老实说,评估了从传统VJ到深度学习人脸检测各种算法后,我还是喜欢LBP+级联Adaboost这种架构的人脸检测,毕竟,boost框架还是最快的。在某些限制性场景应用中,大量的扫描窗方式虽然很low,但可以通过各种方式优化。自己其实也训练出来了比CV demo好很多的模型,但是,很不幸,看到这篇文论,作者也开源了自己的模型。我就不高兴再去测试评估自己的模型了。。。
论文:https://lirias.kuleuven.be/bitstream/123456789/560283/2/VISAPP2017.pdf
参考:http://baijiahao.baidu.com/s?id=1568246787744922&wfr=spider&for=pc,略删改。
Abstract:
使用诸如卷积神经网络的复杂技术,计算机视觉几乎已经解决了在野外的人脸检测课题。相反,许多像opencv这样的开源计算机视觉框架还没有切换到这些复杂的技术,并且往往依赖于成熟的人脸检测算法,比如V-J所建议的级联分类流程。在FDDB等公共数据集上,这些基本面部检测器的准确率保持在较低水平,主要是由于假阳性的检测数量较多。我们提出了对现存的OpenCV人脸检测模型训练流水线的几种改进措施。我们改进了训练样本的生成和标注过程,并应用了主动学习(activelearning)策略。这大大提高了FDDB数据集人脸检测的准确性,缩小了基于CNN人脸检测的精度差距。这些提出的改进使我们为OpenCV提供了更先进的人脸检测模型,在可接受的recall下实现非常高的精度,而recall和presicion两个必要的条件使得进一步的处理成为可能,比如人员识别。
1 INTRODUCTION
人脸检测在计算机领域中是研究比较好的课题,而各种文献中也提出了良好的解决方案。但我们也注意到像OpenCV之类的开源计算机视觉框架,只提供基于现存机器学习技术的人脸检测器,但无法在公开的数据集达到很高的准确率。一个根本的原因可能是,大多数模型是在计算机视觉早期训练的,当时的学术研究仍然对较旧的级联分类器技术感兴趣,比如V-J结构的人脸检测。随着学术研究的发展,科研人员更倾向于发现更有前景的技术,如卷积神经网络,但失去了对成熟和经验证的算法的兴趣。这使得一个著名的计算机视觉库仍提供一个基础人脸检测器,仅在任何给定数据集上实现中等的检测结果。

图1:OpenCV的人脸检测
另一方面,来自工业界的用户致力于将这些开源计算机视觉框架转化为工业应用程序,不断改进现有的人脸检测技术的性能。他们的内部组织结构,不允许他们将精力放在提高当前算法的性能上。当尝试提高这些现存技术时有两个最大的问题,1.如何寻找可供训练的大量数据,2.当使用基础监测模型时,如何去报告在不同检测参数下学术研究所能达到的准确率上限。
为了弥补差距,我们决定研究在OpenCV内训练人脸检测器的级联分级结构,从而提高检测精度。为了达成这个目标,我们调整了人脸标注,改善负样本的收集,使用activelearning策略来迭代地增加hardpositive(在前面的级联器中,正样本被误检为负样本)和hardnegative(在前面的级联器中,负样本误检为正样本)样本增加到物体检测的过程中。
另外,我们认为,由于检测后处理步骤取决于可检测到的人脸,因此如图1所示,由于假阳性检测,人脸检测的工业应用将失败。在人脸识别应用的情况中,人脸检测是收集训练标注和测试标注的基础。因此,我们致力于改进Opencv3.1的人脸检测模型,基于LBP,希望能在可接受的召回率下得到极高的精度。
本文的其余部分的结构如下。第2节介绍相关研究,第3节讨论了使用的框架和数据集。接下来是第4节详细讨论提出的方法。最后第5节,详细阐述了获得的结果,而第6节作了总结第7节提出了未来可能的改进措施。
