2018
Non-local Neural Networks
code: https://paperswithcode.com/paper/non-local-neural-networks
摘要: 卷积操作和循环操作都是一次处理一个局部邻居的构建块。在本文中,我们将非局部操作作为一个用于捕获长期依赖关系的通用构造块族来提出。受计算机视觉中经典的非局部均值方法[4]的启发,我们的非局部操作计算一个位置的响应作为所有位置特征的加权和。这个构建块可以插入到许多计算机视觉架构中。在视频分类的任务中,即使没有任何花哨的功能,我们的非本地模型也可以在动力学和字谜数据集上竞争或超过当前的竞争获胜者。在静态图像识别中,我们的非局部模型改进了目标的检测/分割和姿态估计。

2019
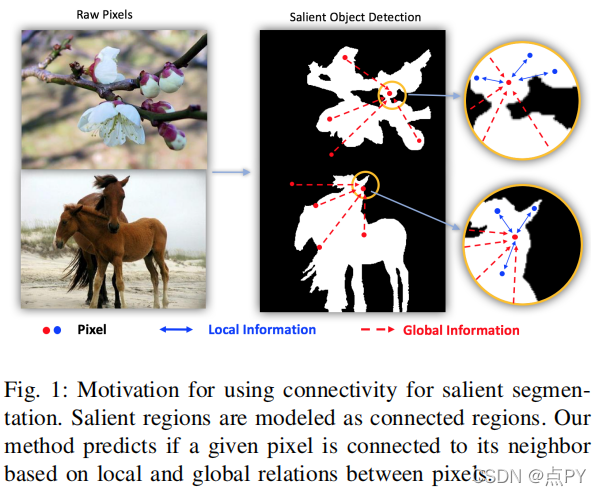
ConnNet: A Long-Range Relation-Aware Pixel-Connectivity Network for Salient Segmentation
摘要: 显著分割的目的,这是一项关键但具有挑战性的任务,也是许多高级计算机视觉应用的基础。它需要将语义感知的像素分组到显著的区域,并受益于利用全局多尺度上下文来实现良好的局部推理。以往的工作经常将其解决为两类分割问题,利用复杂的多步骤程序,包括细化网络和复杂的图形模型。我们认为,语义显著性分割可以通过重新定义为一个简单而直观的基于像素对的连接预测任务来有效地解决。根据显著对象可以通过相邻像素之间的语义感知连接来自然分组的直觉,我们提出了一个纯连接网络(ConnNet)。ConnNet通过利用嵌入在图像中的多级级级联上下文和长程像素关系来预测每个像素与其相邻像素的连通性概率。我们研究了在两个任务上我们的方法,即显著目标分割和显著实例分割,并说明通过将这些任务建模为连接,而不是各种网络架构的二值分割任务,可以获得一致的改进。我们实现了最先进的性能,优于或可与现有的方法相媲美,同时由于我们不那么复杂的方法而减少了推理时间。
论文的贡献:
