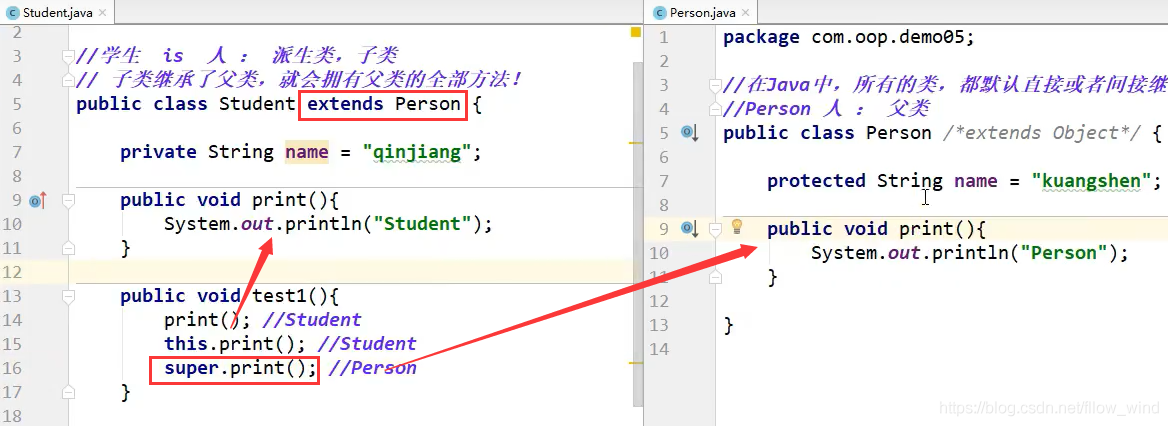
多态
-
即同一方法可以根据发送对象的不同而采用不同的行为方式
-
一个对象的实际类型是确定的,但可以指向对象的引用可以有很多
-
多态存在条件
- 有继承关系
- 子类重写父类方法
- 父类引用指向子类对象
注意点:
- 多态是方法的多态,没有属性的多态
- 父类和子类,有联系 类型转换异常: ClassCastException
- 存在条件:继承关系,方法需要重写,父类引用指向子类对象!
instanceof和类型转换
- instanceof 引用类型比较,判断一个对象是什么类型
Object object = new Student(); System.out.println(object instanceof Student); System.out.println(object instanceof Person); System.out.println(object instanceof Object); System.out.println(object instanceof Teacher); System.out.println(object instanceof String); System.out.println("======================"); Person person = new Student(); System.out.println(person instanceof Student); System.out.println(person instanceof Person); System.out.println(person instanceof Object); System.out.println(person instanceof Teacher);// System.out.println(person instanceof String); System.out.println("======================="); Student student = new Student(); System.out.println(student instanceof Student); System.out.println(student instanceof Person); System.out.println(student instanceof Object);// System.out.println(student instanceof Teacher);// System.out.println(student instanceof String);
复制代码- 类型转换
- 父类引用指向子类的对象
- 把子类转换为父类,向上转型,会丢失自己原来的一些方法
- 把父类转换为子类,向下转型,强制转换,才调用子类方法
- 方便方法的调用(转型),减少重复的代码,简洁
多态性:
-
理解多态性:可以理解为一种事物的多种形态
-
何为多态性:
-
对象的多态性:父类的引用指向子类的对象(或者子类的对象赋给父类的引用)
-
-
多态的使用:
-
有了多态的使用以后,我们在编译器只能调用父类声明的方法,但是在运行期,我们实际执行的是子类的重写父类的方法
-
-
分析 s. move();
-
java程序分为编译阶段 和 运行阶段
-
首先来分析编译阶段:
- 对于编译器来说,编译器只知道s的类型是Animal,所以编译器在检查语法的时候,回去Animal.class字节码文件中找move()方法,找到的话,就进行绑定move(),此时编译通过,静态绑定成功。(编译阶段属于静态绑定阶段)
2.继续分析运行阶段:
-
-
-
- 运行阶段的时候 ,实际上在堆内存创建的 java对象 是Cat对象,所以在move()的时候, 实际上真正参与move()对象的是一只猫 ,所以运行阶段会动态执行Cat对象的move()方法 .(运行阶段属于动态绑定)
- 但是运行的时候和底层堆存中的实际对象有关 ,真正执行的时候会调用真实对象的相关方法 .
-
总结:编译,看左边。执行(运行),看右边。
-
对象的多态性:只适用于方法,不适用于属性。
-
多态性的使用前提:①类的继承关系 ② 方法的重写
-
instanceof 关键字的使用:
-
- a instanceof A :判断对象a 是否为A类的实例,如果是,则返回true,如果不是,则返回false
- 使用情景:为了避免在向下转型时出现ClassCastException的异常,所以我们在向下转型之前,我们进行instanceof的判断,一旦返回true,就立即向下转型,如果返回false,就停止向下转型。
- 如果a instanceof A 返回true, 则 a instanaceof B也会返回true。
练习注意:
- 若子类重写了父类的方法,则就意味着子类定义的方法彻底覆盖了父类里同名同参数的方法,系统将不可能把父类里面的方法转移到子类中
- 对于实例变量则不存在这样的现象,即使子类里定义了与父类完全相同的实例变量,这个实例变量依然不可能覆盖父类中定义的实例变量:即编译看左边,运行看右边。
有了对象的多态性以后,内存实际上加载了子类特有的属性和方法。但是由于变量声明为父亲类型
导致了编译时,只能调用父类中声明的属性和方法,。子类特有的属性和方法就不能调用。
如何才能调用子类中的属性和方法?*
向下转型:使用强制类型转化,缺点:会有精度的损失
super限定
如果需要在子类方法中调用父类被覆盖的实例方法. 则可以使用 super 限定来调用父类被覆盖的实例方法. 为上面的 Ostrich 类添加一个方法, 在这个方法中调用 Bird 类中被覆盖的 fly 方法.
public void callOverrideMethod()
{
//在子类方法中通过 super 显式调用父类被覆盖的实例方法
super.fly();
}
复制代码super 是 Java提供的一个关键字, super 用于限定该对象调用它从父类继承得到的实例变量或方法. 正如 this 不能出现在 static 修饰的方法中一样, super 也不能出现在 static 修饰的方法中. static 修饰的方法是属于类的. 该方法的调用者可能是一个类, 而不是对象, 因而 super 限定也就失去了意义.
如果在构造器中使用 super 则 super 用于限定该构造器初始化的是该对象从父类继承得到的实例变量, 而不是该类自己定义的实例变量.
如果子类定义了和父类同名的实例变量. 则会发生子类实例变量隐藏父类实例变量的情形. 在正常情况下, 子类里定义的方法直接访问该实例变量默认会访问到子类中定义的实例变量.
无法访问到父类中被隐藏的实例变量. 在子类定义的实例方法中可以通过 super 来访问父类中被隐藏的实例变量.
