,但要用于多目标检测,需要每个类别分别训练模板,相当于200个特定类别检测问题。
- 深度学习阶段:这段时间经典检测算法都是针对通用目标提出的,比如性能更好的Faster-RCNN, R-FCN系列,速度更快的YOLO, SSD系列,强大的深度学习只要一个CNN就可以搞定多类别检测任务(模型数量1 vs. 200,CNN真的慢吗?)。虽然这些都是多类别方法,但它们都可以用来解决单类别问题,目前人脸检测、行人检测等特定目标检测问题的State-of-the-art(SOTA)都是这类方法的针对性改进。
目前以深度学习为主的CV算法,研究重点是通用目标检测,这些方法在人脸检测问题上效果都不错,那直接用就好了,为什么还要研究这个问题呢?
- Faster-RCNN系列:这类方法的优点是性能高,缺点是速度慢,在GPU上都无法实时,无法满足人脸检测对速度的极高要求,既然性能不是问题,这类方法的研究重点是提高效率。
- SSD系列:这类方法的优势是速度快,在GPU上能实时,缺点是对密集小目标的检测比较差,而人脸刚好是密集小目标,这类方法的研究重点是提高密集小目标的检测性能,同时速度也需要尽可能快,GPU实时算法在应用中依然受限。
人脸检测还有特殊的级联CNN系列,后面会介绍。目前人脸检测研究抱通用目标检测的大腿,这是事实和现状,但其速度和性能双高的要求还是有挑战性的。
评价指标
评价一个人脸检测算法(detector)好坏,常用三个指标:
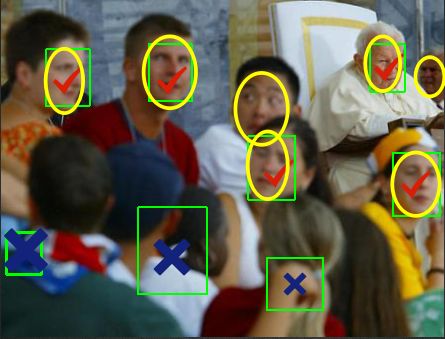
- 召回率(recall):detector能检测出来的人脸数量越多越好,由于每个图像中包含人脸的数量不一定,所以用检测出来的比例来衡量,这个指标就是召回率recall(这个解释不对,跟每张图包含几个人脸没有关系)。detector检测出来的矩形框越接近人工标注的矩形框,说明检测结果越好,通常交并比IoU大于0.5就认为是检测出来了,所以 recall = 检测出来的人脸数量/图像中总人脸数量。
- 误检数(false positives):detector也会犯错,可能会把其他东西认为是人脸,这种情况越少越好,我们用检测错误的绝对数量来表示,这个指标就是误检数false positives。与recall相对,detector检测出来的矩形框与任何人工标注框的IoU都小于0.5,则认为这个检测结果是误检,误检越少越好,比如FDDB上,论文中一般比较1000个或2000个误检时的召回率情况,工业应用中通常比较100或200个误检的召回率情况。
- 检测速度(speed):是个算法都要比速度,人脸检测更不用说,detector检测一幅图像所用的时间越少越好,通常用帧率(frame-per-second,FPS)来表示。不过这里有点小问题,很多detector都是图像越小、图像中人脸越少、检测最小人脸越大,检测速度越快,需要注意不同论文的测试环境和测试图像可能不一样:测试图像,最常用的配置是VGA(640*480)图像检测最小人脸80*80给出速度,但都没有表明测试图像背景是否复杂,图像中有几个人脸(甚至是白底一人脸的图像测速度);测试环境,差别就更大了,CPU有不同型号和主频,有多核多线程差异,GPU也有不同型号,等等(这个理解,个人觉得也有问题,算法帧率评估与背景复杂度无关,不同算法采用的数据相同,才有可能比性,作者实际将的是最坏,最好情况)。
常用数据库
人脸检测的测试数据库有很多,这里仅选择FDDB和WIDER FACE,这个两个数据库都有官方长期维护,各种算法都会提交结果进行比较,而且很多早期数据库目前都已经饱和,没有比较意义。
第一个是2010年非约束环境人脸检测数据库FDDB FDDB : Main:
- Jain V, Learned-Miller E. Fddb: A benchmark for face detection in unconstrained settings [R]. Technical Report UM-CS-2010-009, University of Massachusetts, Amherst, 2010.