- 我们说明了连接建模可以是一个很好的替代传统分割任务的显著分割。将我们的方法与为分割任务训练的相同架构进行比较,我们发现ConnNet在广泛的基准数据集上优于分割网络。
- 我们开发了一种显著对象分割的方法,该方法在几个数据集上优于以前的最先进的方法,但也由于其简单性,大大减少了推理时间。我们还将此思想扩展到实例级显著性分割的任务中。
- 我们研究了不同的像素连通性建模方法对整体性能的影响。
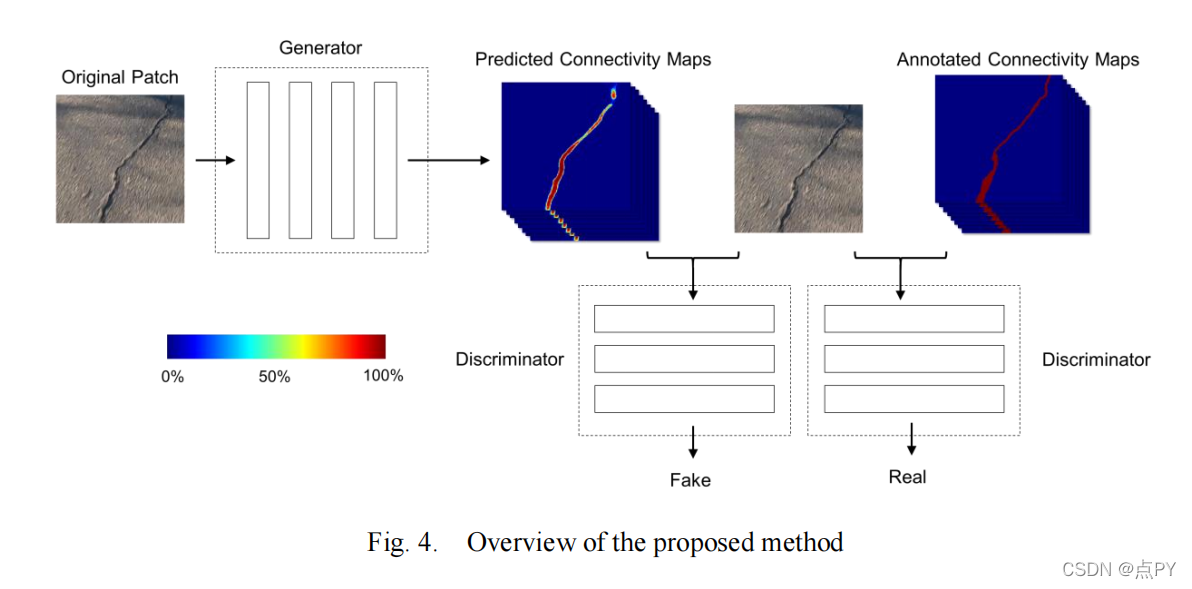
A Cost Effective Solution for Road Crack Inspection using Cameras and Deep Neural Networks
摘要: 路面裂缝自动检测是开发智能交通基础设施系统的一个重要研究领域。本文介绍了一种通过在移动车辆的后部安装商用级运动摄像机GoPro而实现的道路裂缝检测的经济有效的解决方案。同时,还提出了一种将条件瓦瑟斯坦生成对抗网络和连接图相结合的道路裂缝检测方法。该方法采用121层反褶积层的多层特征融合神经网络作为生成器,采用5层全卷积网络作为鉴别器。为了克服与反褶积层相关的分散输出问题,引入连通性图来表示提出的连接中的裂纹信息。所提出的方法在一个公开的数据集和我们收集的数据上进行了测试。结果表明,与现有的其他方法相比,该方法在精度、召回率和F1评分等方面都取得了最先进的性能。
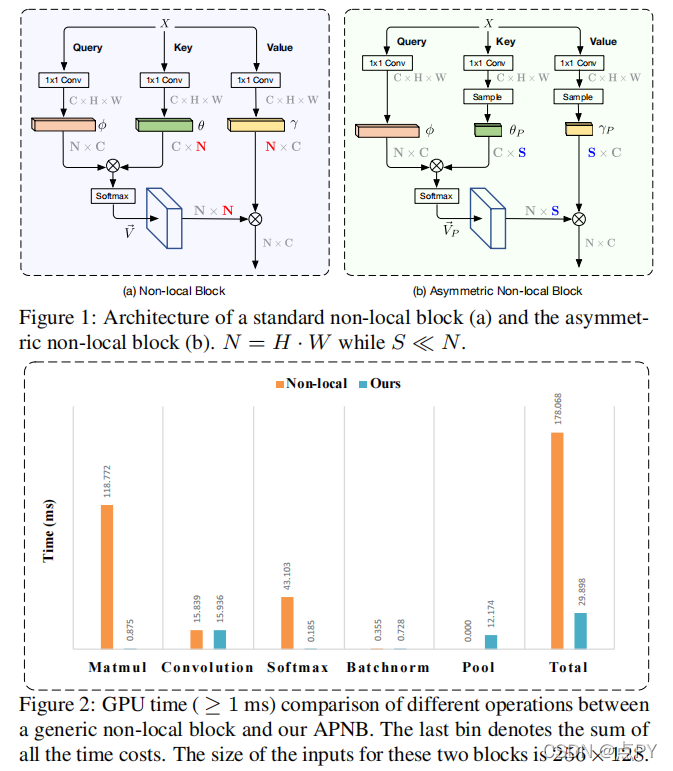
Asymmetric Non-local Neural Networks for Semantic Segmentation
code: https://paperswithcode.com/paper/asymmetric-non-local-neural-networks-for
