前言
今天我们继续来学习【Java Web】部分的XML,XML相比其他部分来时还是非常简单的。我们在以后写大项目时候也会经常用到,所以说还是蛮重要的。
接下来我们正式开始XML的学习。
XML概述
基本概念:
可扩展标记语言(Extensible Markup Language,XML),可扩展意味着标签是自定义的。
XML用途:
XML主要用来存储数据、作为配置文件、在网络中传输等。
XML特点:
(1)XML是一种标记语言,很类似 HTML
(2)XML的设计宗旨是传输数据,而非显示数据
(3)XML没有预定义标签。使用时都需要自行定义标签
(4)XML是一种非常灵活的语言,没有固定的标签,所有的标签都可以自定义。
XML和HTML区别:
(1)XML标签是自定义的,HTML标签是预定义的。
(2)XML的语法严格,HTML语法松散。
(3)XML 和 HTML 为不同的目的而设计:
XML 被设计为传输和存储数据,其焦点是数据的内容。
HTML 被设计用来显示数据,其焦点是数据的外观。
HTML 旨在显示信息,而 XML 旨在传输信息。
XML语法
同其它语言一样XML语言也有着自己的语法。具体如下:
(1)xml文档的后缀名为 .xml。
(2)xml第一行必须定义为文档声明。
(3)xml文档中有且仅有一个根标签。
(4)属性值必须使用单引号(单双都可)引起来而且属性值是唯一的。
(5)xml标签必须正确关闭,也即要么是自闭和标签,要么是围堵标签。
(6)xml标签名称区别大小写。
我们来实现一个XML文件吧!如下:
<!--人力资源管理系统-->
<?xml version="1.0" encoding="utf-8"?>
<hr>
<employee no="7706">
<name>张三</name>
<age>31</age>
<salary>5000</salary>
<department>
<dname>技术部</dname>
<address>xx大厦-B104</address>
</department>
</employee>
<employee no="7707">
<name>李四</name>
<age>29</age>
<salary>4000</salary>
<department>
<dname>会计部</dname>
<address>xx大厦-B106</address>
</department>
</employee>
</hr>
像这个它就是一个格式良好的XML文件。
第一行代码是声明部分,记住这里的 encoding的值不能省略都得写上。
其中根节点为<hr></hr>有且仅有一个。
由于XML中的标签都是我们自定义的,所以我们一眼看上去就知道这个文件表达的是什么,描述的是什么。所以我们在自定义标签的时候也要定义有意义的标签名。
介绍CDATA区,在该区域中的数据会被原样展示,格式为:<![CDATA[数据]]>
XML的约束
一个有效的XML文档有以下特点:
(1)首先必须是格式良好的。
(2)使用DTD和XSD(XML Schema)定义约束。
格式良好就是向我们上面的这个XML文件一样,标签有意义,语法也没有问题等。拿什么是约束呢?
比如说这里有定义人的年龄,那么如果数据输入的时候出错了,把年龄定义成为负数了,这可以吗?这肯定不行,不带这么离谱的。
但是XML文件它又无法检查出来这个错误,因为它是内容是自由的,这时候我们就得给它引入约束了,对其中的数据、标签等进行约束等。
编写一个文档来约束一个xml文档的书写规范,这称之为XML约束。
XML约束又分为DTD和XSD,接下来我们继续来讲一下这两种约束。
DTD约束
一个完整的DTD声明主要有由三个基本部分组成:元素声明、属性声明、实体声明。
元素声明:
基本语法为:
<!ELEMENT 元素名 元素内容模型>
使用!ELEMENT声明一个元素,接下来是元素名也就是标签名,元素内容模型跟在元素名的后边。
一个元素的内容模型定义了可允许的元素内容。一个元素可能包含一个子元素、一段文本或子元素域文本的组合,也允许元素内容为空。
在XML中元素中可以有子元素,我们可以通过DTD来定义某个元素中可以包含哪些子元素,为了限制一个元素中可以包含哪些子元素,我们只需将子元素名写在父元素后边的()中。
如之前department标签下有dname和address标签,然后我们就可以这样写
<!ELEMENT department (dname,address)>
之前的hr标签下有多个employee标签,我们也可以在()后面加个*代表有0个或者多个employee标签。
<!ELEMENT hr (employee)*>
还可以使用其他符合?表示一次或零次,+表示一次或多次,*表示零次或多次。
employee标签下还有name,age,salary,department等标签,我们可以把他们这样写:
<!ELEMENT employee (name,age,salary,department)>
使用,分隔代表子元素必须按照这样的顺序出现,否则报错。如果对于顺序没有要求那么我们可以使用|去分隔子元素。如下:
<!ELEMENT employee (name|age|salary|department)>
如果元素中的内容是纯文本的内容,使用#PCDATA定义:
<!ELEMENT name #PCDATA>
如果元素仅仅是一个空元素,也称为自结束标签我们可以使用EMPTY来定义:
<!ELEMENT br EMPTY>
ANY表示在元素中可以定义任意内容:
<!ELEMENT test ANY>
属性声明:
使用ATTLIST关键字声明元素中的属性
<!ATTLIST employee no CDATA "">
上边这个例子为employee元素声明一个no属性
那么我们在什么写好DTD文件之后又该如何将DTD文件与XML文件绑定在一起呢?