如下代码所示:
class BaseClass
{
public int a = 5;
}
public class SubClass extends BaseClass
{
public int a = 7;
public void accessOwner()
{
System.out.println(a);
}
public void accessBase()
{
//通过使用 super 来限定访问从父类继承得到的 a 的实例变量
System.out.println(super.a);
}
public static void main(String[] args)
{
SubClass sc = new SubClass();
sc.accessOwner(); //输出 7
sc.accessBase(); //输出 5
}
}
复制代码上面程序的 BaseClass 和 SubClass 中都定义了名为 a 的实例变量. 则 SubClass 的 a 实例变量将会隐藏BaseClass 的 a 实例变量. 当系统创建了 SubClass 对象时, 实际上会为 SubClass 对象分配两块内存.
如果子类里没有包含和父类同名的成员变量. 那么在子类实例方法中访问该成员变量时, 则无需显式使用 super 或 父类名作为调用者. 如果在某个方法中访问名为 a 的成员变量, 但没有显式指定调用者, 则系统查找 a 的顺序为:
- 查找该方法是否有名为a的局部变量。
- 查找当前;类是否包含名为a的成员变量。
- 查找a的直接父类是否含有名为a的成员变量, 依次上溯 a 的所有父类. 直到 java.lang.Object 类.
- 如果最终不能找到名为 a 的成员变量, 则系统出现编译错误.
如果被覆盖的是类变量, 在子类的方法中则可以通过父类名作为调用者来访问被覆盖的类变量.
涨姿势: 当程序创建一个子类对象时. 系统不仅会为该类中定义的实例变量分配内存. 也会为它从父类继承得到的所有实例变量分配内存. 即使子类定义了与父类中同名的实例变量. 也就是说, 当系统创建一个 java 对象时. 如果该 java 类有两个父类(一个直接父类 A / 一个间接父类 B) 假设 A 类中定义了 2 个实例变量, B 类中定义了 3 个实例变量. 当前类中定义了 2 个实例变量, 那么这个 java 对象会保存 2 + 3 + 2 个实例变量.
因为子类中定义与父类中同名的实例变量并不会完全覆盖父类中定义的实例变量, 它只是简单的隐藏了父类中实例变量, 所以会出现如下特殊情况:
class Parent
{
public String tag = "孙悟空";
}
class Derived extends Parent
{
//定义一个私有的 tag 实例变量来隐藏父类的 tag 实例变量
private String tag = "猪八戒";
}
public class HideTest
{
public static void main(String[] args)
{
Derived d = new Derived();
//程序不可访问 d 的私有变量 tag , 所以下面语句将引起编译错误
//System.out.println(d.tag);
//将 d 变量显式的向上转型为 Parent 后, 即可访问 tag 实例变量
//程序将输出 孙悟空
System.out.println(((Parent)d).tag);
}
}
复制代码上面程序父类 Parent 定义了一个 tag 实例变量. 其子类 Derived 定义了一个 private 的 tag 实例变量. 子类中定义的这个实例变量将会隐藏父类中定义的 tag 实例变量.
程序的入口 main() 方法中先创建了一个 Derived 对象. 这个 Derived 对象将会保存两个 tag 实例变量. 一个是在 Parent 中定义的 tag 实例变量. 一个是在 Derived 类中定义的 tag 实例变量. 此时程序中包括了一个 d 变量.
它引用一个 Derived 对象, 内存中的存储示意图如下:
接着, 程序将 Derived 对象赋给 d 变量. 接着, 程序试图通过 d 来访问 tag 实例变量, 程序将提示访问权限不允许. 接着, 将 d 变量强制向上转型为 Parent 类型. 再通过它来访问 tag 实例变量是允许的.
调用父类构造器
子类不会获得父类的构造器。
但子类构造器里可以调用父类构造器的初始化代码。
类似于前面介绍的一个构造器可以调用另一个重载构造器。
在一个构造器中调用另一个重载的构造器使用this来调用完成。
在子类构造器中调用父类构造器使用super调用来完成。
看下面程序定义了 Base 类 和 Sub 类, 其中 Sub 类是 Base 类的子类. 程序在 Sub 类的构造器中使用 super 来调用 Base 类的构造器初始化代码.
class Base
{
public double size;
public String name;
public Base(double size, String name)
{
this.size = size;
this.name = name;
}
}
public class Sub extends Base
{
public String color;
public Sub(double size, String name, String color)
{
//通过 super 调用来调用父类构造器的初始化过程
super(size, name);
this.color = color;
}
public static void main(String[] args)
{
Sub s = new Sub(5.6, "皮卡丘", "黄色");
//输出 Sub 对象的 三个实例变量
System.out.println(s.size + "--" + s.name + "--" + s.color);
}
}
复制代码从上面程序中不难看出, 使用 super 调用和使用 this 调用也很像. 区别在于 super 调用的是其父类的构造器, 而 this 调用的是同一个类中重载的构造器. 因此, 使用 super 调用父类构造器也必需出现在子类构造器执行体的第一行. 所以 this 调用 和 super 调用不会同时出现.
不管是否使用 super 调用来执行父类构造器的初始化代码. 子类构造器总会调用父类构造器一次.
子类构造器调用父类构造器分如下几种情况:
- 子类构造器执行体的第一行使用 super 显式调用父类构造器.系统将根据 super 调用里传入的实参列表调用父类对应的构造器.
- 子类构造器执行体的第一行代码使用 this 显式调用本类中重载的构造器,系统将根据 this 调用里传入的实参列表调用本类中的另一个构造器.执行本类中另一个构造器时即会调用父类构造器.
- 子类构造器执行体中既没有 super 调用, 也没有 this 调用, 系统将会在执行子类构造器之前, 隐式调用父类无参数的构造器.
不管上面哪种情况, 当调用子类构造器来初始化子类对象时. 父类构造器总会在子类构造器之前执行: 不仅如此, 执行父类构造器时, 系统会再次上溯执行其父类构造器……以此类推. 创建任何 Java对象, 最先执行的总是 java.lang.Object 类的构造器.
对于如下图所示的继承树.
如果创建 ClassB 的对象, 系统将先执行 java.lang.Object 类的构造器. 再执行 ClassA 类的构造器. 然后才执行 ClassB 类的构造器. 这个执行过程还是最基本的情况. 如果 ClassB 显式调用 ClassA 的构造器, 而该构造器又调用了 ClassA 类中重载的构造器, 则会看到 ClassA 两个构造器先后执行的情形.
下面程序定义了三个类, 它们之间有严格的继承关系. 通过这种继承关系来让你看看构造器之间的调用关系.
