写在前面
这篇文章主要让大家明白
多线程爬虫,因为go语言实现并发是很容易的。
这次的服务端,是我们之前搭建的电子商城平台,所以我们不担心ip被封之类的问题。
而实际生产环境中,其实我们都是用python爬虫的。python实现多线程也很简单。
这次我们可以试试新玩法,试试go语言的并发爬虫。
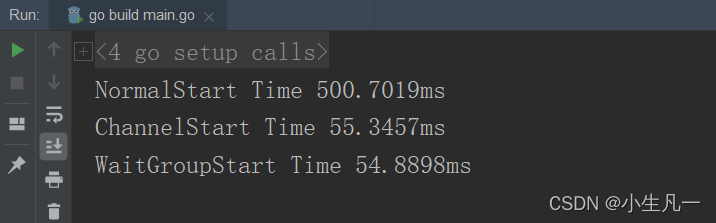
主要是爬取第一页的商品,爬取十次,比较单线程和多线程的时间。
1. 单线程爬虫
- 定义一个用户
var Client http.Client
- 主函数
func main() {
url := "http://localhost:3000/api/v1/products"
start := time.Now()
for i := 0; i < 10; i++ {
Spider(url, i)
}
elapsed := time.Since(start)
fmt.Printf("Time %s", elapsed)
}
- 爬取函数
func Spider(url string, i int) {
reqSpider, err := http.NewRequest("GET", url, nil)
if err != nil {
log.Fatal(err)
}
reqSpider.Header.Set("content-length", "0")