摘要: 非局部模块作为一种特别有用的语义分割技术,同时因其禁止的计算和GPU内存占用而受到批评。在本文中,我们提出了非对称非局部神经网络的语义分割,它有两个突出的组成部分:非对称金字塔非局部块(APNB)和非对称融合非局部块(AFNB)。APNB利用金字塔采样模块,在不牺牲性能的情况下大大减少计算和内存消耗。AFNB源自APNB,在充分考虑长期依赖关系的情况下,融合了不同层次的特性,从而显著提高了性能。在语义分割基准上的大量实验证明了我们的工作的有效性和效率。特别是,我们报告了81.3mIoU在城市景观测试集上的最新性能。对于256×128输入,APNB比GPU上的非本地块快6倍,而比运行内存占用的GPU快28倍。
2020
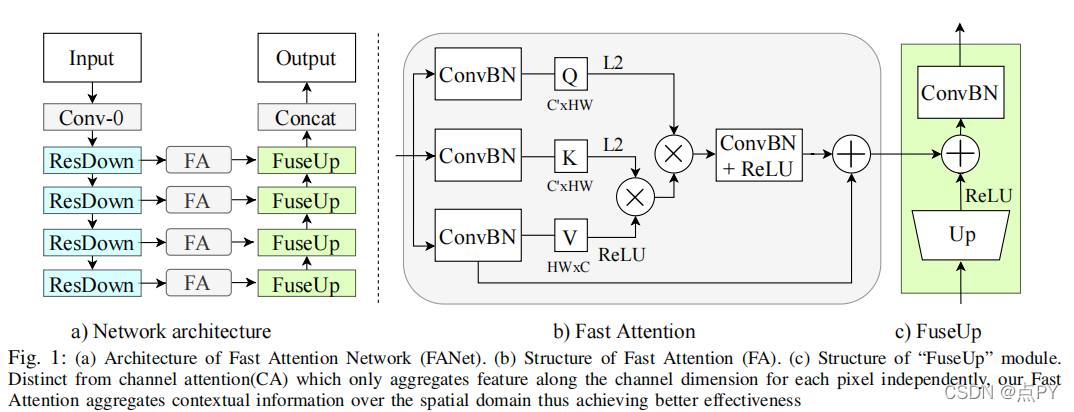
Real-time Semantic Segmentation with Fast Attention
code: https://github.com/feinanshan/FANet
摘要: 在基于CNN的深度语义分割模型中,高精度依赖于丰富的空间上下文(大的接受域)和精细的空间细节(高分辨率),这两者都需要产生很高的计算成本。在本文中,我们提出了一种新的架构,解决了这两个挑战,并实现了最先进的高分辨率图像和视频语义分割性能。所提出的架构依赖于我们的快速空间注意,这是对流行的自我注意机制的一种简单而有效的修改,通过改变操作的顺序,以一小部分计算成本捕获相同的丰富空间环境。此外,为了有效地处理高分辨率的输入,我们对网络的中间特征阶段应用了额外的空间缩减,由于使用了快速注意模块来融合特征,其精度损失最小。我们通过一系列的实验验证了我们的方法,结果表明,与现有的实时语义分割方法相比,在多个数据集上显示出优越的性能、更好的准确性和速度。在城市景观上,我们的网络在一个泰坦XGPU上以72FPS达到74.4% mIoU,在58FPS达到75.5%mIoU,其∼比现有的∼快50%,同时保持了相同的精度。
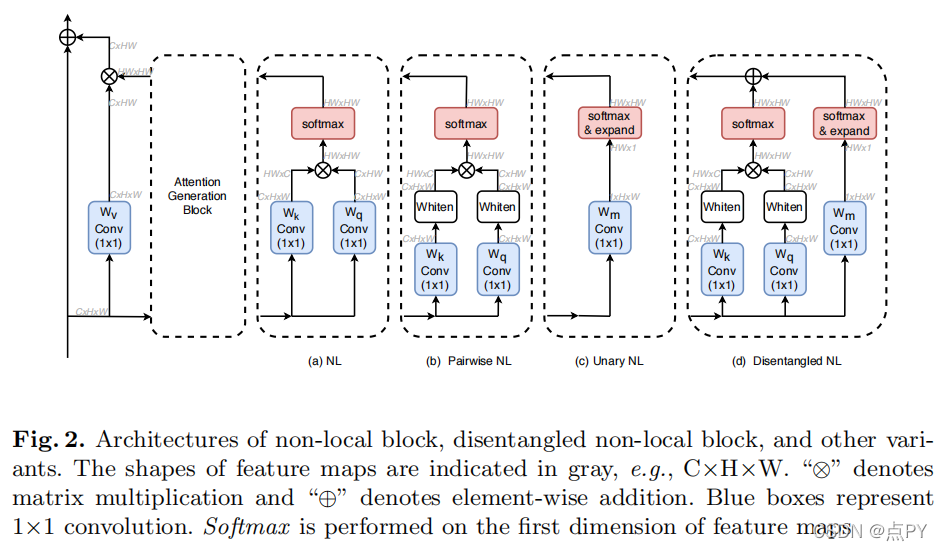
Disentangled Non-Local Neural Networks
code: https://github.com/yinmh17/DNL-Semantic-Segmentation