格式如下:
<!DOCTYPE 文档根节点 SYSTEM "dtd文件路径">
我们只需要把这一段卸载XML文件中声明的下一行即可。
接下来我们完成一个对之前XML文件的约束文件的编写:
<?xml version="1.0" encoding="UTF-8" ?>
<!ELEMENT hr (employee)*>
<!ELEMENT employee (name,age,salary,department)>
<!ATTLIST employee no CDATA "">
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT salary (#PCDATA)>
<!ELEMENT department (dname,address)>
<!ELEMENT dname (#PCDATA)>
<!ELEMENT address (#PCDATA)>
XSD约束
XSD即XML Schema,XML Schema 的作用是定义 XML 文档的合法构建模块。
XSD的作用:
(1)定义可出现在文档中的元素
(2)定义可出现在文档中的属性
(3)定义哪个元素是子元素
(4)定义子元素的次序
(5)定义子元素的数目
(6)定义元素是否为空,或者是否可包含文本
(7)定义元素和属性的数据类型
(8)定义元素和属性的默认值以及固定值
XML Schema 最重要的能力之一就是对数据类型的支持
<schema> 元素是每一个 XML Schema 的根元素。
定义简易元素的语法:
<element name="标签名" type="元素类型"/>
常见的数据类型有:
string表示字符串类型
decimal表示小数类型
integer表示整数类型
boolean表示布尔类型
date表示日期类型
time表示时间类型
定义属性的语法是:
<attribute name="属性名" type="属性的数据类型"/>
其次关于 XML Schema 的重要特性是,它们由 XML 编写。
接下来我们使用XSD来对XML文件进行约束。
<?xml version="1.0" encoding="UTF-8" ?>
<schema xmlns="http://www.w3.org/2001/XMLSchema">
<element name="hr">
<!--complexType是复杂节点,包含子节点时必须使用它-->
<complexType>
<sequence>
<element name="employee" minOccurs="99">
<complexType>
<sequence>
<element name="name" type="string"></element>
<element name="age" >
<simpleType>
<restriction base="integer">
<!--年龄最小为18,最大为60-->
<minInclusive value="18"></minInclusive>
<maxInclusive value="60"></maxInclusive>
</restriction>
</simpleType>
</element>
<element name="salary" type="integer"></element>
<element name="dapartment">
<complexType>
<sequence>
<element name="dname" type="string"></element>
<element name="address" type="string"></element>
</sequence>
</complexType>
</element>
</sequence>
<attribute name="no" type="string" use="required"></attribute>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
在XML中引用XSD约束:
<hr xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="文件路径">
加到XML定义下面即可。
XML解析
XML解析就是对XML文件进行读写等操作,我们使用dom4j对XML进行解析。下面是对dom4j的一些介绍:
dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的。dom4j是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件,可以在SourceForge上找到它.对主流的Java XML API进行的性能、功能和易用性的评测,dom4j无论在那个方面都是非常出色的。如今你可以看到越来越多的Java软件都在使用dom4j来读写XML,例如Hibernate,包括sun公司自己的JAXM也用了Dom4j。
我们直接使用代码来进行讲解练习
对之前的XML文件进行读出操作:
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.sql.SQLOutput;
import java.util.List;
public class HrReader {
public void readXml() {
String file = "d:/Java/Java Web/XML/src/hr.xml";
//SAXReader是读取XML文件的核心类,用于将XML解析之后以树的形式保存在内存
SAXReader reader = new SAXReader();
try {
Document document = reader.read(file);
//获取XML文档的根节点,即hr标签
Element root = document.getRootElement();
//elements方法用于获取指定的标签集合
List<Element> employees = root.elements("employee");
for(Element employee:employees){
//emement方法用于获取唯一的子节点对象
Element name = employee.element("name");
//getText()用于获取标签文本值
String empName = name.getText();
System.out.println(empName);
System.out.println(employee.elementText("age"));
System.out.println(employee.elementText("salary"));
Element department = employee.element("department");
System.out.println(department.element("dname").getText());