2 RELATED WORK
OpenCV框架是一个开源的计算机视觉框架,提供了一系列的技术,从基础的图像分割到复杂的3D模型构造。由于学术研究人员和工业合作伙伴的社区贡献,其规模稳步增长,增加了计算机视觉最近的算法,同时努力保持现有的基础算法的质量。我们注意到,一旦新功能集成了更长的时间并被社区大量使用,对该功能的改进就会停止。这可以解释为,计算机视觉社区对实际的相关工业实施没有兴趣,而是倾向于进一步推动最先进的技术。
计算机视觉最新的进展是通过各种复杂技术来解决人脸检测问题,比如多任务级联卷积神经网络,与3D信息配合的卷积神经网络,递归神经网络。这些技术产出了非常有前途的结果,但在实际应用中实现相当复杂。文档和支持的开源软件库仍然缺乏易用性。此外,我们注意到OpenCV正在为整合这些新技术铺平道路,但到目前为止,OpenCV框架内的性能仍然不能满足工业公司的要求。
Viola和Jones在使用弱分类器的增强级联器进行人脸检测已经有段时间了。目前为止,它是很多工业应用的正脸检测器,比如数码相机。缺点是许多公司使用软件来训练自己更复杂的面部检测模型,但不会与社区共享。这主要是由于OpenCV以BSD许可开源,允许公司使用代码,而不会分享任何重要的修改或改进。通过我们的工作,我们的目标是基于LBP来改进当前可用的正脸模型,并实现能够准确检测各种设置中的正面模型。
人们可以认为,用这种旧技术进行工作基本上是浪费时间投入。然而,一些最近的研究论文证明了对于特定的工业界的目标检测的任务,对于现存的技术的改进是至关重要的。
3 FRAMEWORK AND DATASET
为了构建我们的方法我们依赖于OpenCV3.1架构,这个架构由Intel组织和维护。我们着重使用C++接口下的CascadeClassifier物体检测功能和opencv_traincascade应用,包含使用V-J方法构建弱分类器的增强级联器的所有功能。
由于现存的Opencv人脸检测模型的训练数据已经无法获得,我们自己搜集了一系列人脸图片来训练我们的正脸模型。这些图像是从各种来源(YouTube视频)收集的,并在社交媒体,图像版和谷歌图像搜索结果中大量使用图像抓取工具。请注意所有的这些图片都没有标准的人脸标注。此外,我们创建了一个多线程工具,可以使用现有的人脸检测模型来有效地在给定视频中搜索有价值的人脸数据,然后可以将其再次添加到训练数据集中作为hardpositive和hardnegative样本。
为了训练我们的新模型,我们手工标注了1000个人脸区域作为正训练框,然后和750000负训练框合并,这些负训练框从大分辨率的负样本图片(不含人脸)中自动抓取。如表1所示,我们然后增加每个新迭代的正数据集250个额外的hardpositive样本。这些都是从一大堆正样本图像中收集出来的,我们知道这些图像有脸。每当初始检测器无法找到脸部区域时,需要进行手动干预,寻求面部标签,并将其作为训练样本添加到下一代训练样本中。用于训练我们最终的IterativeHardPositives+model的正样本训练集可以用过联系其中一位论文作者来得到。
为了验证我们的新模型并于现存的OpenCV基准进行比较,我们使用FDDB数据集。这个数据集包含来自LFW的2845张图,共有5171张脸。这个数据集致力于探寻无限制条件下人脸检测的极限。为了获得一个好的基准,我们将现有的图像注释转换为OpenCV使用的格式,并将其公开。
4 SUGGESTED APPROACH
在以下小节中,我们将讨论对现有级联分类器训练架构的不同调整,从而总体上提高性能,得到第5节的结果。
4.1 Changing the face’s region of interest during annotation