摘要: 非局部块是增强规则卷积神经网络上下文建模能力的常用模块。本文首先对非局部块进行了深入研究,发现它的注意力计算可以分为两项,一个是表示两个像素之间的关系,另一个是表示每个像素显著性的一元项。我们还观察到,单独训练的两个术语倾向于模拟不同的视觉线索,例如,白色的两两术语学习区域内关系,而一元术语学习显著的边界。然而,这两个项在非局部块中紧密耦合,这阻碍了每个项的学习。基于这些发现,我们提出了解纠缠的非局部块,其中这两个项被解耦,以促进对这两个项的学习。我们演示了解耦设计在各种任务上的有效性,如城市景观上的语义分割、ADE20K和帕斯卡上下文、COCO上的目标检测和动力学上的动作识别。该代码将被公开使用。
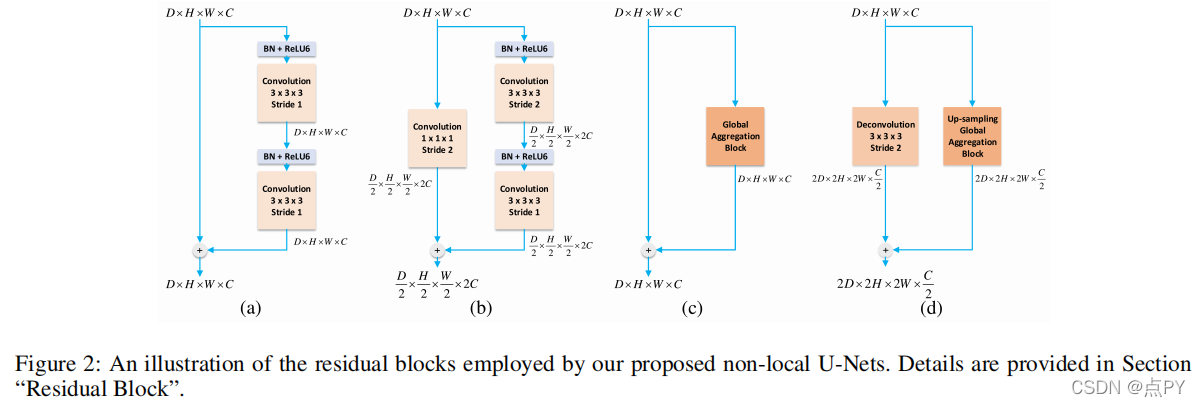
Non-local U-Nets for Biomedical Image Segmentation
code: https://paperswithcode.com/paper/global-deep-learning-methods-for
摘要: 深度学习在各种生物医学图像分割任务中显示出了其巨大的前景。现有的模型通常基于U-Net,并依赖于具有堆叠局部操作符的编码器-解码器体系结构来逐步聚合远程信息。然而,只使用本地操作符就限制了效率和有效性。在这项工作中,我们提出了非局部u-网,它配备了灵活的全局聚合块,用于生物医学图像分割。这些块可以作为大小保留过程插入到U-Net中,以及下采样层和上采样层。我们在三维多模态等强婴儿大脑Mr图像分割任务上进行了彻底的实验,以评估非局部u型网络。结果表明,该模型具有较少的参数和计算速度的最佳性能。
2021
Vectorization of Historical Maps Using Deep Edge Filtering and Closed Shape Extraction
code: https://github.com/soduco/ICDAR-2021-Vectorization