class Creature
{
public Creature()
{
System.out.println("Creature 无参数的构造器");
}
}
class Animal extends Creature
{
public Animal(String name)
{
System.out.println("Animal 带一个参数的构造器," + "该动物的 name 为:" + name);
}
public Animal(String name, int age)
{
//使用 this 调用同一个重载的构造器
this(name);
System.out.println("Animal 带两个参数的构造器," + "其 age 为:" + age);
}
}
public class Wolf extends Animal
{
public Wolf()
{
//显式调用父类有两个参数的构造器
super("大灰狼", 3);
System.out.println("Wolf 无参数的构造器");
}
public static void main(String[] args)
{
new Wolf();
}
}
复制代码上面程序的 main 方法只创建了一个 Wolf 对象. 但系统在底层完成了复杂的操作. 运行上面的程序, 看到如下运行结果:
Creature 无参数的构造器
Animal 带一个参数的构造器, 该动物的 name 为大灰狼
Animal 带两个参数的构造器, 其 age 为 3
Wolf 无参数的构造器
复制代码从上面的运行过程来看. 创建任何对象总是从该类所在继承树最顶层的类的构造器开始执行. 然后依次向下执行. 最后才执行本类的构造器. 如果某个父类通过 this 调用了 同类中重载的构造器. 就会依次执行此父类的多个构造器
super&this
super注意点:
-
super调用父类的构造方法,必须在构造方法的第一个
-
super必须只能出现在子类的方法或者构造方法中
-
super和this不能通知调用构造方法
-
我们可以在子类的方法或构造器中。通过使用“super.属性”或”super.方法“,显示的调用父类中的属性和方法,但是在通常情况下,通常省略“super"关键字。
-
特殊情况下,当子类或父类中定义了同名的属性时,我们想要在子类中调用父类声明的属性,则必须显示的使用“super.属性”的方式,表明调用的是父类中声明的属性
-
特殊情况,当子类重写了父类的方法以后,我们想要在子类中调用父类被重写的方法时,则必须显示的使用”super.方法“的方式,表明调用的是父类中的方法。
VS this:
-
代表的对象不同
-
this : 本身调用者这个对象
-
super :只能在继承条件下可以试用
-
-
构造方法
-
this() :本类的构造
-
super():父类的构造
-
我们可以在子类的构造器中显示的适用”super.(行参列表)“的方式,调用父类中声明的指定构造器
-
”super.(行参列表)“的使用,必须声明在子类构造器的首行!
-
我们在类的构造器中,针对”this.(行参列表)“或”super.(行参列表)“只能二选一。
-
在构造器的首行,没有显示的声明”this.(行参列表)“或”super.(行参列表)“,则默认的调用的是父类中的空参的构造器。
-
super 不是引用 ,super也不保存内存地址 ,super也不指向任何对象
-
super只是代表当前对象内部的那一块父类的特征.
-
-
super与this的区别 :super代表父类对象的引用,只能继承条件下使用,this调用自身的对象,没有继承关系也可以使用
super(); //隐藏代码,默认调用了父类的无参构造,要写只能写第一行 复制代码
小结:方法的重载和重写
- 从编译和运行的角度来讲:
-
- 重载,是允许多个同名的方法,而这些方法的参数不同,编译器根据方法不同的参数表,对同名方法的名称进行修饰。对于编译器而言,这些同名的方法就成了不同的方法。他们的调用地址在编译期就绑定了。Java的重载是可以包括父类和子类的,即子类可以重载父类同名不同参数的方法。
- 所以对于重载而言,在方法调用之前,就已经确定了所要调用的方法,这称为“早绑定”或”静态绑定“
- 而对于多态,只有等到方法调用的那一刻,编译器才会确定所调用的具体方法,这称为“晚绑定”或“动态绑定”
- “不要犯傻,只要确定他是不是晚绑定,那他就不是多态!”
拓展知识
JavaBean
-
所谓的JavaBean,就是指符合如下的Java类:
-
类是公共的
-
有一个无参的构造器
-
有属性,且有相应的set,get方法。
-
用户可以使用JavaBean将功能,处理,数据库访问和其他任何可以用Java代码创造的对象进行打包,并且其他的开发者可以通过内部的JSP页面,Servlet其他JavaBean程序或者应用来使用这些对象。用户可以认为JavaBean提供了一种随时随地的复制和粘贴的功能,而不用关心任何变化。
面向对象阶段其他细节问题
什么时候变量声明为实例的,什么时候变量声明为静态的?
如果这个类型的所有对象的属性值都是一样的,不建议定义为实例变量,浪费内存空间. 建议定义为类级别特征 ,定义为静态变量 ,在方法区中只保留一份,节省内存开销.
一个对象一份的是实例变量
所有对象一份的是静态变量
8、Java进阶
final使用
final变量
final变量有成员变量或者是本地变量(方法内的局部变量),在类成员中final经常和static一起使用,作为类常量使用。其中类常量必须在声明时初始化,final成员常量可以在构造函数初始化。
public class Main {
public static final int i; //报错,必须初始化 因为常量在常量池中就存在了,调用时不需要类的初始化,所以必须在声明时初始化
public static final int j;
Main() {
i = 2;
j = 3;
}
}
复制代码就如上所说的,对于类常量,JVM会缓存在常量池中,在读取该变量时不会加载这个类。
public class Main {
public static final int i = 2;
Main() {
System.out.println("调用构造函数"); // 该方法不会调用
}
public static void main(String[] args) {
System.out.println(Main.i);
}
}
复制代码final修饰基本数据类型变量和引用
@Test
public void final修饰基本类型变量和引用() {
final int a = 1;
final int[] b = {1};
final int[] c = {1};
// b = c;报错
b[0] = 1;
final String aa = "a";
final Fi f = new Fi();
//aa = "b";报错
// f = null;//报错
f.a = 1;
}
复制代码final方法表示该方法不能被子类的方法重写,将方法声明为final,在编译的时候就已经静态绑定了,不需要在运行时动态绑定。final方法调用时使用的是invokespecial指令。
class PersonalLoan{
public final String getName(){
return"personal loan”;
}
}
class CheapPersonalLoan extends PersonalLoan{
@Override
public final String getName(){
return"cheap personal loan";//编译错误,无法被重载
}
public String test() {
return getName(); //可以调用,因为是public方法
}
}
复制代码final类
final类不能被继承,final类中的方法默认也会是final类型的,java中的String类和Integer类都是final类型的。
class Si{
//一般情况下final修饰的变量一定要被初始化。
//只有下面这种情况例外,要求该变量必须在构造方法中被初始化。
//并且不能有空参数的构造方法。
//这样就可以让每个实例都有一个不同的变量,并且这个变量在每个实例中只会被初始化一次
//于是这个变量在单个实例里就是常量了。
final int s ;
Si(int s) {
this.s = s;
}
}
class Bi {
final int a = 1;
final void go() {
//final修饰方法无法被继承
}
}
class Ci extends Bi {
final int a = 1;
// void go() {
// //final修饰方法无法被继承
// }
}
final char[]a = {'a'};
final int[]b = {1};
复制代码final class PersonalLoan{}
class CheapPersonalLoan extends PersonalLoan { //编译错误,无法被继承
}
复制代码@Test
public void final修饰类() {
