Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Hugging Face bert-base-chinese 使用
Hugging Face
构建未来的人工智能社区,构建、训练和部署由机器学习中的参考开源支持的最先进模型。
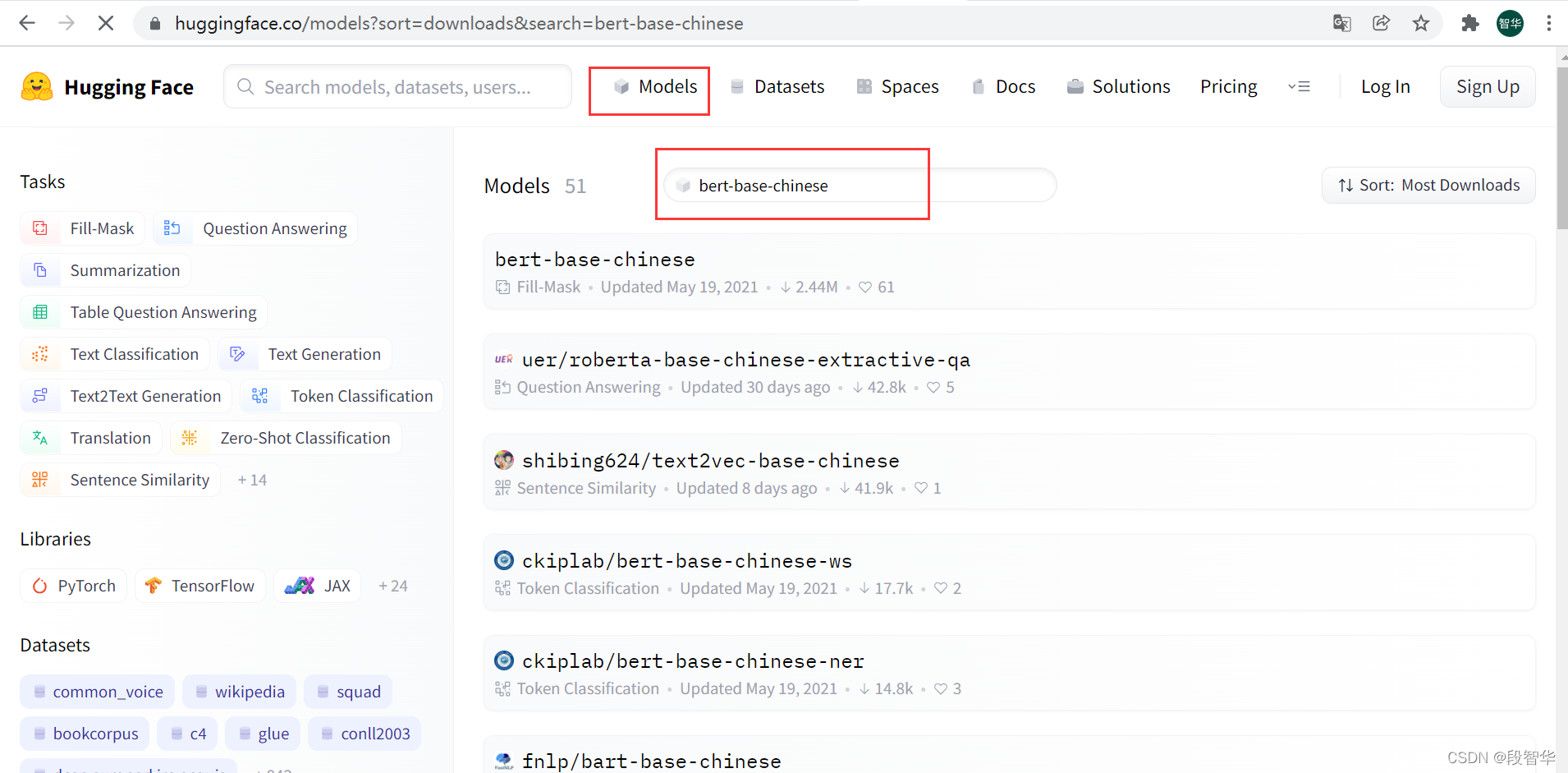
模型下载 bert-base-chinese
下载地址 https://huggingface.co/models?sort=downloads&search=bert-base-chinese
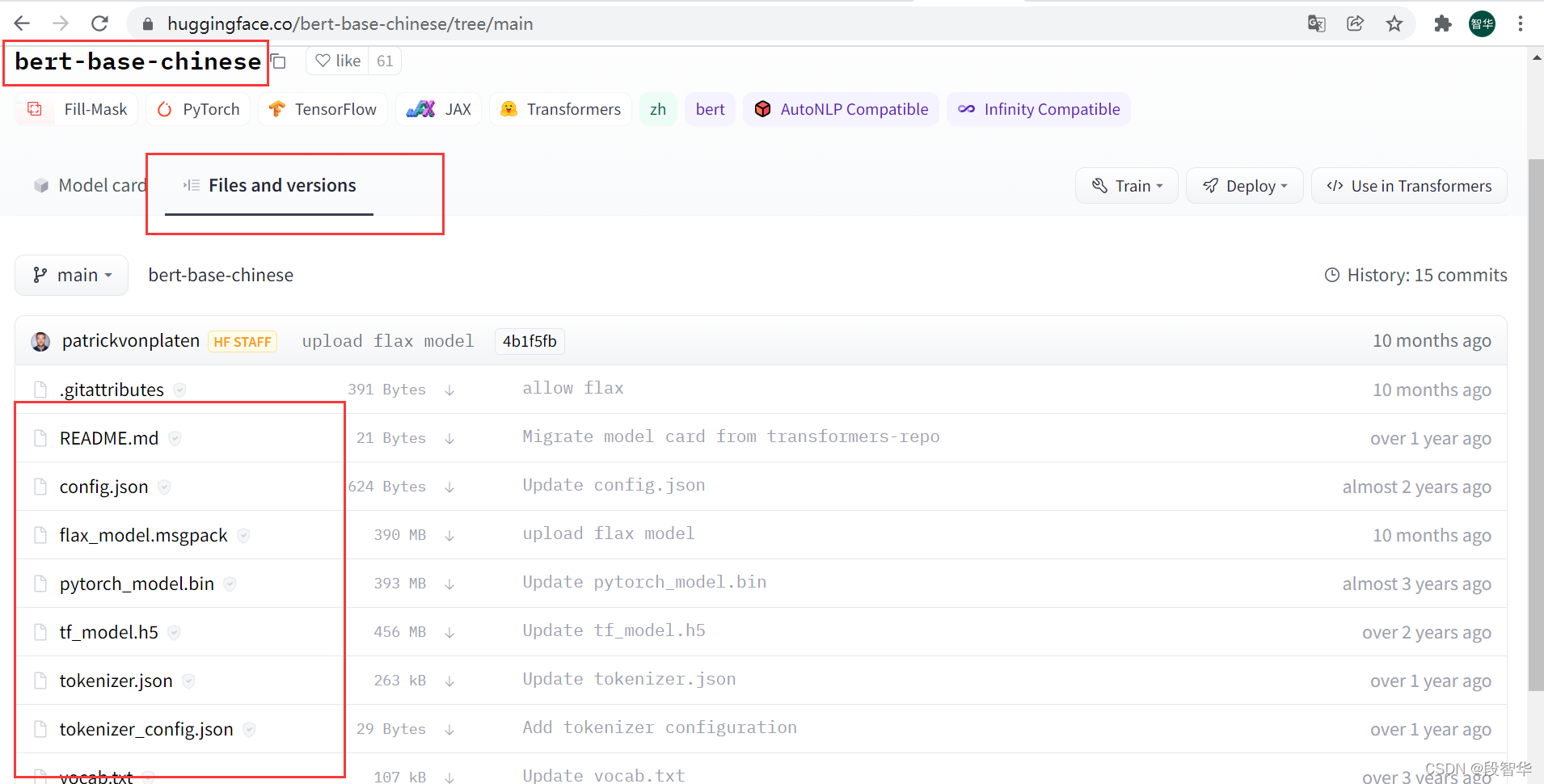
下载模型文件
如果因网络原因不能下载,读者也可以在网盘下载Tensorflow的bert-base-cased模型
链接:https://pan.baidu.com/s/1KyAUdEdEXi3v1-HyNajNQg
提取码:4xd0
Tensorflow模型的测试代码,模型自动下载保存到’C:\Users\admin/.cache\huggingface\transformers’。
# -*- coding: utf-8 -*-
from transformers import AutoTokenizer, TFAutoModel
model_name="bert-base-chinese"
text = "this is a test"
tokenizer = AutoTokenizer.from_pretrained(model_name)
text_tensor = tokenizer.encode(text, return_tensors="tf")
print(text_tensor)
model = TFAutoModel.from_pretrained(model_name)
output = model(text_tensor) #
print(output)
在E:\anaconda3\envs\installingrasa\Lib\site-packages\transformers\file_utils.py 代码中,
也可以修改Tensorflow 默认的缓存地址为指定的目录:(本文保存的目录为D:\2022_NOC_AI_RASA_NEW\bert-base-cased)

运行结果:

tensorflow框架的file_utils.py代码
def cached_path(
url_or_filename,
cache_dir=None,
force_download=False,
proxies=None,
resume_download=False,
user_agent: Union[Dict, str, None] = None,
extract_compressed_file=False,
force_extract=False,
use_auth_token: Union[bool, str, None] = None,
local_files_only=False,
) -> Optional[str]:
"""
Given something that might be a URL (or might be a local path), determine which. If it's a URL, download the file
and cache it, and return the path to the cached file. If it's already a local path, make sure the file exists and
then return the path
Args:
cache_dir: specify a cache directory to save the file to (overwrite the default cache dir).
