记录spark unionAll的报错:Union can only be performed on tables with the compatible column types
Traceback (most recent call last):
File "/opt/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 63, in deco
File "/opt/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py", line 328, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o348.union.
: org.apache.spark.sql.AnalysisException: Union can only be performed on tables with the compatible column types. string <> array<string> at the 6th column of the second table;;
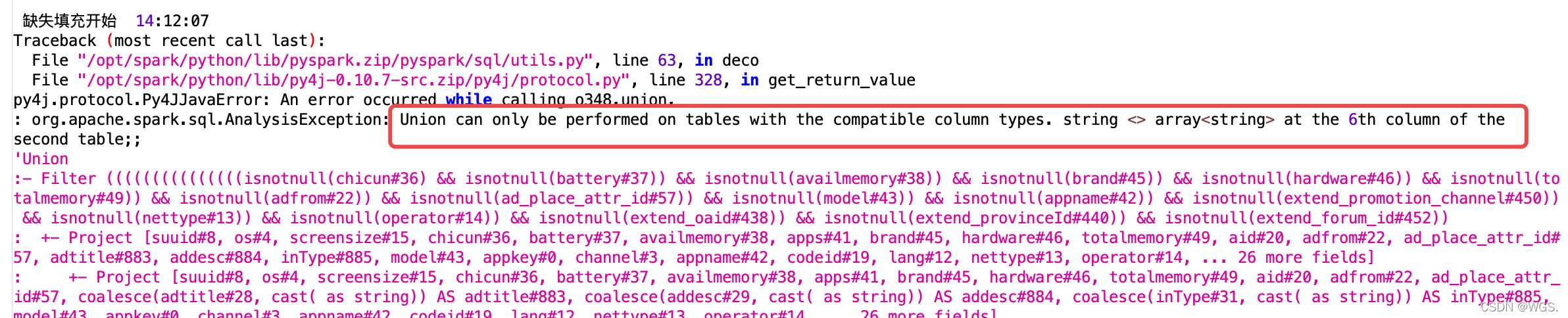
联合只能在具有兼容列类型的表上执行
说我索引为6的列,string类型和array类型不一致,就是union的两个表的列不一致
spark union注意:
-
union操作和集合的并集并不等价,它不会去除重复数据。
-
union函数并不是按照列名合并,而是按照位置合并。即DataFrame的列名可以不相同,但对应位置的列将合并在一起。
Spark 的默认行为union是标准 SQL 行为,因此是按位置匹配的。这意味着,两个 DataFrame 中的模式必须包含相同的字段,并且相同的字段具有相同的顺序。
出错代码位置:
df = dfnotna.unionAll(dfna)
定为问题:
print(dfnotna.columns)
print(dfna.columns)
['suuid', 'os', 'screensize', 'chicun', 'battery', 'availmemory', 'apps', 'brand', 'hardware', 'totalmemory', 'aid', 'adfrom', 'ad_place_attr_id', 'adtitle', 'addesc', 'inType', 'model', 'appkey', 'channel', 'appname', 'codeid', 'lang', 'nettype', 'operator', 'time', 'country', 'city', 'province', 'extend', 'actname', 'extend_suuid', 'extend_oaid', 'extend_aid', 'extend_provinceId', 'extend_adveruserid', 'extend_payment', 'extend_information', 'extend_w', 'extend_h', 'extend_cost', 'extend_personal_ads_type', 'position', 'extend_productId', 'extend_promotion_channel', 'extend_slotBinding', 'extend_forum_id', 'extend_forum_duration', 'extend_open_type', 'extend_app_back_run_time', 'newid']
['newid', 'suuid', 'os', 'screensize', 'chicun', 'battery', 'availmemory', 'apps', 'brand', 'hardware', 'totalmemory', 'aid', 'adfrom', 'ad_place_attr_id', 'adtitle', 'addesc', 'inType', 'model', 'appkey', 'channel', 'appname', 'codeid', 'lang', 'nettype', 'operator', 'time', 'country', 'city', 'province', 'extend', 'actname', 'extend_suuid', 'extend_oaid', 'extend_aid', 'extend_provinceId', 'extend_adveruserid', 'extend_payment', 'extend_information', 'extend_w', 'extend_h', 'extend_cost', 'extend_personal_ads_type', 'position', 'extend_productId', 'extend_promotion_channel', 'extend_slotBinding', 'extend_forum_id', 'extend_forum_duration', 'extend_open_type', 'extend_app_back_run_time']
解决方式:合并的列顺序要一致
df = dfnotna.select(*dfna.columns).unionAll(dfna)