//引用没有被final修饰,所以是可变的。
//final只修饰了Fi类型,即Fi实例化的对象在堆中内存地址是不可变的。
//虽然内存地址不可变,但是可以对内部的数据做改变。
Fi f = new Fi();
f.a = 1;
System.out.println(f);
f.a = 2;
System.out.println(f);
//改变实例中的值并不改变内存地址。
Fi ff = f;
//让引用指向新的Fi对象,原来的f对象由新的引用ff持有。
//引用的指向改变也不会改变原来对象的地址
f = new Fi();
System.out.println(f);
System.out.println(ff);
}
复制代码final关键字的知识点
-
final成员变量必须在声明的时候初始化或者在构造器中初始化,否则就会报编译错误。final变量一旦被初始化后不能再次赋值。
-
本地变量必须在声明时赋值。 因为没有初始化的过程
-
在匿名类中所有变量都必须是final变量。
-
final方法不能被重写, final类不能被继承
-
接口中声明的所有变量本身是final的。类似于匿名类
-
final和abstract这两个关键字是反相关的,final类就不可能是abstract的。
-
final方法在编译阶段绑定,称为静态绑定(static binding)。
-
将类、方法、变量声明为final能够提高性能,这样JVM就有机会进行估计,然后优化。
final方法的好处:
-
提高了性能,JVM在常量池中会缓存final变量
-
final变量在多线程中并发安全,无需额外的同步开销
-
final方法是静态编译的,提高了调用速度
-
final类创建的对象是只可读的,在多线程可以安全共享
final关键字的最佳实践
final的用法
1、final 对于常量来说,意味着值不能改变,例如 final int i=100。这个i的值永远都是100。 但是对于变量来说又不一样,只是标识这个引用不可被改变,例如 final File f=new File("c:\test.txt");
那么这个f一定是不能被改变的,如果f本身有方法修改其中的成员变量,例如是否可读,是允许修改的。有个形象的比喻:一个女子定义了一个final的老公,这个老公的职业和收入都是允许改变的,只是这个女人不会换老公而已。
关于空白final
final修饰的变量有三种:静态变量、实例变量和局部变量,分别表示三种类型的常量。
另外,final变量定义的时候,可以先声明,而不给初值,这中变量也称为final空白,无论什么情况,编译器都确保空白final在使用之前必须被初始化。 但是,final空白在final关键字final的使用上提供了更大的灵活性,为此,一个类中的final数据成员就可以实现依对象而有所不同,却有保持其恒定不变的特征。
public class FinalTest {
final int p;
final int q=3;
FinalTest(){
p=1;
}
FinalTest(int i){
p=i;//可以赋值,相当于直接定义p
q=i;//不能为一个final变量赋值
}
}
复制代码final内存分配
刚提到了内嵌机制,现在详细展开。 要知道调用一个函数除了函数本身的执行时间之外,还需要额外的时间去寻找这个函数(类内部有一个函数签名和函数地址的映射表)。所以减少函数调用次数就等于降低了性能消耗。
final修饰的函数会被编译器优化,优化的结果是减少了函数调用的次数。如何实现的,举个例子给你看:
public class Test{
final void func(){System.out.println("g");};
public void main(String[] args){
for(int j=0;j<1000;j++)
func();
}}
经过编译器优化之后,这个类变成了相当于这样写:
public class Test{
final void func(){System.out.println("g");};
public void main(String[] args){
for(int j=0;j<1000;j++)
{System.out.println("g");}
}}
复制代码看出来区别了吧?编译器直接将func的函数体内嵌到了调用函数的地方,这样的结果是节省了1000次函数调用,当然编译器处理成字节码,只是我们可以想象成这样,看个明白。
不过,当函数体太长的话,用final可能适得其反,因为经过编译器内嵌之后代码长度大大增加,于是就增加了jvm解释字节码的时间。
在使用final修饰方法的时候,编译器会将被final修饰过的方法插入到调用者代码处,提高运行速度和效率,但被final修饰的方法体不能过大,编译器可能会放弃内联,但究竟多大的方法会放弃,我还没有做测试来计算过。
下面这些内容是通过两个疑问来继续阐述的
使用final修饰方法会提高速度和效率吗
见下面的测试代码,我会执行五次:
public class Test
{
public static void getJava()
{
String str1 = "Java ";
String str2 = "final ";
for (int i = 0; i < 10000; i++)
{
str1 += str2;
}
}
public static final void getJava_Final()
{
String str1 = "Java ";
String str2 = "final ";
for (int i = 0; i < 10000; i++)
{
str1 += str2;
}
}
public static void main(String[] args)
{
long start = System.currentTimeMillis();
getJava();
System.out.println("调用不带final修饰的方法执行时间为:" + (System.currentTimeMillis() - start) + "毫秒时间");
start = System.currentTimeMillis();
String str1 = "Java ";
String str2 = "final ";
for (int i = 0; i < 10000; i++)
{
str1 += str2;
}
System.out.println("正常的执行时间为:" + (System.currentTimeMillis() - start) + "毫秒时间");
start = System.currentTimeMillis();
getJava_Final();
System.out.println("调用final修饰的方法执行时间为:" + (System.currentTimeMillis() - start) + "毫秒时间");
}
}
结果为:
第一次:
调用不带final修饰的方法执行时间为:1732毫秒时间
正常的执行时间为:1498毫秒时间
调用final修饰的方法执行时间为:1593毫秒时间
第二次:
调用不带final修饰的方法执行时间为:1217毫秒时间
正常的执行时间为:1031毫秒时间
调用final修饰的方法执行时间为:1124毫秒时间
第三次:
调用不带final修饰的方法执行时间为:1154毫秒时间
正常的执行时间为:1140毫秒时间
调用final修饰的方法执行时间为:1202毫秒时间
第四次:
调用不带final修饰的方法执行时间为:1139毫秒时间
正常的执行时间为:999毫秒时间
调用final修饰的方法执行时间为:1092毫秒时间
第五次:
调用不带final修饰的方法执行时间为:1186毫秒时间
正常的执行时间为:1030毫秒时间
调用final修饰的方法执行时间为:1109毫秒时间
由以上运行结果不难看出,执行最快的是“正常的执行”即代码直接编写,而使用final修饰的方法,不像有些书上或者文章上所说的那样,速度与效率与“正常的执行”无异,而是位于第二位,最差的是调用不加final修饰的方法。
复制代码观点:加了比不加好一点。
使用final修饰变量会让变量的值不能被改变吗;
见代码:
public class Final
{
public static void main(String[] args)
{
Color.color[3] = "white";
for (String color : Color.color)
System.out.print(color+" ");
}
}
class Color
{
public static final String[] color = { "red", "blue", "yellow", "black" };
}
执行结果:
red blue yellow white
看!,黑色变成了白色。
复制代码
在使用findbugs插件时,就会提示public static String[] color = { "red", "blue", "yellow", "black" };这行代码不安全,但加上final修饰,这行代码仍然是不安全的,因为final没有做到保证变量的值不会被修改!
