
三种join的方式
Simple Nested-Loop Join
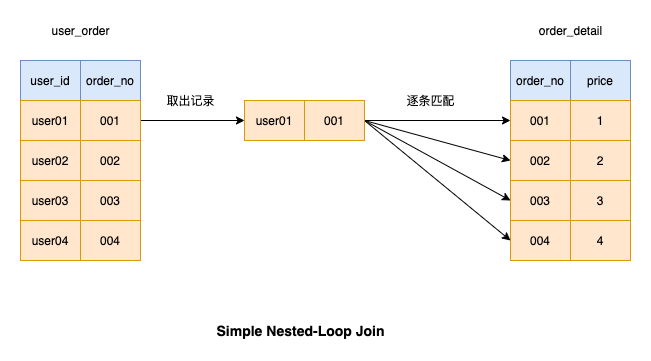
效率最低mysql没有采用
Block Nested-Loop Join
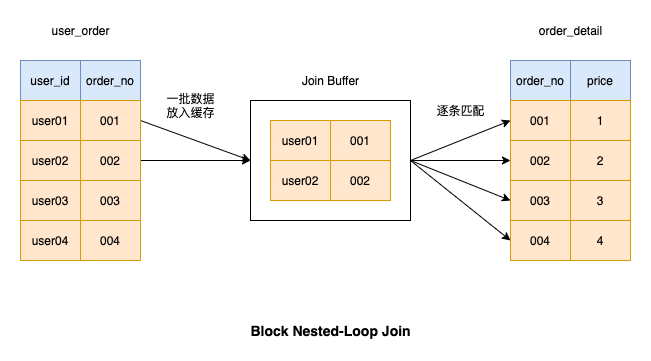
show variables like '%join_buffer%'
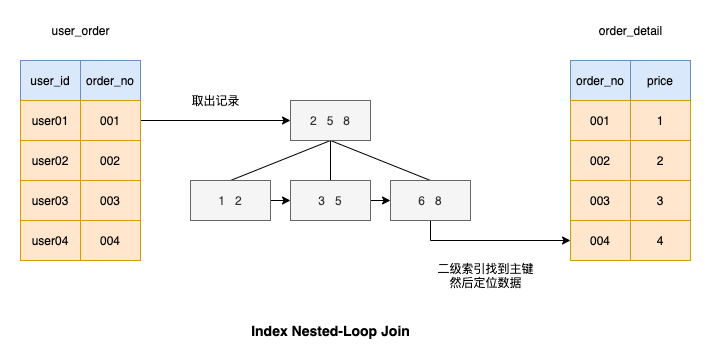
Index Nested-Loop Join
CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
drop procedure idata;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=1000)do
insert into t2 values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
create table t1 like t2;
insert into t1 (select * from t2 where id<=100)
select * from t1 straight_join t2 on (t1.a=t2.b);
假设驱动表的行数是M,因此需要扫描驱动表N行
被驱动表的行数是N,每次在被驱动表查一行数据,要先搜索索引a,再搜索主键索引。每次搜索一颗树近似复杂度是以2为底N的对数,所以在被驱动表上查一行的时间复杂度是2*
驱动表的每一行数据都要到被驱动表上搜索一次,整个执行过程近似复杂度为 M + M ∗ 2 ∗ l o g 2 N M + M*2*log2^N M+M∗2∗log2N
显然M对扫描行数影响更大,因此应该让小表做驱动表。当然这个结论的前提是可以使用被驱动表的索引
当explain的结果里面,extra字段有没有出现 Block Nested Loop 字样
小表做驱动表
将join_buffer_size的大小放大
参考博客
[1]