reqSpider.Header.Set("accept", "*/*")
reqSpider.Header.Set("x-requested-with", "XMLHttpRequest")
respSpider, err := Client.Do(reqSpider)
if err != nil {
log.Fatal(err)
}
bodyText, _ := ioutil.ReadAll(respSpider.Body)
var result Result
_ = json.Unmarshal(bodyText, &result)
fmt.Println(i,result.Data)
}
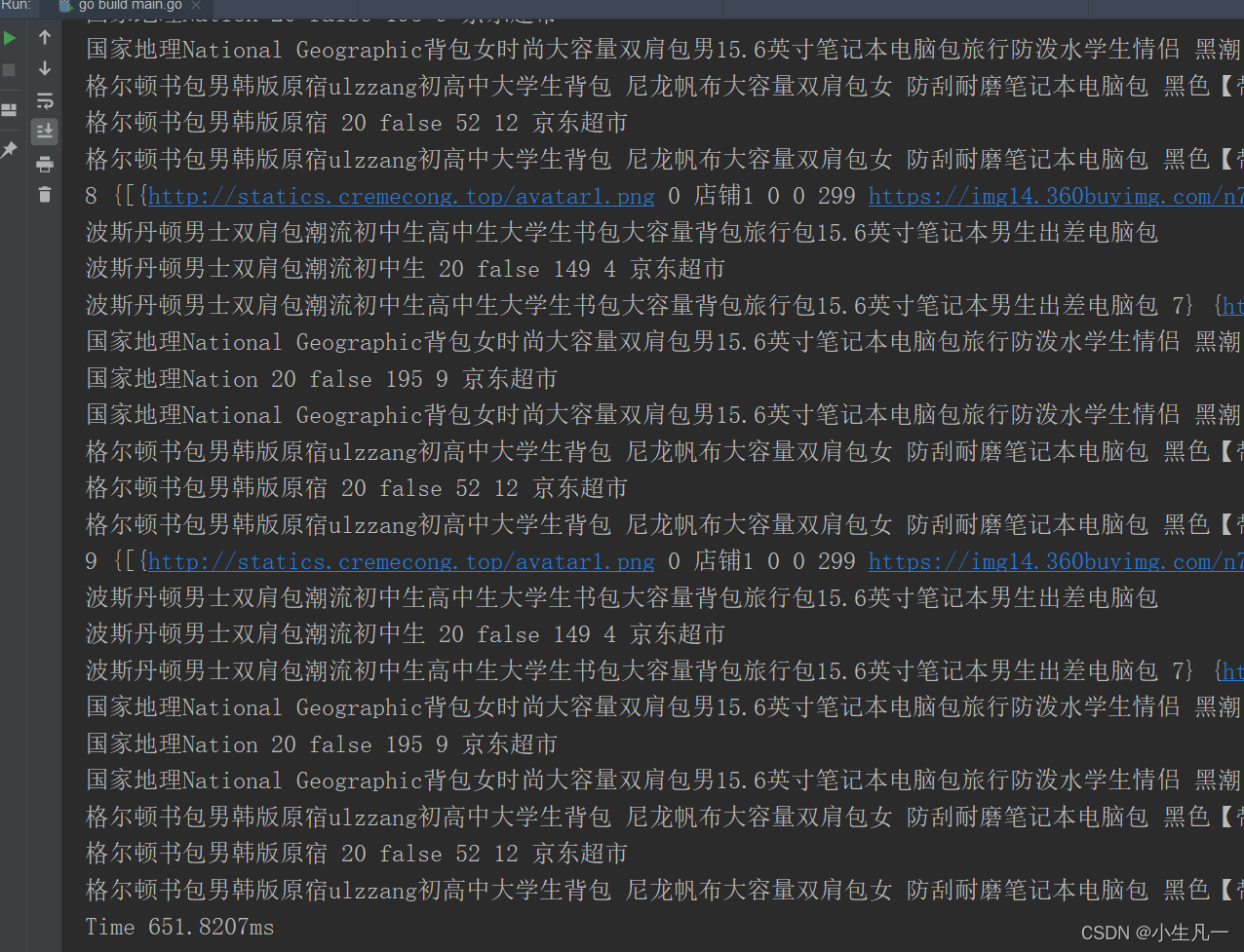
- 运行时间为:
651.8207ms
2. 多线程爬虫
2.1 channel
- main函数
我们构造一个无缓冲的通道,来阻塞主进程,等待子进程的执行。
func main() {
url := "http://localhost:3000/api/v1/products"
ch := make(chan bool)
start := time.Now()
for i := 0; i < 10; i++ {
go Spider(url, ch, i)
}
for i := 0; i < 10; i++ {
<-ch