原因是:final关键字只能保证变量本身不能被赋与新值,而不能保证变量的内部结构不被修改。例如在main方法有如下代码Color.color = new String[]{""};就会报错了。
如何保证数组内部不被修改
那可能有的同学就会问了,加上final关键字不能保证数组不会被外部修改,那有什么方法能够保证呢?答案就是降低访问级别,把数组设为private。这样的话,就解决了数组在外部被修改的不安全性,但也产生了另一个问题,那就是这个数组要被外部使用的。
复制代码解决这个问题见代码:
import java.util.AbstractList;
import java.util.List;
public class Final
{
public static void main(String[] args)
{
for (String color : Color.color)
System.out.print(color + " ");
Color.color.set(3, "white");
}
}
class Color
{
private static String[] _color = { "red", "blue", "yellow", "black" };
public static List<String> color = new AbstractList<String>()
{
@Override
public String get(int index)
{
return _color[index];
}
@Override
public String set(int index, String value)
{
throw new RuntimeException("为了代码安全,不能修改数组");
}
@Override
public int size()
{
return _color.length;
}
};
}
复制代码这样就OK了,既保证了代码安全,又能让数组中的元素被访问了。
final方法的三条规则
规则1:final修饰的方法不可以被重写。
规则2:final修饰的方法仅仅是不能重写,但它完全可以被重载。
规则3:父类中private final方法,子类可以重新定义,这种情况不是重写。
代码示例
规则1代码
public class FinalMethodTest
{
public final void test(){}
}
class Sub extends FinalMethodTest
{
// 下面方法定义将出现编译错误,不能重写final方法
public void test(){}
}
规则2代码
public class Finaloverload {
//final 修饰的方法只是不能重写,完全可以重载
public final void test(){}
public final void test(String arg){}
}
规则3代码
public class PrivateFinalMethodTest
{
private final void test(){}
}
class Sub extends PrivateFinalMethodTest
{
// 下面方法定义将不会出现问题
public void test(){}
}
复制代码抽象类与接口
抽象类和接口以及抽象类和接口的区别。
2.1、抽象类
第一:抽象类怎么定义?在class前添加abstract关键字就行了。
第二:抽象类是无法实例化的,无法创建对象的,所以抽象类是用来被子类继承的。
第三:final和abstract不能联合使用,这两个关键字是对立的。
第四:抽象类的子类可以是抽象类。也可以是非抽象类。
第五:抽象类虽然无法实例化,但是抽象类有构造方法,这个构造方法是供子类使用的。
第六:抽象类中不一定有抽象方法,抽象方法必须出现在抽象类中。
第七:抽象方法怎么定义?
public abstract void doSome();
第八:一个非抽象的类,继承抽象类,必须将抽象类中的抽象方法进行覆盖/重写/实现。
到目前为止,只是学习了抽象类的基础语法,一个类到底声明为抽象还是非抽象,
面试题(判断题):java语言中凡是没有方法体的方法都是抽象方法。
不对,错误的。
Object类中就有很多方法都没有方法体,都是以“;”结尾的,但他们
都不是抽象方法,例如:
public native int hashCode();
这个方法底层调用了C++写的动态链接库程序。
前面修饰符列表中没有:abstract。有一个native。表示调用JVM本地程序。
2.2、接口的基础语法。
1、接口是一种“引用数据类型”。
2、接口是完全抽象的。
3、接口怎么定义:[修饰符列表] interface 接口名{}
4、接口支持多继承。
5、接口中只有常量+抽象方法。
6、接口中所有的元素都是public修饰的
7、接口中抽象方法的public abstract可以省略。
8、接口中常量的public static final可以省略。
9、接口中方法不能有方法体。
复制代码抽象类
一、抽象类的基本概念
普通类是一个完善的功能类,可以直接产生实例化对象,并且在普通类中可以包含有构造方法、普通方法、static方法、常量和变量等内容。而抽象类是指在普通类的结构里面增加抽象方法的组成部分。
那么什么叫抽象方法呢?在所有的普通方法上面都会有一个“{}”,这个表示方法体,有方法体的方法一定可以被对象直接使用。而抽象方法,是指没有方法体的方法,同时抽象方法还必须使用关键字abstract做修饰。
而拥有抽象方法的类就是抽象类,抽象类要使用abstract关键字声明。
下面我写一个关于抽象类的例子:
abstract class A{//定义一个抽象类
public void fun(){//普通方法
System.out.println("存在方法体的方法");
}
public abstract void print();
//抽象方法,没有方法体,有abstract关键字做修饰
}
复制代码二、抽象类的使用
我们看一下下面这个例子:
abstract class A{//定义一个抽象类
public void fun(){//普通方法
System.out.println("存在方法体的方法");
}
public abstract void print();
//抽象方法,没有方法体,有abstract关键字做修饰
}
public class TestDemo {
public static void main(String[] args) {
A a = new A();
}
}
复制代码运行结果:
Exception in thread "main" java.lang.Error: Unresolved compilation problem:
Cannot instantiate the type A
at com.wz.abstractdemo.TestDemo.main(TestDemo.java:15)
复制代码从上可知,A是抽象的,无法直接进行实例化操作。为什么不能直接实例化呢?当一个类实例化之后,就意味着这个对象可以调用类中的属性或者放过了,但在抽象类里存在抽象方法,而抽象方法没有方法体,没有方法体就无法进行调用。既然无法进行方法调用的话,又怎么去产生实例化对象呢。所以抽象类不能进行实例化对象。
- 抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public;
- 抽象类不能直接实例化,需要依靠子类采用向上转型的方式处理;
- 抽象类必须有子类,使用extends继承,一个子类只能继承一个抽象类;
- 子类(如果不是抽象类)则必须覆写抽象类之中的全部抽象方法(如果子类没有实现父类的抽象方法,则必须将子类也定义为为abstract类。)否则编译不通过;
abstract class A{//定义一个抽象类
public void fun(){//普通方法
System.out.println("存在方法体的方法");
}
public abstract void print();
//抽象方法,没有方法体,有abstract关键字做修饰
}
//单继承
class B extends A{
//B类是抽象类的子类,是一个普通类
@Override
public void print() {//强制要求重写(也叫”实现“)
System.out.println("Hello World !");
}
}
public class TestDemo {
public static void main(String[] args) {
//多态
A a = new B();//向上转型
a.print();//被子类所覆写的过的方法
}
}
复制代码运行结果:
Hello World !