FDDB总共2845张图像,5171张,人脸非约束环境,人脸的难度较大,有面部表情,双下巴,光照变化,穿戴,夸张发型,遮挡等难点,是目标最常用的数据库。有以下特点:
- 图像分辨率较小,所有图像的较长边缩放到450,也就是说所有图像都小于450*450,最小标注人脸20*20,包括彩色和灰度两类图像;
- 每张图像的人脸数量偏少,平均1.8人脸/图,绝大多数图像都只有一人脸;
- 数据集完全公开,published methods通常都有论文,大部分都开源代码且可以复现,可靠性高;unpublished methods没有论文没有代码,无法确认它们的训练集是否完全隔离,持怀疑态度最好,通常不做比较。(扔几张FDDB的图像到训练集,VJ也可以训练出很高的召回率。。需要考虑人品能不能抵挡住利益的诱惑)
- 有其他隔离数据集无限制训练再FDDB测试,和FDDB十折交叉验证两种,鉴于FDDB图像数量较少,近几年论文提交结果也都是无限制训练再FDDB测试方式,所以,如果要和published methods提交结果比较,请照做。山世光老师也说十折交叉验证通常会高1~3%。
- 结果有离散分数discROC和连续分数contROC两种,discROC仅关心IoU是不是大于0.5,contROC是IoU越大越好。鉴于大家都采用无限制训练加FDDB测试的方式,detector会继承训练数据集的标注风格,继而影响contROC,所以discROC比较重要,contROC看看就行了,不用太在意。
FDDB在非深度学习的年代是极具挑战性的,很少能做到2000误检0.9以上,经典VJ detector在2000误检也只有0.6593,但在深度学习的年代,这个数据库目前也快接近饱和了,FDDB可以看做是资格赛,选手的正式水平请看下面的WIDER FACE。
第二个是目前2016年提出的,目前难度最大的WIDER FACE WIDER FACE: A Face Detection Benchmark:
- Yang S, Luo P, Loy C C, et al. Wider face: A face detection benchmark [C]// CVPR, 2016: 5525-5533.

WIDER FACE总共32203图像,393703标注人脸,目前难度最大,各种难点比较全面:尺度,姿态,遮挡,表情,化妆,光照等。有以下特点有:
- 图像分辨率普遍偏高,所有图像的宽都缩放到1024,最小标注人脸10*10,都是彩色图像;
- 每张图像的人脸数据偏多,平均12.2人脸/图,密集小人脸非常多;
- 分训练集train/验证集val/测试集test,分别占40%/10%/50%,而且测试集的标注结果(ground truth)没有公开,需要提交结果给官方比较,更加公平公正,而且测试集非常大,结果可靠性极高;
