什么是PCA?
变换数据集的坐标系,来消除数据间的相关性。
具体流程:
- 将数据变化为标准高斯分布。
- 计算协方差矩阵,及其特征值与特征向量。
- 选取前k大的特征值及其特征向量,将其定义为转换矩阵。
- 原始数据集乘以转换矩阵,得提取了主成分后的矩阵。
什么是LDA?
在空间内找一条直线,使得当数据点投影到这条直线上时,各个类的类内距离最小,而类间距离最大。
具体流程:
- 计算类内散度矩阵Sw及类间散度矩阵Sb
- 计算Sw-1 * Sb的特征值及其特征向量
- 选取其前k大的特征值及对应的特征向量,组成系数矩阵W
- 使用WT乘以原始数据x得到结果
相同
都属于特征抽取方法
都对数据进行降维
区别
PCA是无监督方法,LDA是监督方法
LDA最后的目的是进行分类,而PCA只提取主成分
PCA+LDA?
Why?
传统的LDA方法常常有两个问题:它们不能直接使用,因为类内散度矩阵总是奇异的;高维图片向量会带来过大的计算开销。
为了解决这个问题,PCA+LDA的方法被提出了。虽然实验表明这一方法工作得很好,但其理论证明却未能完成,且由于PCA的规则和LDA不同,我们不知道在对数据进行PCA的时候,是否有重要的辨别信息损失了。而这是本文所做的工作。
How?
假设有c类已知模式类,以及Sb、Sw和St=Sw+Sb。
经典Fisher准则函数通常定义为:

我们要找的就是符合条件的St。
由于数据的维度往往非常高,且St是奇异的,所以我们可以考虑从低维的空间来得到St。
其证明过程如下:

于是我们得出结论:最佳辨别向量,即LDA中的W,可以从Φt中导出,且不损失Fisher准则的最佳分辨信息。
那么如何导出呢?我们知道Φt和Rm空间是同型的,因此有:
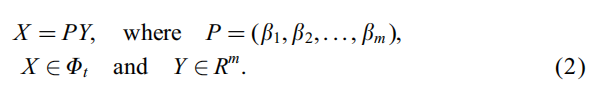
代入J(X)得:
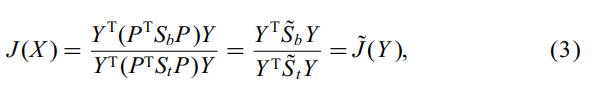
其中 S˜b = PT * Sb * P, S˜t = PT * St * P,可以证明它们是正定的,因此它们可以被视作类似Fisher的准则。

于是我们就得到了线性辨别变换:
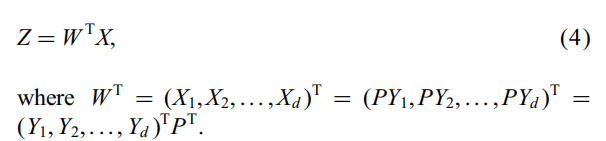
这是从Rm空间求出Φt空间的线性变换的映射,我们将其做分为两步:
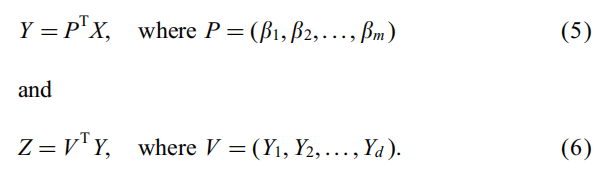
由于P是St的非零特征向量对应的正交特征向量,我们就可以将其认为是从Rn转换到Rm的PCA映射,而Rm上的
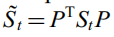 和
和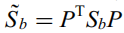
很好求得。因此,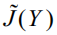
就是在PCA转换空间上的Fisher准则,Y1到Yn就是LDA求得的最佳分辨向量。
于是LDA方法在St奇异情况下的本质既是,先做一个PCA变化将图像空间转换到St的秩数维上,再对其进行LDA变换。
A Better algorithm
首先利用PCA将原始数据转换到St的秩数维数(m)上,设q为Sw中的正特征值数,其中零空间为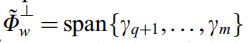
非零空间为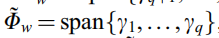 ,此时关于Fisher准则的所有有用的辨别信息已经得到了。
,此时关于Fisher准则的所有有用的辨别信息已经得到了。
由于对所有零空间中的向量Y有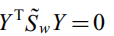 和
和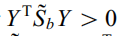 。所以Fisher准则为
。所以Fisher准则为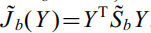 。
。
而正交空间中的Fisher准则则不变化,
具体流程:
- PCA得到主成分P1和P2如下。
- 取零空间坐标系
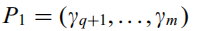 ,计算
,计算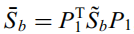 及其正交特征值Z1到Zl(l=类别数-1),得到零空间的最佳辨别向量为Yj=P1*Zj。
及其正交特征值Z1到Zl(l=类别数-1),得到零空间的最佳辨别向量为Yj=P1*Zj。 - 取非零空间坐标系
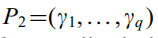 ,并计算
,并计算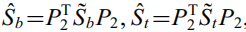 。得到其前d-l个特征值对应的特征向量Zl+1到Zd,得到非零空间的最佳辨别向量为Yj=P2*Zj。
。得到其前d-l个特征值对应的特征向量Zl+1到Zd,得到非零空间的最佳辨别向量为Yj=P2*Zj。 - 将前两步得到的Y合并得到特征提取器
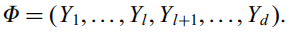 。只要将它的转置乘以原始数据,就得到了PCA+LDA变换后的数据。
。只要将它的转置乘以原始数据,就得到了PCA+LDA变换后的数据。