当仔细观察OpenCVLBP正脸检测的输出时,我们注意到,在许多情况下,检测输出包含完整的头部,包括耳朵,头发甚至背景信息。这是由于OpenCV训练集的标注问题。图2表示OpenCV旨在包含尽可能多的面部信息以馈送到训练算法。由于人脸检测器通用需求,因此我们专注于包含任何给定人脸数据中最常见特征的面部部分。为了减少非平凡面部信息,我们决定仅将内脸部区域标注为脸部,如图1的红色注释,并且与之前提出的近似地人脸检测技术相一致。这种方式有几个益处。它从boosting算法的特征池中减少了大量特征,从而减少了模型训练过程中需要评估的特征量。此外,内脸区域对旋转(平面内和平面外)具有更佳的鲁棒性。在第5节,我们详细阐述了这些在平面内和平面外旋转的部分。

图2:将人脸标注从整张脸到脸内部区域
4.2 Adapting the negative training sample collection
Opencv提供了一种从不包含对象的一组随机背景图像中自动收集负样本的方式。该算法将给定的负样本图像重新调整为不同的大小,并使用基于滑动窗口顺序收集负样本窗口,而后续窗口没有任何重叠。一旦完成了负样本图像的集合,就重复该过程并在每个图像中添加一个像素偏移,以获得略微不同的样本(在像素级)。如果多次遍历一个集合,则每次增加偏移量,则该过程等于应用像素移位滑动窗口方法,如图3(a)所示。虽然捕获数据中的微小差异的基本思想可能是个很好的起点,但是这种方法会产生大量的负面样本,这些样本不会为流程增加额外的有意义的知识,因此也不能被视为独一无二的样本。
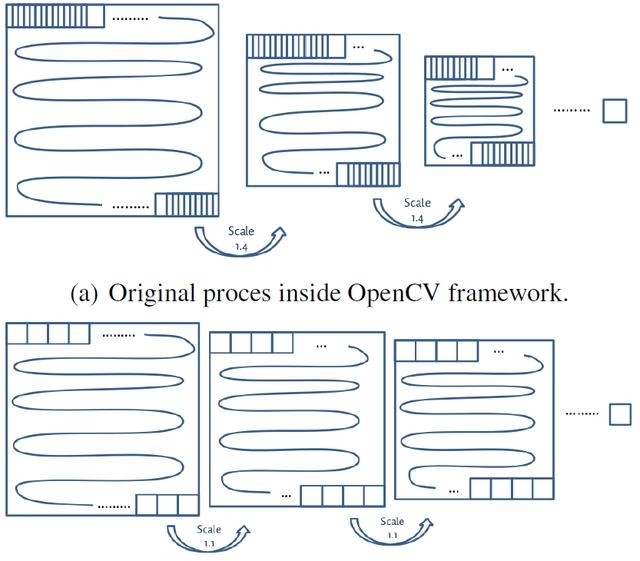
图3:负样本的收集调整
查看用于训练级联分类器的boosting过程,我们注意到,如果以前阶段不拒绝,每个新的负窗口可以作为新阶段的负训练样本。如果不同的负面样本只有轻微的像素移位,那么这个拒绝阶段会评估很多窗口,而我们已经知道它们将被拒绝。因此我们调整了接口删除了像素位移过程。通过删除这个过程并且在后续的负窗口没有重叠,我们也引入了有可能的损失,后续样本的边界周围有价值的信息无法共享。这个损失的信息有可能包含构建一个高鲁棒性的检测器的关键知识。为了减少信息的丢失,我们改进了图像金字塔中的尺度生成。在OpenCV生成尺度参数为1.4的图像金字塔情况下,我们决定降低此比例参数值1.1,以确保收集在不同金字塔尺度上的负样本足够多,同时保留尽可能多的有价值信息。这在图3(b)中说明。通过这样做,一个比例的样本边界丢失的信息将被前一个或后续的比例捕获。改进尺度金字塔的额外好处是,所得到的对象检测模型对目标的尺度变化鲁棒性更高,能够捕获更小的尺寸变化。
基于这些调整,收集大量的负样本数据是非常简单的,这是为在野外应用中创建强健的人脸检测模型所必需的。考虑到1080x1920的高分辨率图片,我们可以收集30000个负训练样本。这使得我们可以将我们训练的级联分类器中的每个阶段的负样本数量增加到数十万个样本,尝试将背景建模尽可能地好。这会使得每个阶段的训练时间增加,但会减少阶段数量,从而在检测时使得模型更快更简单更准确。
4.3 Iterative active learning strategy for hard training samples
为机器学习算法提供大量数据堆可以学习非常复杂的目标检测模型。不利的是,在收集正面和负面的训练数据时,很难判断哪个新的样本将真正提高检测模型的效率。为了确定哪些样本有添加到训练过程的实际价值,我们用一种称为activatelearning的技术。这个想法是使用上一次迭代训练的模型,并使用该模型告诉我们哪些样本是有价值的(接近决策边界),哪些是添加到下一个迭代训练过程的(没有歧义的标签),如图4所示。我们通过如下准确区分hardnegatives和hardpositive。此外,activelearning的优势在于我们大大限制了人工劳动的数量,因为我们只需要为新的训练样本提供标签,从而为受过训练的分类器添加额外的知识。