System.out.println(department.element("address").getText());
Attribute att = employee.attribute("no");
System.out.println(att.getText());
}
}catch(DocumentException e){
e.printStackTrace();
}
}
public static void main(String[] args) throws DocumentException {
HrReader reader = new HrReader();
reader.readXml();
}
}
输出:
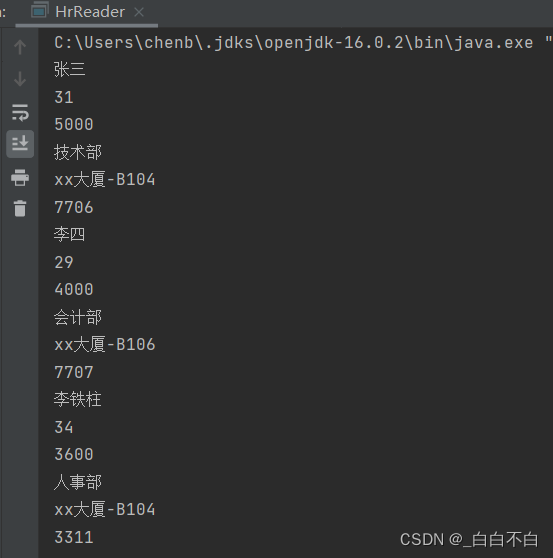
对之前的XML文件进行写入操作:
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.sql.SQLOutput;
import java.util.List;
public class HrReader {
public void readXml() {
String file = "d:/Java/Java Web/XML/src/hr.xml";
//SAXReader是读取XML文件的核心类,用于将XML解析之后以树的形式保存在内存
SAXReader reader = new SAXReader();
try {
Document document = reader.read(file);
//获取XML文档的根节点,即hr标签
Element root = document.getRootElement();
//elements方法用于获取指定的标签集合
List<Element> employees = root.elements("employee");
for(Element employee:employees){
//emement方法用于获取唯一的子节点对象
Element name = employee.element("name");
//getText()用于获取标签文本值
String empName = name.getText();
System.out.println(empName);
System.out.println(employee.elementText("age"));
System.out.println(employee.elementText("salary"));
Element department = employee.element("department");
System.out.println(department.element("dname").getText());
System.out.println(department.element("address").getText());
Attribute att = employee.attribute("no");
System.out.println(att.getText());
}
}catch(DocumentException e){
e.printStackTrace();
}
}
public static void main(String[] args) throws DocumentException {
HrReader reader = new HrReader();
reader.readXml();
}
}
XPath表达式
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
节点(Node):
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
XPath 路径表达式:
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
选取节点:
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的
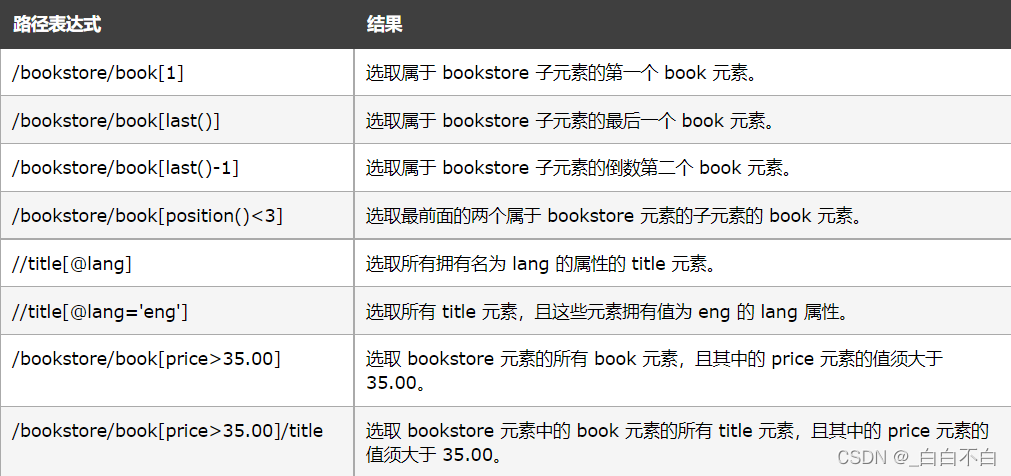
常用的路径表达式:

对应实例:

带谓语的路径表达式实例:
下面是对XPath路径表达式的一些练习
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import java.util.List;
import java.util.zip.DataFormatException;
public class XPathTestor {
public void xpath(String xpathExp){
String file = "d:/Java/Java Web/XML/src/hr.xml";
SAXReader reader = new SAXReader();
try {
Document document = reader.read(file);
List<Node> nodes = document.selectNodes(xpathExp);
for(Node node : nodes){
Element emp = (Element) node;
System.out.println(emp.attributeValue("no"));
System.out.println(emp.elementText("name"));
System.out.println(emp.elementText("age"));
System.out.println(emp.elementText("salary"));
System.out.println("================================");
}
} catch(DocumentException e){
e.printStackTrace();
}
}
public static void main(String[] args) {
XPathTestor testor = new XPathTestor();
//testor.xpath("/hr/employee");
//testor.xpath("//employee");
//testor.xpath("//employee[salary<4000]");
//testor.xpath("//employee[name='张三']");
//testor.xpath("//employee[@no=7706]");
//testor.xpath("//employee[1]");
//testor.xpath("//employee[last()]");
//testor.xpath("//employee[position()<3]");
testor.xpath("//employee[1] | //employee[3]");
}
}