复制代码现在就可以清楚的发现:
- 抽象类继承子类里面有明确的方法覆写要求,而普通类可以有选择性的来决定是否需要覆写;
- 抽象类实际上就比普通类多了一些抽象方法而已,其他组成部分和普通类完全一样;
- 普通类对象可以直接实例化,但抽象类的对象必须经过向上转型之后才可以得到。
虽然一个类的子类可以去继承任意的一个普通类,可是从开发的实际要求来讲,普通 类尽量不要去继承另外一个普通类,而是去继承抽象类。
三、抽象类的使用限制
-
抽象类中有构造方法么? 由于抽象类里会存在一些属性,那么抽象类中一定存在构造方法,其存在目的是为了属性的初始化。 并且子类对象实例化的时候,依然满足先执行父类构造,再执行子类构造的顺序。
下面我写一个例子:
package com.wz.abstractdemo; abstract class A{//定义一个抽象类 public A(){ System.out.println("*****A类构造方法*****"); } public abstract void print();//抽象方法,没有方法体,有abstract关键字做修饰 } //单继承 class B extends A{//B类是抽象类的子类,是一个普通类 public B(){ System.out.println("*****B类构造方法*****"); } @Override public void print() {//强制要求覆写 System.out.println("Hello World !"); } } public class TestDemo { public static void main(String[] args) { A a = new B();//向上转型 } } 复制代码执行结果:
*****A类构造方法***** *****B类构造方法***** 复制代码
-
抽象类可以用final声明么? 不能,因为抽象类必须有子类,而final定义的类不能有子类;(final关键字规定不可以进行继承,因此final与abstract这两个关键字是冲突的)
-
抽象类能否使用static声明? 下面我写一个例子:
static abstract class A{//定义一个抽象类 public abstract void print(); } class B extends A{ public void print(){ System.out.println("**********"); } } public class TestDemo { public static void main(String[] args) { A a = new B();//向上转型 a.print(); } } 复制代码执行结果:
Exception in thread "main" java.lang.Error: Unresolved compilation problem: Illegal modifier for the class A; only public, abstract & final are permitted at com.manman.abstractdemo.A.<init>(TestDemo.java:3) at com.manman.abstractdemo.B.<init>(TestDemo.java:9) at com.manman.abstractdemo.TestDemo.main(TestDemo.java:18) 复制代码下面再看一个关于内部抽象类的:
abstract class A{//定义一个抽象类 static abstract class B{//static定义的内部类属于外部类 public abstract void print(); } } class C extends A.B{ public void print(){ System.out.println("**********"); } } public class TestDemo { public static void main(String[] args) { A.B ab = new C();//向上转型 ab.print(); } } 复制代码执行结果:
********** 复制代码由此可见,外部抽象类不允许使用static声明,而内部的抽象类运行使用static声明。使用static声明的内部抽象类相当于一个外部抽象类,继承的时候使用“外部类.内部类”的形式表示类名称。
-
可以直接调用抽象类中用static声明的方法么? 任何时候,如果要执行类中的static方法的时候,都可以在没有对象的情况下直接调用,对于抽象类也一样。
下面我写个例子:
abstract class A{//定义一个抽象类 public static void print(){ System.out.println("Hello World !"); } } public class TestDemo { public static void main(String[] args) { A.print(); } } 复制代码运行结果:
Hello World ! 复制代码
接口
一、基本概念
接口(Interface),在JAVA编程语言中是一个抽象类型,是抽象方法的集合。接口 通常以interface来声明。一个类通过继承接口的方式,从而来继承接口的抽象方法。
如果一个类只由抽象方法和全局常量组成,那么这种情况下不会将其定义为一个抽象类。只会定义为一个接口,所以接口严格的来讲属于一个特殊的类,而这个类里面只有抽象方法和全局常量,就连构造方法也没有。
下面我写一个例子:
interface A{//定义一个接口
public static final String MSG = "hello";//全局常量
public abstract void print();//抽象方法
}
复制代码二、接口的使用
1、由于接口里面存在抽象方法,所以接口对象不能直接使用关键字new进行实例化。接口的使用原则如下:
- 接口必须要有子类,但此时一个子类可以使用implements关键字实现多个接口;
- 接口的子类(如果不是抽象类),那么必须要覆写接口中的全部抽象方法;
- 接口的对象可以利用子类对象的向上转型进行实例化。
下面我用一个例子来说明:
package com.gzm.interfacedemo;
interface A{//定义一个接口A
public static final String MSG = "hello";//全局常量
public abstract void print();//抽象方法
}
interface B{//定义一个接口B
public abstract void get();
}
class X implements A,B{//X类实现了A和B两个接口
@Override
public void print() {
System.out.println("接口A的抽象方法print()");
}
@Override
public void get() {
System.out.println("接口B的抽象方法get()");
}
}
public class TestDemo {
public static void main(String[] args){
X x = new X();//实例化子类对象
A a = x;//向上转型
B b = x;//向上转型
a.print();
b.get();
}
}
复制代码运行结果:
接口A的抽象方法print()
接口B的抽象方法get()
复制代码以上的代码实例化了X类的对象,由于X类是A和B的子类,那么X类的对象可以变为A接口或者B接口对象。我们把测试主类代码改一下:
public class TestDemo {
public static void main(String[] args){
A a = new X();
B b = (B) a;
b.get();
}
}
复制代码运行结果:
接口B的抽象方法get()
复制代码下面我们接着做一个测验:
public class TestDemo {
public static void main(String[] args){
A a = new X();
B b = (B) a;
b.get();
System.out.println(a instanceof A);
System.out.println(a instanceof B);
}
复制代码运行结果:
接口B的抽象方法get()
true
true
复制代码我们发现,从定义结构来讲,A和B两个接口没有任何直接联系,但这两个接口却拥有同一个子类。我们不要被类型和名称所迷惑,因为实例化的是X子类,而这个类对象属于B类的对象,所以以上代码可行,只不过从代码的编写规范来讲,并不是很好。
2、对于子类而言,除了实现接口外,还可以继承抽象类。若既要继承抽象类,同时还要实现接口的话,使用一下语法格式:
class 子类 [extends 父类] [implemetns 接口1,接口2,...] {}
复制代码下面我用例子来说明一下:
interface A{//定义一个接口A
public static final String MSG = "hello";//全局常量
public abstract void print();//抽象方法
}
interface B{//定义一个接口B
public abstract void get();
}
abstract class C{//定义一个抽象类C
public abstract void change();
}
class X extends C implements A,B{//X类继承C类,并实现了A和B两个接口
@Override
public void print() {
System.out.println("接口A的抽象方法print()");
}
@Override
public void get() {
System.out.println("接口B的抽象方法get()");
}
@Override
public void change() {
System.out.println("抽象类C的抽象方法change()");
}
}
复制代码对于接口,里面的组成只有抽象方法和全局常量,所以很多时候为了书写简单,可以不用写public abstract 或者public static final。并且,接口中的访问权限只有一种:public,即:定义接口方法和全局常量的时候就算没有写上public,那么最终的访问权限也是public,注意不是default。以下两种写法是完全等价的:
interface A{
public static final String MSG = "hello";
public abstract void print();
}
复制代码等价于:
interface A{
String MSG = "hello";
void print();
}
复制代码但是,这样会不会带来什么问题呢?如果子类子类中的覆写方法也不是public,我们来看:
package com.gzm.interfacedemo;
interface A{
String MSG = "hello";
void print();
}
class X implements A{
//注意子类这里不是public 而是默认default
void print() {
System.out.println("接口A的抽象方法print()");
}
}
public class TestDemo {
public static void main(String[] args){
A a = new X();
a.print();
}
}
复制代码下面我们看看运行结果:
Exception in thread "main" java.lang.IllegalAccessError: com.wz.interfacedemo.X.print()V
