SE3-Nets Learning Rigid Body Motion using Deep Neural Networks(1)
- 输入:三维点;系统输入(如推力);
- 输出:三维点
该论文只针对三维点云输入(RGBD等),来求解每帧中目标物体的刚体变换关系(SE(3), pose)。
在这些深度学习框架的位姿估计问题中,旋转都使用旋转向量(3维度)的方式。
以及需要分割的个数(?提前知道个数,最大个数吧?),得到各个分割块的pose(随后可以根据pose将点云转换过去)
SE3-NETS learn to segment effected object parts and predict their motion resulting from the applied force.
作者认为之前的物理模型(非深度模型)虽好,但依赖的是精准的观测量和基于此的精准的预测,而人是靠直觉、模糊的预测来行动的。而之前的基于物理
1.流程和网络架构
如图:
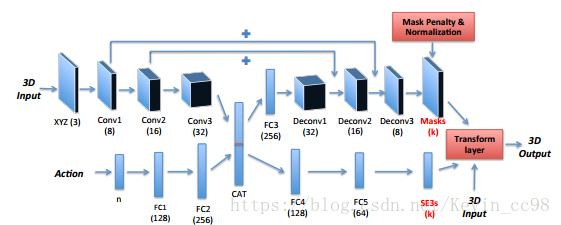
作者的网络分为两个部分:
1.Encoder部分输入点云,同时用一个全连接网络来接收控制输入,结果
2.在Encoder之后,Decoder部分做了两件事:
- 将区域按照目标分类,识别出那些一同运动的像素部分(称之为一个目标),文中用一个mask(仅仅包含目标部分)来区分各个不同区域的目标。
值得注意的是,目标的个数k是网络训练前提前设置好的。所以这可以转为分类问题,对每一个输入像素分为k个类别之一。这个过程和普通的深度预测网络十分类似:skip,降采样+升采样。由于类别之间离散不可导(?),作者分别计算每一个点在k个类别的分布概率(总和为1)。
- 接下来对每一目标物体的SE3进行预测。
最后通过转移层将所有信息汇总起来:对k个可能的pose进行得到最终变换之后的三维点位姿进行加权求和得到最终位姿,从而得到最终每个点的刚体变换。这里的权重是之前提到的概率
2.结果
作者在仿真数据和真实数据上测试。训练目标是使得点云y通过训练后的数据集得到转换后的点云集y‘和真值一样。
训练时,假设输入和输出的数据关联对应关系是知道的(可以通过位姿等得到前后三维点的对应关系)
每帧test时间大概达到0.15s。
最后作者发现该系统对目标个数很敏感,对深度噪音和数据关联的噪音不是那么敏感(加入训练时有错误的数据关联关系)
评价:本文没有解决数据关联问题,还需要借助于ICP等,输入限于雷达或RGBD数据。