摘要: 几个世纪以来,地图一直是一种独特的知识来源。这些历史文献为分析景观在重要时间框架上的复杂空间变化提供了宝贵的信息。对于包含多个交叉研究领域(社会科学、经济等)的城市地区尤其如此。地图源的大量和显著的多样性需要自动图像处理技术,以提取矢量形状下的相关对象。地图的复杂性(文本、噪声、数字化工件等)几十年来阻碍了提出一种通用和高效的光栅到矢量方法的能力。我们提出了一个可学习的、可重复的和可重用的解决方案,用于将栅格映射自动转换为向量对象(积木、街道、河流)。它是建立在数学形态学和卷积神经网络的互补强度之上,通过有效的边缘滤波。此外,我们对ConnNet进行了修改,并结合深度边缘滤波体系结构,利用像素连接信息,构建了一个不需要任何后处理技术的端到端系统。在本文中,我们关注在多个数据集上的各种架构的综合基准,以及一个新的矢量化步骤。我们在一个使用COCO泛光度量的新公共数据集上的实验结果显示出非常令人鼓舞的结果,通过对我们的方法的成功和失败案例的定性分析得到证实。
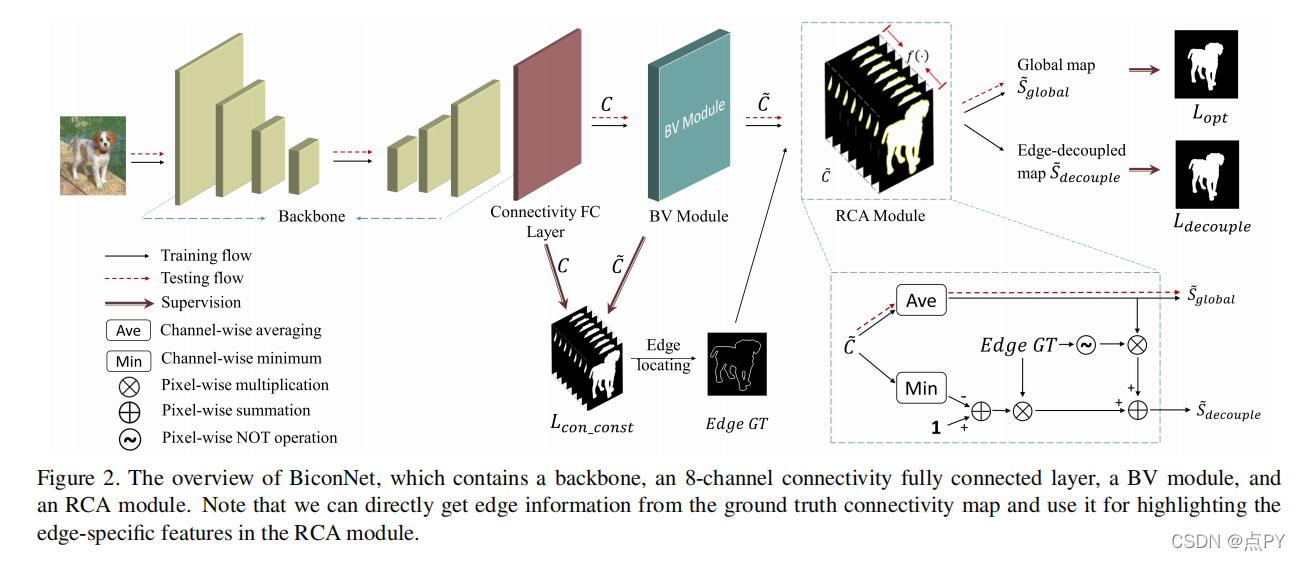
BiconNet: An Edge-preserved Connectivity-based Approach for Salient Object Detection
code: https://github.com/Zyun-Y/BiconNets
摘要: 传统的基于深度学习的方法将显著目标检测(SOD)视为一种像素级显著性建模任务。目前SOD模型的一个局限性是对像素间信息的利用不足,通常导致近边缘区域的分割不完善,空间相干性较低。正如我们所演示的,使用显著性掩码作为唯一的标签是次优的。为了解决这一局限性,我们提出了一种基于连通性的方法,称为双边连通性网络(BiconNet),该方法使用连通性掩码和显著性掩模作为标签,以有效地对像素间关系和对象显著性进行建模。此外,我们提出了一种双边投票模块来增强输出的连通性图,以及一种新的边缘特征增强方法,有效地利用了边缘特定的特征。通过对5个基准数据集上的全面实验,我们证明了我们提出的方法可以插入任何现有的最先进的基于显著的SOD框架,以在可忽略参数增加的情况下提高其性能。