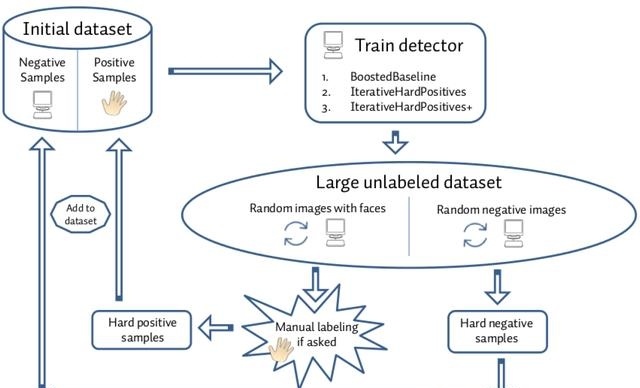
图4:active learning过程的概要图。
4.3.1 Hard negative samples
通过收集一组负样本图像,并在其运行我们先前训练过的面部检测器,来收集Hardnegative样本。在负窗口上,检测器仍有触发的那些就是我们当前模型需要的负样本。基本上,这些样本包含以前收集的负样本尚未捕获的信息,从而为训练过程提供有价值的信息。
4.3.2 Hard positive samples
通过收集包含面孔的大量未标记图像来收集hardpositive样本。我们只知道图像包含一个(或多个)人脸,但是我们没有标记的位置。在这些图像上,执行当前的人脸检测器(低检测确定性阈值),并且用软件跟踪不触发检测的图像。在这种情况下,要求操作者为这些未触发检测器图像手动选择面部区域,从而提供标签。该区域被存储为一个hard positive样本,仍然可以给模型学习界面足够多的有价值的知识,在如何学习模型方面。
4.4 Halting training when negative dataset is consumed
原始的OpenCV实现使用像素点偏移来抓取负样本,以避免在初始提供的数据集在第一次运行中完全消耗时停止训练。在4.2节中,我们已经描述了使用这些像素移位的窗口是过度的,并增加了大量的冗余数据。当负样本数据集完全消耗时,我们停止训练。一旦发生,就会有两种可能性。我们可以增加额外的图片到负样本图片集,或者我们在停止训练之前,返回最后阶段抓取的负样本数量。这允许操作者使用这个确定数量的样本来确定最后一个阶段,并且因此使用每一个负样本窗口训练模型,从而完全消耗可用的负样本数据集。
4.5 Using the adaptations to train different face detection models
通过巧妙地组合4.1,4.2和4.3提出的所有调整,我们训练了不同的人脸检测模型,我们尝试迭代地提高获得模型的准确性。表1描述了用于这些模型的训练数据,结合训练模型的阶段数量和boosting过程中所选择的特征(每个形成stump/二进制决策树)的数量。

表1:不同模型的训练数据
我们第一个模型(简称'BoostedBaseline')可以被看作是我们通过应用activelearning策略迭代尝试改进的基准。我们限制训练为单层决策树。人们可能会认为,使用更复杂的决策树是有利可图的,但以前的研究表明,使用更复杂的决策树实际上会减慢检测过程,因为更多的特征需要在早期阶段进行评估。对于每个boostedlearning的模型,当增加特征数量时,性能的提高应该比提高复杂度重要,从而降低处理时间。当收集的随机负样本背景图片被完全消耗时,我们的模型训练停止。
对于第二个模型,称为“IterativeHardPositives”,我们通过activelearning程序添加了250个hardpositive训练样本,尝试提高检测器的召回率。我们也收集了一系列hardnegatives集合,并将它们添加到训练集中。我们注意到,添加这些额外质量的样品推动了召回率,同时略微提高了精确率。通过提供250个额外的hardpositive样本,再次改进了第三个也是最后一个模型,称为(IterativeHardPositives+),试图进一步提高召回率。
5 RESULTS
5.1 Performance of trained models