at com.gzm.interfacedemo.TestDemo.main(TestDemo.java:22)
复制代码这是因为接口中默认是public修饰,若子类中没用public修饰,则访问权限变严格了,给子类分配的是更低的访问权限。所以,在定义接口的时候强烈建议在抽象方法前加上public ,子类也加上:
interface A{
String MSG = "hello";
public void print();
}
class X implements A{
public void print() {
System.out.println("接口A的抽象方法print()");
}
}
复制代码3、在Java中,一个抽象类只能继承一个抽象类,但一个接口却可以使用extends关键字同时继承多个接口(但接口不能继承抽象类)。
下面我写一个例子:
interface A{
public void funA();
}
interface B{
public void funB();
}
//C接口同时继承了A和B两个接口
interface C extends A,B{//使用的是extends
public void funC();
}
class X implements C{
@Override
public void funA() {
}
@Override
public void funB() {
}
@Override
public void funC() {
}
}
复制代码由此可见,从继承关系来说接口的限制比抽象类少:
- 一个抽象类只能继承一个抽象父类,而接口可以继承多个接口;
- 一个子类只能继承一个抽象类,却可以实现多个接口(在Java中,接口的主要功能是解决单继承局限问题)
4、从接口的概念上来讲,接口只能由抽象方法和全局常量组成,但是内部结构是不 受概念限制的,正如抽象类中可以定义抽象内部类一样,在接口中也可以定义普通内 部类、抽象内部类和内部接口(但从实际的开发来讲,用户自己去定义内部抽象类或 内部接口的时候是比较少见的)
下面我们看一个例子,在接口中定义一个抽象内部类:
interface A{
public void funA();
abstract class B{//定义一个抽象内部类
public abstract void funB();
}
}
复制代码在接口中如果使用了static去定义一个内接口,它表示一个外部接口:
interface A{
public void funA();
static interface B{//使用了static,是一个外部接口
public void funB();
}
}
class X implements A.B{
@Override
public void funB() {
}
}
复制代码三、接口的实际应用(标准定义)
在日常的生活之中,接口这一名词经常听到的,例如:USB接口、打印接口、充电接口等等。
如果要进行开发,要先开发出USB接口标准,然后设备厂商才可以设计出USB设备。
现在假设每一个USB设备只有两个功能:安装驱动程序、工作。 定义一个USB的标准:
interface USB { // 操作标准
public void install() ;
public void work() ;
}
复制代码在电脑上应用此接口:
class Computer {
public void plugin(USB usb) {
usb.install() ;
usb.work() ;
}
}
复制代码定义USB设备—手机:
class Phone implements USB {
public void install() {
System.out.println("安装手机驱动程序。") ;
}
public void work() {
System.out.println("手机与电脑进行工作。") ;
}
}
复制代码四、接口的作用
规范性
接口的规范性体现在抽象方法中,因为子类实现接口,就必须全部重写接口中所有的抽象方法,而且方法声明一模一样,这就是强制性,也是规范性的体现。
拓展性
生活中的接口有很多,USB接口,插座孔,充电孔,等只要是按照接口的规则创建,就可以和接口对接,所有按照接口规范创建的都可以对接,所有的实现类只要实现接口重写接口中所有的抽象方法【规则】,就可以使用,这也就是接口的拓展性。
五、接口中的成员特点
接口中所有的变量都是被final修饰的,也就是只能赋值一次。所以接口中也没有变量这一说,都是常量。
-
接口中默认的常量使用final修饰的,只能赋值一次。
-
接口中默认的常量默认都是static修饰的,也就是说可以通过类名.调用。
-
接口中默认都是public修饰的,都是公开的。
接口中所有的方法都是抽象方法,所以都默认使用public abstract修饰
构造方法
因为接口不能创建对象,所以接口中也没有构造方法,没有构造代码块,没有静态代码块。
-
接口中没有构造方法
-
接口中没有构造代码块
-
接口中没有静态代码块
六、抽象类和接口有什么区别
- 抽象类是半抽象的,接口是完全抽象的。
- 抽象类中有构造方法,接口没有构造方法。
- 接口和接口之间支持多继承,类和类之间只能单继承。
- 一个类可以同时实现多个接口,一个抽象类只能继承一个类。
- 接口中只允许出现常量和抽象方法。
注:JDK 1.8 以后,接口里可以有静态方法和方法体了。
JDK 1.8 以后,接口允许包含具体实现的方法,该方法称为"默认方法",默认方法使用 default 关键字修饰。
JDK 1.9 以后,允许将方法定义为 private,使得某些复用的代码不会把方法暴露出去。
七、思维导图

Object 类
一、Object类简介
Object类是Javajava.lang包下的核心类,Object类是所有类的父类,何一个类时候如果没有明确的继承一个父类的话,那么它就是Object的子类;
以下两种类的定义的最终效果是完全相同的:
class Person{
}
class Person extends Object{
}
复制代码使用Object类型接收所有对象
Object 类属于
java.lang包,此包下的所有类在使用时无需手动导入,系统会在程序编译期间自动导入
Object 类的结构图(Object提供了11 个方法)
下面我们对这些方法一一分析,看看这些方法都有什么作用:
- clone()
保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。
- getClass()
final方法,返回Class类型的对象,反射来获取对象。
- toString()
该方法用得比较多,一般子类都有覆盖,来获取对象的信息。
- finalize()
该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。
- equals()
比较对象的内容是否相等
- hashCode()
该方法用于哈希查找,重写了equals方法一般都要重写hashCode方法。这个方法在一些具有哈希功能的Collection中用到。
- wait()
wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
其他线程调用了该对象的notify方法。 其他线程调用了该对象的notifyAll方法。 其他线程调用了interrupt中断该线程。 时间间隔到了。 此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。
- notify()
该方法唤醒在该对象上等待的某个线程。
- notifyAll()
该方法唤醒在该对象上等待的所有线程。
二. Object类的常用方法
| 方法名称 | 类型 | 描述 |
|---|---|---|
| toString( ) | 普通 | 取得对象信息 |
| equals() | 普通 | 比较对象是否相等 |
- toString方法
toString():取得对象信息,返回该对象的字符串表示
下面我写一个例子:
public class ObjectTest01 {
public static void main(String[] args) {
Person person = new Person(20,"manamn");
System.out.println(person);
}
}
class Person{
private int age;
private String name;
public Person() {
}
public Person(int age, String name) {
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
复制代码运行结果:
com.manman.javase.object.Person@4554617c
复制代码在使用对象直接输出的时候,默认输出的是一个对象在堆内存上的地址值;如若要输出该对象的内容,则要覆写toString()方法
覆写Person中的toString()方法
@Override
public String toString(){
return "年龄为" + this.age + "名字为" + this.name;
}
复制代码此时执行结果:
年龄:20名字:manamn
复制代码toString( )的核心目的在于取得对象信息
String作为信息输出的重要数据类型,在Java中所有的数据类型只要遇见String就执行了+,都要求其变为字符串后连接,而所有对象想要变为字符串就默认用toString( )方法
例如:
System.out.println("hello" + 123);
>>> 输出:hello123
复制代码为什么hello 和 123 (一个是字符串,一个是int类型的数据) 就可以直接拼接在一起呢?
因为字符串是爸爸,在这个拼爹的时代,他有一个万能的爸爸Object
换而言之,Object是所有类的父类,任意类都是继承Object类的。而Object中定义了 toString()方法,所以任意类中都包含了toString()方法,对象在实例化之后都可以调用。
所以任意对象转字符串的输出,是通过覆写 toString()方法实现的…
每一个类中都包含有toString(),但是并不是每一个类都覆写了toString()
-
quals方法
equals():对象比较
String类对象比较使用的是 equals()方法,实际上String类的equals()方法就是覆写 Object类中的equals()方法
- 基本数据类型之间比较使用 “==”(如: a == 3,b == 4, a == b,比较的是值是否相等)
- 引用数据类型比较 : 调用equals()方法进行比较。
用equals()来比较两个对象内容是否相同:
package com.manman.javase.object; /** * @author 满满 * createDate 2022/2/23 15:34 */ public class ObjectTest02 { public static void main(String[] args) { People people1 = new People(30,"zhangsan"); People people2 = new People(30,"zhangsan"); System.out.println(people1.equals(people2)); } } class People{ private int age; private String name; public People() { } public People(int age, String name) { this.age = age; this.name = name; } } 复制代码执行结果:
false 复制代码两个对象people1和people2的内容明明相等,应该是true呀?怎么会是false?