- 根据EdgeBox的检测率情况划分为三个难度等级:Easy, Medium, Hard。
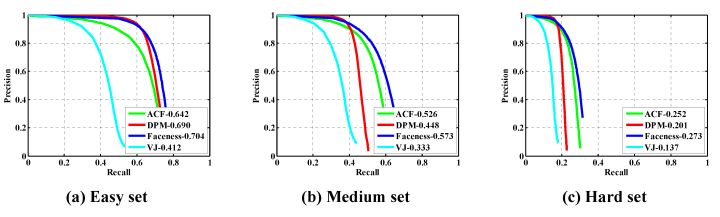
WIDER FACE是目前最常用的训练集,也是目前最大的公开训练集,人工标注的风格比较友好,适合训练。总之,WIDER FACE最难,结果最可靠(顶会论文也有不跑WIDER FACE的,即使论文中用WIDER FACE训练),论文给出经典方法VJ, DPM, ACF和Faceness在这个库上的性能水平,可以看出难度确实很大。
发展现状
FDDB上人脸检测算法的水平:
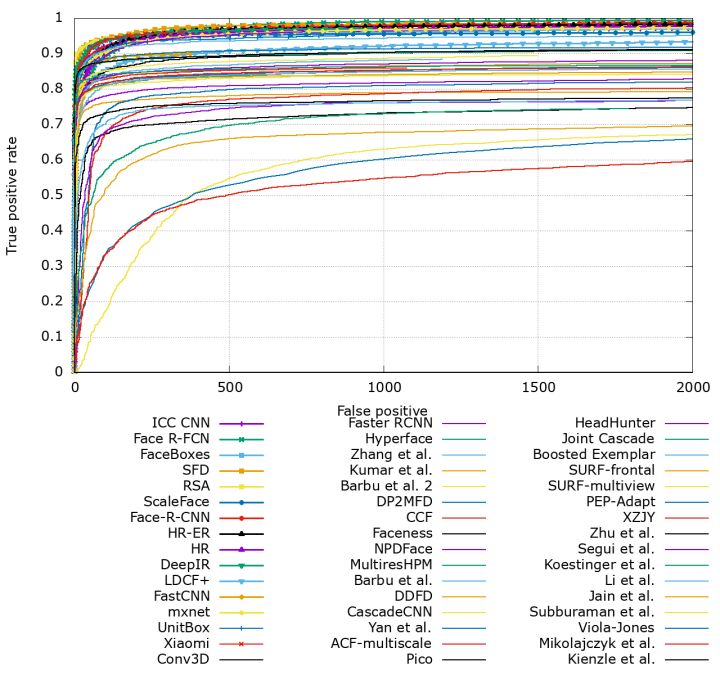
结果太多比较乱,先跳过。
WIDER FACE上人脸检测算法的水平,SOTA都在这里了:

- 经典方法VJ,在这个库上只有0.412/0.333/0.137;
- 2015年的STOA,深度学习方法Faceness在这个库上也只有0.716/0.604/0.315;
- 2016年的STOA,深度学习方法MTCNN是0.85/0.82/0.6,最好的非深度学习方法LDCF+是0.797/0.772/0.564;
- 2017上半年CVPR的HR是0.923/0.910/0.819,下半年ICCV的SSH是0.927/0.915/0.844,SFD是0.935/0.921/0.858,进步神速,深度学习刷榜真的非常恐怖,WIDER FACE离饱和也不远了。
WIDER FACE上结果还是清晰明了的,这个数据库是2015年底提出来的,发表在CVPR 2016,到现在也有两年了,再看这期间ECCV 2016, CVPR 2017和ICCV 2017人脸检测相关工作,也有很多论文没有提交WIDER FACE。
FDDB上结果有点多有点乱,我这里整理了一下FDDB的提交结果,挑选了有代表性的detector,分非深度学习和深度学习两个表格,分别比较100/200/500/1000/2000误检时的召回率,并给出了对应论文中的速度情况,方便大家比较。注意速度直接是论文数据,不同论文的电脑配置不同,多核多线程情况不同,测试图像大小和复杂程度不同,等等因素,仅供参考,具体配置请看原论文,有source code的自己实测。有的论文并未提交FDDB,下表中召回率只有小数点后两位的数据是根据论文ROC曲线估计的。
非深度学习的人脸检测算法比较:
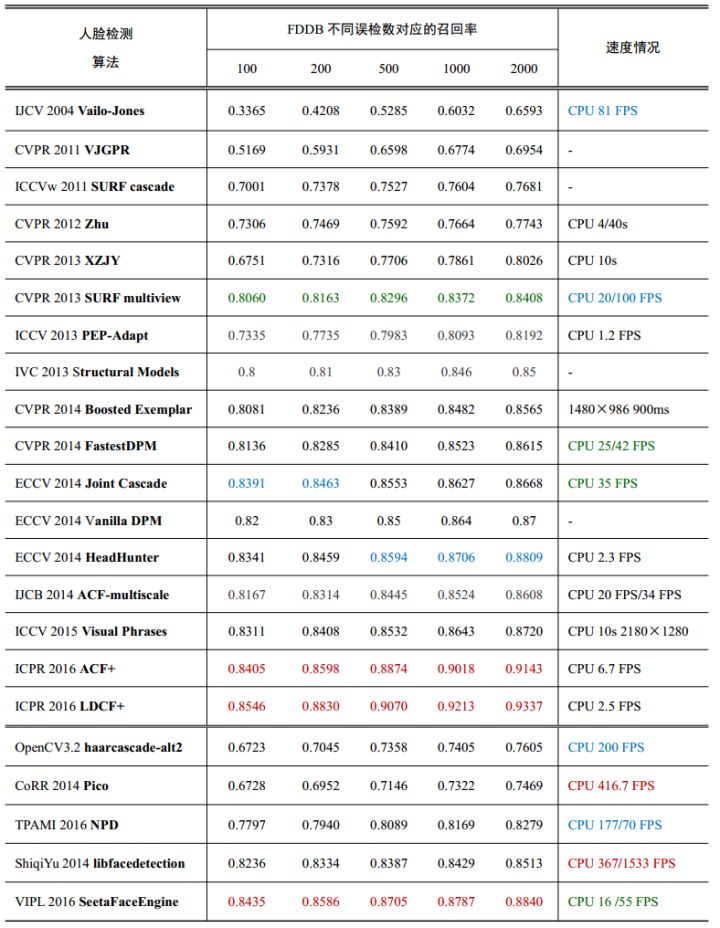
包括2011~2017年的非深度学习人脸检测方法,还有github上著名项目,深圳大学于仕琪老师的libfacedetection速度最快,和中科院山世光老师的SeetaFaceEngine中的人脸检测部分召回率很高。注意非深度学习方法有时候给出的速度是正脸检测模型,多角度模型通常慢数倍。