force_download: if True, re-download the file even if it's already cached in the cache dir.
resume_download: if True, resume the download if incompletely received file is found.
user_agent: Optional string or dict that will be appended to the user-agent on remote requests.
use_auth_token: Optional string or boolean to use as Bearer token for remote files. If True,
will get token from ~/.huggingface.
extract_compressed_file: if True and the path point to a zip or tar file, extract the compressed
file in a folder along the archive.
force_extract: if True when extract_compressed_file is True and the archive was already extracted,
re-extract the archive and override the folder where it was extracted.
Return:
Local path (string) of file or if networking is off, last version of file cached on disk.
Raises:
In case of non-recoverable file (non-existent or inaccessible url + no cache on disk).
"""
if cache_dir is None:
# cache_dir = TRANSFORMERS_CACHE
cache_dir = "D:\\2022_NOC_AI_RASA_NEW\\bert-base-cased"
if isinstance(url_or_filename, Path):
url_or_filename = str(url_or_filename)
if isinstance(cache_dir, Path):
cache_dir = str(cache_dir)
if is_offline_mode() and not local_files_only:
logger.info("Offline mode: forcing local_files_only=True")
local_files_only = True
if is_remote_url(url_or_filename):
# URL, so get it from the cache (downloading if necessary)
output_path = get_from_cache(
url_or_filename,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
user_agent=user_agent,
use_auth_token=use_auth_token,
local_files_only=local_files_only,
)
elif os.path.exists(url_or_filename):
# File, and it exists.
output_path = url_or_filename
elif urlparse(url_or_filename).scheme == "":
# File, but it doesn't exist.
raise EnvironmentError(f"file {
url_or_filename} not found")
else:
# Something unknown
raise ValueError(f"unable to parse {
url_or_filename} as a URL or as a local path")
if extract_compressed_file:
if not is_zipfile(output_path) and not tarfile.is_tarfile(output_path):
return output_path
# Path where we extract compressed archives
# We avoid '.' in dir name and add "-extracted" at the end: "./model.zip" => "./model-zip-extracted/"
output_dir, output_file = os.path.split(output_path)
output_extract_dir_name = output_file.replace(".", "-") + "-extracted"
output_path_extracted = os.path.join(output_dir, output_extract_dir_name)
if os.path.isdir(output_path_extracted) and os.listdir(output_path_extracted) and not force_extract:
return output_path_extracted
# Prevent parallel extractions
lock_path = output_path + ".lock"
with FileLock(lock_path):
shutil.rmtree(output_path_extracted, ignore_errors=True)
os.makedirs(output_path_extracted)
if is_zipfile(output_path):
with ZipFile(output_path, "r") as zip_file:
zip_file.extractall(output_path_extracted)
zip_file.close()
elif tarfile.is_tarfile(output_path):
tar_file = tarfile.open(output_path)
tar_file.extractall(output_path_extracted)
tar_file.close()
else:
raise EnvironmentError(f"Archive format of {
output_path} could not be identified")
return output_path_extracted
return output_path
Rasa Transformer
recipe: default.v1
language: zh
pipeline:
# - name: JiebaTokenizer
- name: components.custom_jieba_tokenizer.Custom_JiebaTokenizer
- name: LanguageModelFeaturizer
model_name: "bert"
model_weights: "bert-base-chinese"
- name: RegexFeaturizer
- name: RegexEntityExtractor
- name: DIETClassifier
epochs: 100
tensorboard_log_directory: ./log
learning_rate: 0.001
- name: ResponseSelector
epochs: 1000
learning_rate: 0.001
- name: FallbackClassifier
threshold: 0.4
ambiguity_threshold: 0.1
- name: EntitySynonymMapper
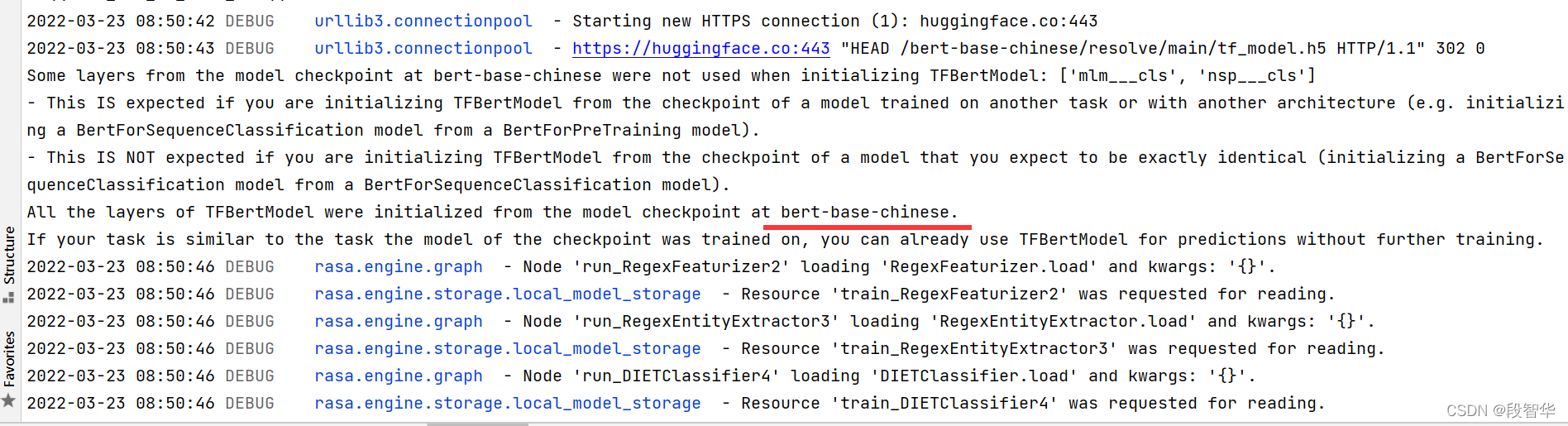
测试案例运行结果:

Rasa社区建议
Rasa实战
Rasa新书推荐:Rasa实战:构建开源对话机器人 介绍Rasa的两个核心组件——Rasa NLU和Rasa Core的工作流程;然后详细介绍通过使用Rasa生态系统从头开始构建、配置、训练和服务不同类型的对话机器人的整体过程

Rasa 3.x系列博客分享
-
Rasa课程、Rasa培训、Rasa面试系列 Rasa 3.X 项目实战之银行金融Financial Bot智能业务对话机器人
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Diet Architecture How it Works
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Diet Architecture Why it Works(Design Decisions)
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Diet Architecture Benchmarking
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Understanding Word Embeddings Just Letters
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Understanding Word Embeddings CBOW and Skip Gram
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Understanding Word Embeddings GloVe
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Understanding Word Embeddings Whatlies
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Transformers & Attention Self Attention
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之 Countvectors and Spelling Errors
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Subword Embeddings and Spelling
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之免费录播课Rasa 3.X 智能对话机器人案例开发硬核实战高手之路 (7大项目Expert版本)之 Debugging项目实战系列
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Implementation of Subword Embeddings
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之星空NLP对话机器人论文班:NLP领域10篇最高质量的对话机器人经典论文解密
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Measuring Bias in Word Embeddings
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Gavin大咖免费公益课程 Rasa Paper对话机器人经典论文解读班
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Using Projections to Remove Bias from Word Embeddings
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之 Debiasing via Projections Doesnot Always Work