图5比较了FDDB测试数据集上的第4.5节与OpenCVBaseline检测器的训练好的模型。使用presicion-recall图来测量性能。我们注意到,通过OpenCVbaseline(黑色曲线),我们训练的模型(绿色,红色和蓝色曲线)有大大的改善。OpenCV基准模型在它的最佳点只能以40%(所有返回的检测框,只有4成是真正的物体)的精度实现约40%(10个物体只有4个被检测到)的回归。当然我们可以做出权衡,以牺牲精度的方式获得更高的精度。尽管如此,目前的OpenCV模型无法在给定的FDDB数据集中确定高于50%的目标对象,因为在非常具有挑战性的条件下包含各种各样的面孔。
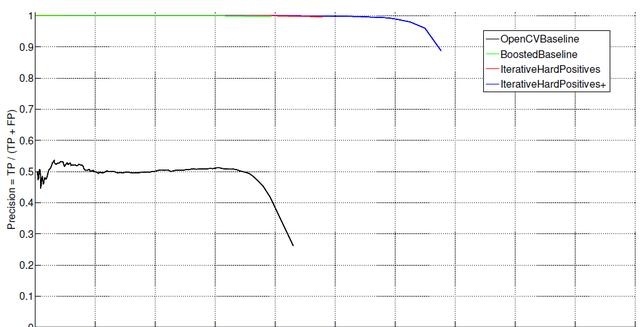
图5:FDDB数据集上所有模型的Precision-Recall曲线。
与OpenCVBaseline检测器相比,该模型的最佳召回率为40%,我们的Boosted-Baseline检测器已经将精度提升到99.5%,几乎完全消除了假阳性的存在。此外,如图6中的特写所示,我们的每个随后的模型都会进一步增加召回率,而不会牺牲本来就非常高的精度。在召回率为60%时,与OpenCVBaseline检测器相比增加了50%,我们的IterativeHardPositives+检测器只有轻微地下降到99%的精度。作为最佳工作点,我们的IterativeHardPositives+模型达到了90%的精度,召回率为68%。

图6:我们检测模型的PR曲线的特写
虽然许多关于人脸检测的论文使用precision-recall曲线来有效地比较检测模型,但官方FDDB评估标准是基于准确率和falsepositve检测数量的曲线。如图7所示,我们也包含了OpenCVBaseline检测器和IterativeHardPositive+检测器的比较。我们还将我们的技术与基于神经网络的最先进的人脸检测算法进行比较,比如FastRCNN和MultiTaskCNN。这清楚地表明,我们已经缩小了级联分类器和神经网络之间的差距,同时仍然有改进的余地。

图7:FDDB数据集的评估,与基于神经网络的算法比较。
5.2 Influence of adaptations to processing time
有一点必须要保证,那就是增加这些额外的训练数据集不会在检测时间内使模型过于复杂和缓慢。如表1所示,我们对树桩分类器所使用的特征有限度的增加,同时增加了50%的有价值的正样本训练数据。此外,我们模型的阶段数量反而下降。由于处理时间是嵌入式系统中使用计算机视觉方法的关键特性,因此我们可以自由地在整个FDDB测试集上测量处理时间,这可以从表2中看出。考虑到测试图像的平均分辨率为400x300像素,我们会平均计算每个图像接受定时的时间。这些时间是在Intel(R)Xeon(R)CPUE5-2630v2系统设置下执行的。我们的OpenCV构建使用线程构建块进行优化,用于并行处理。我们清楚地看到,尽管我们在我们的模型中使用了更多的特征,但IterativeHardPositives+模型的处理时间并不超过OpenCVBaseline模型的处理时间。此外,如果我们使用BoostedBaseline或IterativeHardPositives检测器,我们比OpenCVBaseline检测器更快地处理图像。

表2:各种模型的时间比较
5.3 A visual confirmation
图8显示了我们算法的一些可视化检测输出。我们首先选择低检测确定性阈值(图8(a)),这清楚地表明两个模型都能够找到人脸,但是立即显示了OpenCV模型的缺点,这产生了大量的假阳性检测。我们将检测确定性阈值提高到中等水平(图8(b)),并注意到OpenCV和我们自己的训练模型都能够找到人脸,但是OpenCV会逐渐错过一些脸孔,而我们的模型仍然能检测到。最后,当设置高检测确定性阈值(图8(c))时,我们看到OpenCV错过了很多我们的模型仍能找到的脸孔。但即使我们的模型检测到比OpenCV更多的面孔的情况下,我们仍然会发现两个模型都失败的情况,或者OpenCV实际上找到了我们的模型未捕获的情况,如图8(d)所示。这些未被发现的面孔可以用作hardpositive训练样本,但是为了不引入数据集偏差,我们需要找到一个新的数据库进行评估。