- 简单特征级联系列,有VJ框架不同特征(Haar-like, LBP, SURF), 有二值特征JointCascade, Pico, NPD,这系列占比较大,速度优势非常明显,在CPU上单核单线程就能实时,甚至上百FPS;
- DPM系列,有Zhu, Structured Models, vanilla DPM,性能中上但速度都比较慢,FastestDPM较快但也需要多线程才能实时;
- 通道特征(channel feature)系列,有HeadHuner, ACF-multiscale, ACF+和LDCF+,这一系列是非深度学习方法中性能最好的,仅ACF+和LDCF+在2000误检时超过了0.9,这两年非深度学习方法比较少,所以在WIDER FACE也只能看到ACF-multiscale和LDCF+。
深度学习的人脸检测算法比较:
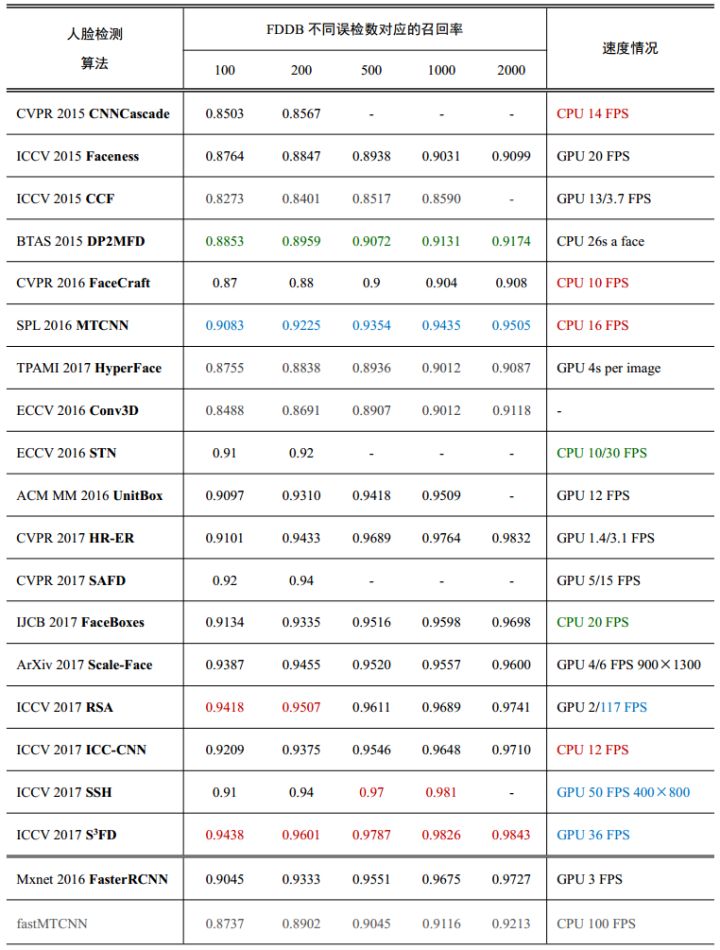
包括2015~2017的深度学习人脸检测方法,最后是我优化MTCNN的快速版本fastMTCNN。深度学习方法一般不会有正脸和多角度人脸模型的说法,速度都是召回率对应的。
这里跳过了一些只有report的方法,其中有腾讯的两个结果,基于Faster R-CNN的Face R-CNN,和基于R-FCN的Face R-FCN,在FDDB和WIDER FACE都是顶尖水平,说明Faster R-CNN/R-FCN在人脸检测中表现也很不错,不过并没有做速度方面的优化,都极慢就不关注了。
- 级联CNN系列,有CNN Cascade, FaceCraft, MTNN, ICC-CNN,这一系列是深度学习方法中速度最快的,CPU都在10 FPS以上,级联CNN系列优化后轻松可以在CPU上实时,全面优化后的fastMTCNN甚至可以在ARM上跑起来;
- Faster R-CNN系列,性能可以做到极高,但速度都很慢,甚至不能在GPU上实时;
- SSD/RPN系列:有SSH和SFD,都是目前FDDB和WIDER FACE上的最高水平,性能水平与Faster R-CNN系列不相上下,同时也可以保持GPU实时速度,SFD的简化版FaceBoxes甚至可以CPU上实时,极有潜力上ARM。
以上就是截至到2017.12.31的人脸检测算法召回率和速度情况,如有疏漏,欢迎补充。
最后,CNN到底能做到多快呢?我们拿非深度学习中最快的libfacedetection中的multiview_reinforce版本,和深度学习中我优化的fastMTCNN(MTCNN的加速版)做速度对比:
- 测试环境:multiview_reinforce是Intel(R) Core(TM) i7-4770 CPU @ 3.4GHz;fastMTCNN是Intel(R) Core(TM) i3-6100 CPU @ 3.7GHz,算是持平吧,我们仅比较单核单线程的速度。
