join语句怎么优化
mysql中一般使用的是Index Nested-Loop Join(NLJ)和Block Nested-Loop Join(BNL)。
(对应被驱动表有索引和没有索引的两种情况)
我们发现在使用NLJ算法的时候,效果还是不错的;
但是,BNL算法在大表join的时候性能就差多了,比较次数等于两个表参与join的行数的乘积,很消耗CPU资源。
那这两个算法又怎么近一步优化?
Index Nested-Loop Join(NLJ) ----------> Batched Key Access
Block Nested-Loop Join(BNL) ---------->
Index Nested-Loop Join(NLJ) 优化
首先我们得明白:利用被驱动表索引时,是根据回表获取主键id,然后根据主键id获取所需要的数据的。
Index Nested-Loop Join(NLJ) 存在的问题:
因为根据主键id获取所需要的数据时,需要一行行的扫描数据表——进而匹配id,然而对于主键id又不一定是连续的,这种情况会造成数据表的重复扫描。
如果按照主键的递增顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能。
- 根据索引a,定位到满足条件的记录,将id值放入read_rnd_buffer中;
- 将read_rnd_buffer中的id进行递增排序;
- 排序后的id数组,依次到主键id索引中查记录,并作为结果返回。
这个称为Multi-Range Read优化,在这个基础上就有了mysql中的Batched Key Acess(BKA)算法。
Batched Key Acess(BKA)示意图如下:
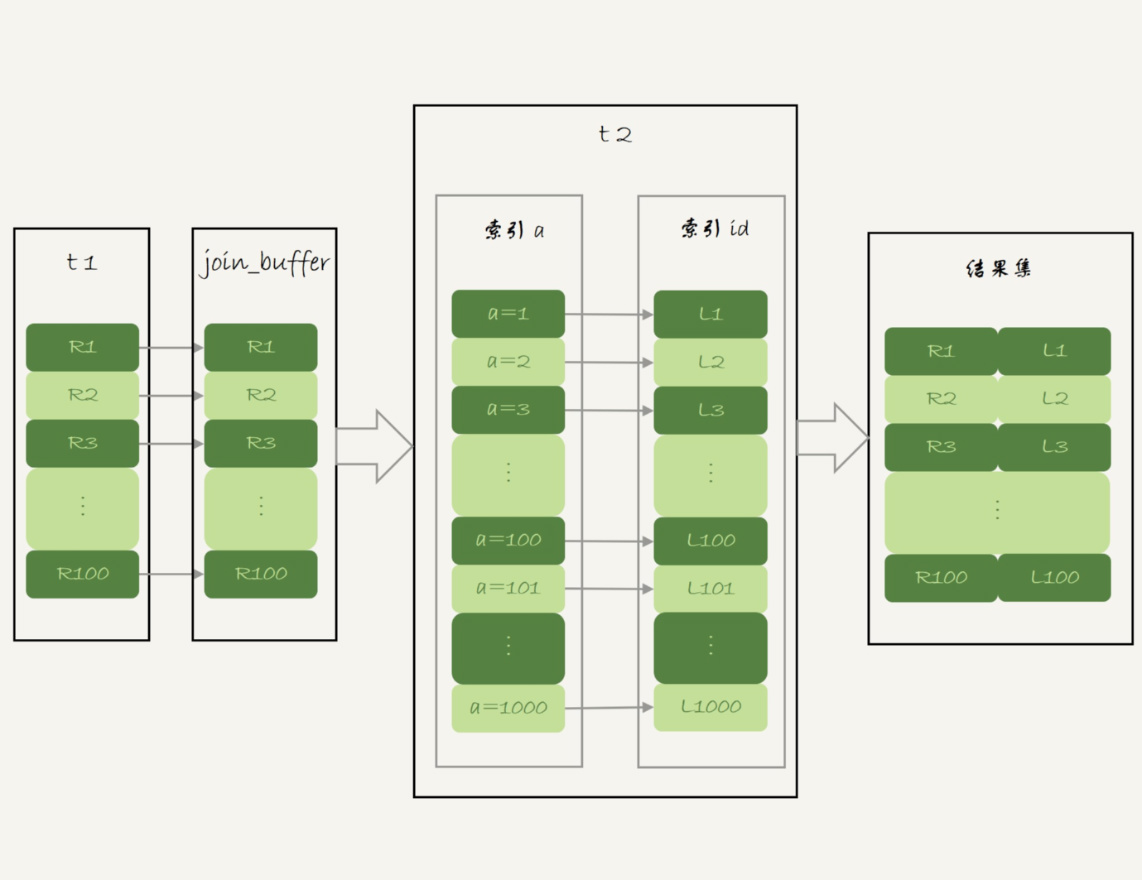
到这里,我们小结一下。
MRR能够提升性能的核心在于,这条查询语句在索引a上做的是一个范围查询(也就是说,这是一个多值查询),可以得到足够多的主键id。这样通过排序以后,再去主键索引查数据,才能体现出“顺序性”的优势。
Block Nested-Loop Join(BNL) 优化
Block Nested-Loop Join(BNL) 算法对系统的影响主要包括三个方面:
-
可能会多次扫描被驱动表,占用磁盘IO资源;
-
判断join条件需要执行M*N次对比(M、N分别是两张表的行数),如果是大表就会占用非常多的CPU资源;
-
可能会导致Buffer Pool的热数据被淘汰,影响内存命中率。
对于Block Nested-Loop Join(BNL) 优化有以下3种办法进行解决:
第1种、直接在被驱动表上建索引,这时就可以直接转成BKA算法了。
第2种、使用临时表
在所需要的数据占总数据量的比重不大,建立索引不划算——这时候可以将这部分数据读取出来,在临时表中建立索引。
第3种扩展-hash join
总结
优化Index Nested-Loop Join(NLJ)——Batched Key Access:
- 与被驱动表匹配时,对索引获得主键id进行排序后,在根据id查找记录。
优化Block Nested-Loop Join(BNL) :
- 直接在被驱动表上建索引,这时就可以直接转成BKA算法了。
- 在使用临时表
- 扩展-hash join