}
elapsed := time.Since(start)
fmt.Printf("Time %s", elapsed)
}
- 最后记得在爬虫的结束的时候,把值写入到通道中,不然会一直阻塞主进程

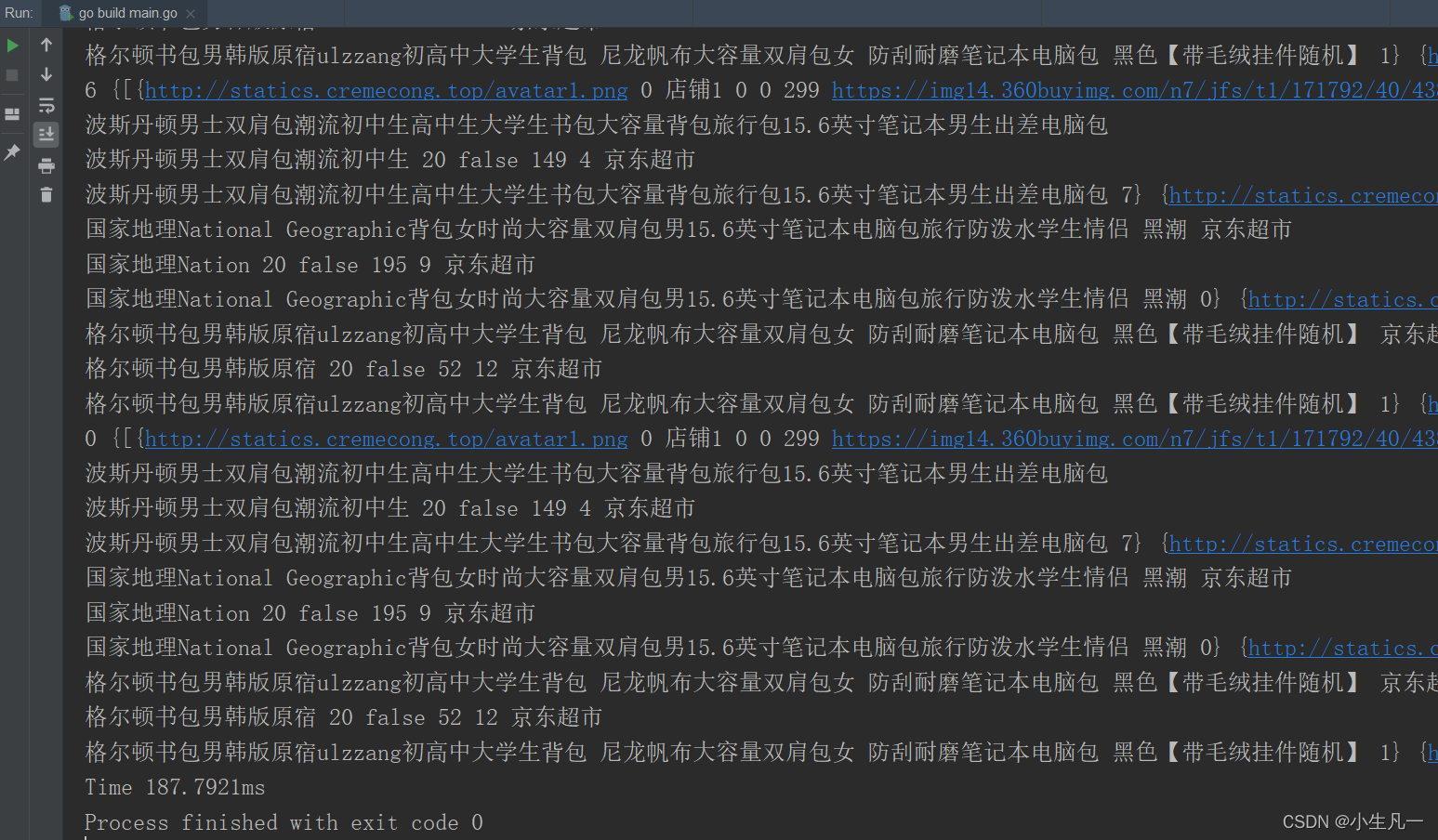
- 运行时间:
187.7921ms比之前快了非常多。
2.2 sync.WaitGroup
- 定义一个进程组并加10个进程
var wg sync.WaitGroup
wg.Add(10)
- 开辟十个goruntime
for i := 0; i < 10; i++ {
go func(i int) {
defer wg.Done()
SpiderWaitGroup(url,i)
}(i)
}
- 阻塞主进程
wg.Wait()
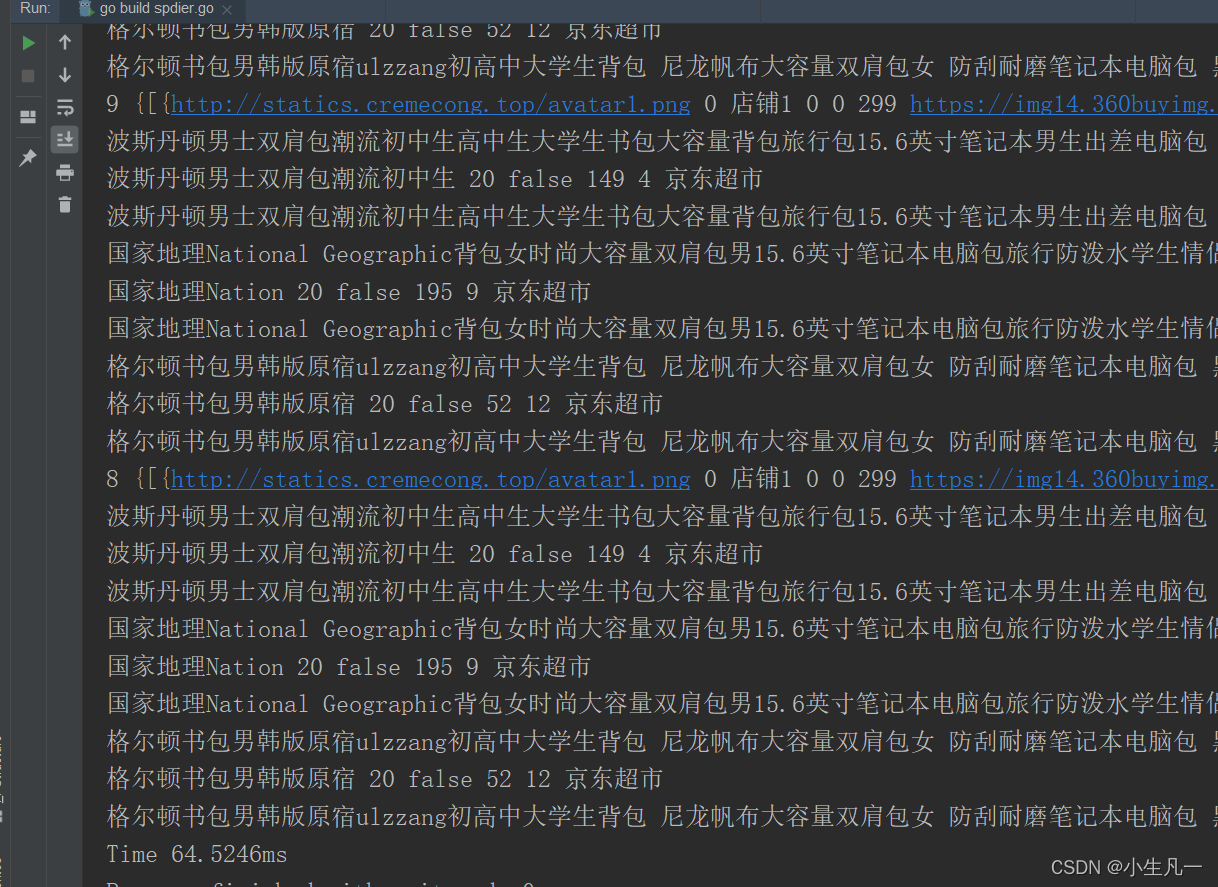
- 结果:
64.5246ms
3. 源码地址
GitHub地址:https://github.com/CocaineCong/Go-Spider-Demo
NormalStart(url) // 单线程爬虫
ChannelStart(url) // Channel多线程爬虫
WaitGroupStart(url) // Wait 多线程爬虫
- 其实多线程的两种都差不多的,只是有时候会因为机器的原因而导致一些误差。