- 速度测试:multiview_reinforce是640x480(VGA), 最小人脸48,速度109.3 FPS;fastMTCNN是640x480(VGA), 最小人脸80,速度100 FPS以上,这里multiview_reinforce略快一点点。这一对比其实也是公平的,因为MTCNN中有边框回归,实际检测的最小人脸在50以下,这一点如果您暂时不能理解,请根据最后部分实测。
- 性能测试:multiview_reinforce在FDDB上2000误检是0.85,fastMTCNN在FDDB上2000误检是0.92。这里需要强调,fastMTCNN的性能测试和速度测试的配置,仅最小人脸大小不同(20和80),而multiview_reinforce的性能测试和速度测试,除了最小人脸大小不同(16和48)之外,scale也不同,分别是1.08和1.2,做过人脸检测的都知道,这个意味着,如果按照速度测试的配置,multiview_reinforce的召回率还要掉一大截,或者说,如果按照性能测试的配置,multiview_reinforce的速度会慢很多。
当然libfacedetection一直在更新,这里对比的仅是2014年提交FDDB的召回率,用于证明深度学习在很高召回率的情况下,也可以做到实时。
深度学习的人脸检测算法实测
合理怀疑,fastMTCNN真的能跑这么快吗?如果您有兴趣,可以先测试一下MTCNN,看看优化之前有多快:
AlphaQi同学实现的C++版MTCNN-light: AlphaQi/MTCNN-light
代码有几处小错误需要修改,按照Issue 10 你好,这两个地方可能导致错误 · Issue #10 · AlphaQi/MTCNN-light,稍微修改一下就可以测试了。
另一个错误是mtcnn.cpp中596行,第三阶不应该再矫正为正方形:
refineAndSquareBbox(thirdBbox_, image.rows, image.cols);
另外,MTCNN-light的画框代码是写在检测里面的,这部分不应该计入检测时间。
C++版MTCNN-light只需要OpenBLAS和OpenCV就可以跑了,不需要其他第三方库,用于测试性能完全够用了,但请不要用于实际项目和产品中,因为代码问题较多,具体实现以kaipeng的MATLAB代码为准。动手实测,一起来感受一下吧:
- 输入VGA图像,最小人脸设置80,简单背景单人脸速度应该在40 fps以上。但复杂背景或人脸数量增加时,速度会严重下降,这就是级联算法的通病,在MTCNN中尤为严重,以后会详细分析成因和解决办法;
- 设置最小人脸80,实际检测到的最小人脸理论上可以到达52甚至更小。这是由于MTCNN是分类加回归的多任务方法(深度学习都是),回归机制可以检测到最大IoU = 0.65的更大人脸和最小IoU = 0.65更小人脸,这一点算是深度学习的天然优势吧,传统方法做不到。