论文的贡献:
- 我们提出了一种基于连通性的SOD框架,称为BiconNet,以明确地建模像素连通性,增强边缘建模,并保持显著区域的空间相干性。BiconNet可以很容易地插入任何现有的SOD模型,参数增加可忽略。
- 我们提出了一种高效的、基于连接性的边缘特征提取方法,它可以直接强调网络输出中的边缘特定信息。我们还引入了一个新的损失函数,Bicon损失,以进一步提高边缘特征的利用,并保持输出的空间一致性。
- 我们用七个最先进的SOD模型的骨干来构建biconnet。通过将这些双网络网络与相应的基线进行比较,我们表明,我们的模型在使用不同评估指标的五个广泛使用的基准测试上优于后一个模型。
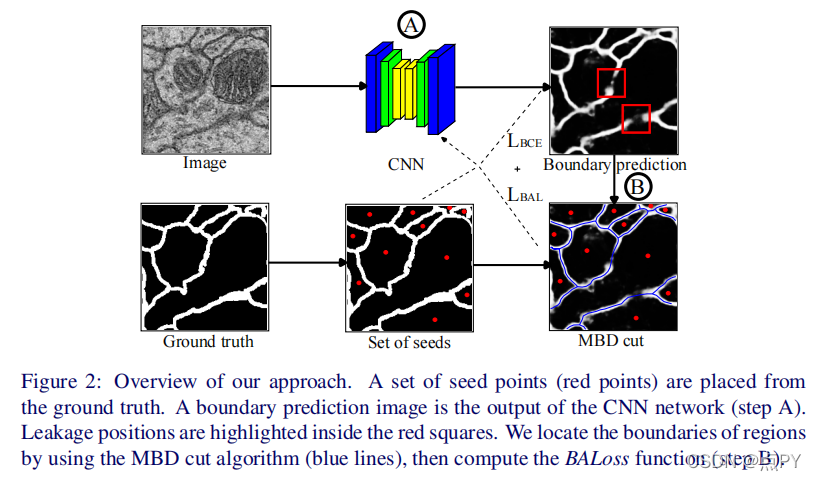
Introducing the Boundary-Aware loss for deep image segmentation(BMVC)
code: https://github.com/onvungocminh/MBD_BAL
摘要: 大多数当代的监督图像分割方法并不保留给定输入的初始拓扑结构(比如轮廓的接近程度)。当比较二进制预测和地面真实值时,人们通常可以注意到边缘点已经被插入或移除。当需要对多个互联对象的精确定位时,这可能是至关重要的。本文利用一种基于最小势垒距离(MBD)的切割算法,提出了一种新的损失函数,即边界感知损失(BALoss)。它能够定位我们所说的泄漏像素,并编码来自给定的地面真相的边界信息。由于这种适应的损失,我们能够在学习过程中显著地改进预测边界的质量。此外,我们的损失函数是可微的,可以应用于任何类型的图像处理的神经网络。我们将这个损失函数应用于电子显微镜数据集上的标准U-Net和DCU-Net。众所周知,它们具有高噪声水平,覆盖图像空间的近距离甚至连接的物体具有挑战性。我们的分割性能,在信息变异(Voi)和自适应等级指数(ARI)方面,非常有前途,导致∼的Voi得分高15%,∼的得分比最先进的高5%。