图8:检测结果
5.4 Testing out-of-plane rotation robustness
如4.1节所述,减小标注区域,将直接影响检测器返回的人脸区域,有助于改善人脸检测器的out-of-plane旋转的鲁棒性。为了测试这个,我们在头部图像数据库上评估了OpenCVBaseline和IterativeHardPositive+检测器,如图9所示。这个数据集包含一组30个序列(15个人,每人人两个序列),其中人们依次观察不同的位置,每个位置与pan(【-90,,9】)和titl(【-60,60】)角度相关联。对每一个姿势,我们都同时运行了两种检测器并返回模型的检测确定性,并对30个序列做平均。我们使用数据集上的最高返回检测分数作为我们得分范围的外界,并将所有其他值在最大值基础上归一化。我们看到在pan和tilt角度评估中,我们的IterativeHardPositives+检测器明显优于OpenCVBaseline检测器。特别是在tilt角度图上,我们可以在效率上看到极大的提高。这个额外的测试也证实了对于一个完整的正脸,IterativeHardPositives+检测器大概比OpenCVBaseline检测器拥有两倍的置信度,如图5所示。

图9:out-of-plane旋转鲁棒性测试
6 CONCLUSIONS
本文的目的是提出建议,对开源计算机视觉框架OpenCV中当前现有的级联分类器架构进行调整,着眼于改进其正脸检测器模型。我们的目标是通过保证高精度,同时保持尽可能高的召回率,以尽可能多的检测面部来减少大量的假阳性检测。我们在公开的FDDB人脸数据集上测试了我们的方法,并证明了我们对训练架构的调整产生了巨大的性能提升。在使用IterativeHardPositives+检测器时,我们将召回率提高到68%,同时保持90%的高精度。相比之下,目前的实现中在40%召回率下精度只有40%,我们的结果相当令人印象深刻。
对于框架和模型的调整显然对于现存的模型训练有好处。想象一下,人脸检测器的输出是用来做人脸识别的。这种情况下,我们的目标是尽可能高的精度,因为我们希望确保实际检测的管道中,提供的是真实的面孔而不是无效检测图。此外,与OpenCVBaseline模型相比,我们的模型能够在野外环境找到更多的人脸,并且对于out-of-plane的旋转更具有鲁棒性。
我们应该明白,如图8(d)所示,由于某些极端的out-of-plane旋转,我们将永远不会再数据集(比如FDDB)达到100%的召回率。然而,人们可以认为,out-of-plane旋转角度大于45度的人脸应该由侧脸检测器找到,并且和正脸检测器一起合作检测。
7 FUTUREWORK
作为未来的工作,我们建议进一步推动OpenCV框架中人脸检测器模型的准确性。我们还有空间增加hardpositive的样本,旨在提高召回率。一个好的起点可以是在FDDB数据集上运行我们的IterativeHardPositives+检测器,然后搜集hardpositive人脸作为训练数据。然而这将迫使我们找到新的测评数据集来避免数据集偏见。
目前模型仅对于in-plane旋转进行评测。我们可以构建图像的旋转3D矩阵,并应用我们的IterativeHardPositives+检测器多次合并这些in-plane旋转。这将使我们能够找到更多的面孔,进一步推动我们的架构的表现。