因为此时直接调用equals()方法默认进行比较的是两个对象的地址。
在源码中,传递来的Object对象和当前对象比较地址值,返回布尔值。
但是,new一下就会在堆上创建新空间,两个对象地址自然不会相同,所以为false。
但是在判断两个对象是否相等时,比如要判断一个Person类的两个对象的姓名是否相同时,此时要重新覆写
equals()
还是上面的例子,覆写equals()方法:
/**
* 这里重写父类Object 的equals方法
* @param obj
* @return
*/
@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
//判断内存地址是否相同 内存地址相同,则他们是同一个引用返回true
if (this == obj){
return true;
}
if ( !(obj instanceof People)){
return false;
}
// 程序进行到这里 说明 它不是空 且 是People对象
// 此时进行向下转型 将Object 强转为 Perple对象
People p = (People)obj;
return p.name.equals(this.name)&& p.age == this.age;
}
复制代码执行结果:
true
复制代码所以,引用类型的数据在进行比较时,应该先覆写equals()方法,不然比较的还是两个对象的堆内存地址值,必然不会相等.
String类
常用类
1、八种基本数据类型对应的包装类。
1.1、什么是自动装箱和自动拆箱,代码怎么写? Integer x = 100; // x里面并不是保存100,保存的是100这个对象的内存地址。 Integer y = 100; System.out.println(x == y); // true
Integer x = 128;
Integer y = 128;
System.out.println(x == y); // false
1.2、Integer类常用方法。
Integer.valueOf()
Integer.parseInt("123")
Integer.parseInt("中文") : NumberFormatException
1.3、Integer String int三种类型互相转换。
复制代码2、日期类 2.1、获取系统当前时间 Date d = new Date(); 2.2、日期格式化:Date --> String yyyy-MM-dd HH:mm:ss SSS SimpleDateFormat sdf = new SimpleDate("yyyy-MM-dd HH:mm:ss SSS"); String s = sdf.format(new Date()); 2.3、String --> Date SimpleDateFormat sdf = new SimpleDate("yyyy-MM-dd HH:mm:ss"); Date d = sdf.parse("2008-08-08 08:08:08"); 2.4、获取毫秒数 long begin = System.currentTimeMillis(); Date d = new Date(begin - 1000 * 60 * 60 * 24);
3、数字类 3.1、DecimalFormat数字格式化 ###,###.## 表示加入千分位,保留两个小数。 ###,###.0000 表示加入千分位,保留4个小数,不够补0 3.2、BigDecimal 财务软件中通常使用BigDecimal
4、随机数
4.1、怎么产生int类型随机数。 Random r = new Random(); int i = r.nextInt(); 4.2、怎么产生某个范围之内的int类型随机数。 Random r = new Random(); int i = r.nextInt(101); // 产生[0-100]的随机数。
5、枚举
5.1、枚举是一种引用数据类型。 5.2、枚举编译之后也是class文件。 5.3、枚举类型怎么定义? enum 枚举类型名{ 枚举值,枚举值2,枚举值3 } 5.4、当一个方法执行结果超过两种情况,并且是一枚一枚可以列举出来 的时候,建议返回值类型设计为枚举类型。
异常
异常处理机制
-
java中异常的作用是:增强程序健壮性。
-
java中异常以类和对象的形式存在。
1、java的异常处理机制
1.1、异常在java中以类和对象的形式存在。那么异常的继承结构是怎样的?
我们可以使用UML图来描述一下继承结构。
画UML图有很多工具,例如:Rational Rose(收费的)、starUML等....
Object
Object下有Throwable(可抛出的)
Throwable下有两个分支:Error(不可处理,直接退出JVM)和Exception(可处理的)
Exception下有两个分支:
Exception的直接子类:编译时异常(要求程序员在编写程序阶段必须预先对这些异常进行处理,如果不处理编译器报错,因此得名编译时异常。)。
RuntimeException:运行时异常。(在编写程序阶段程序员可以预先处理,也可以不管,都行。)
1.2、编译时异常和运行时异常,都是发生在运行阶段。编译阶段异常是不会发生的。
编译时异常因为什么而得名?
因为编译时异常必须在编译(编写)阶段预先处理,如果不处理编译器报错,因此得名。
所有异常都是在运行阶段发生的。因为只有程序运行阶段才可以new对象。
因为异常的发生就是new异常对象。
1.3、编译时异常和运行时异常的区别?
编译时异常一般发生的概率比较高。
举个例子:
你看到外面下雨了,倾盆大雨的。
你出门之前会预料到:如果不打伞,我可能会生病(生病是一种异常)。
而且这个异常发生的概率很高,所以我们出门之前要拿一把伞。
“拿一把伞”就是对“生病异常”发生之前的一种处理方式。
对于一些发生概率较高的异常,需要在运行之前对其进行预处理。
运行时异常一般发生的概率比较低。
举个例子:
小明走在大街上,可能会被天上的飞机轮子砸到。
被飞机轮子砸到也算一种异常。
但是这种异常发生概率较低。
在出门之前你没必要提前对这种发生概率较低的异常进行预处理。
如果你预处理这种异常,你将活的很累。
假设你在出门之前,你把能够发生的异常都预先处理,你这个人会更加
的安全,但是你这个人活的很累。
假设java中没有对异常进行划分,没有分为:编译时异常和运行时异常,
所有的异常都需要在编写程序阶段对其进行预处理,将是怎样的效果呢?
首先,如果这样的话,程序肯定是绝对的安全的。
但是程序员编写程序太累,代码到处都是处理异常
的代码。
1.4、编译时异常还有其他名字:
受检异常:CheckedException
受控异常
1.5、运行时异常还有其它名字:
未受检异常:UnCheckedException
非受控异常
1.6、再次强调:所有异常都是发生在运行阶段的。
1.7、Java语言中对异常的处理包括两种方式:
第一种方式:在方法声明的位置上,使用throws关键字,抛给上一级。
谁调用我,我就抛给谁。抛给上一级。
第二种方式:使用try..catch语句进行异常的捕捉。
这件事发生了,谁也不知道,因为我给抓住了。
举个例子:
我是某集团的一个销售员,因为我的失误,导致公司损失了1000元,
“损失1000元”这可以看做是一个异常发生了。我有两种处理方式,
第一种方式:我把这件事告诉我的领导【异常上抛】
第二种方式:我自己掏腰包把这个钱补上。【异常的捕捉】
张三 --> 李四 ---> 王五 --> CEO
思考:
异常发生之后,如果我选择了上抛,抛给了我的调用者,调用者需要
对这个异常继续处理,那么调用者处理这个异常同样有两种处理方式。
1.8、注意:Java中异常发生之后如果一直上抛,最终抛给了main方法,main方法继续
向上抛,抛给了调用者JVM,JVM知道这个异常发生,只有一个结果。终止java程序的执行。
复制代码异常体系图
从上面这幅图可以看出,Throwable是java语言中所有错误和异常的超类(万物即可抛)。它有两个子类:Error、Exception。
Java标准库内建了一些通用的异常,这些类以Throwable为顶层父类。
Throwable又派生出Error类和Exception类。
错误:Error类以及他的子类的实例,代表了JVM本身的错误。错误不能被程序员通过代码处理,Error很少出现。因此,程序员应该关注Exception为父类的分支下的各种异常类。
异常:Exception以及他的子类,代表程序运行时发送的各种不期望发生的事件。可以被Java异常处理机制使用,是异常处理的核心。
总体上我们根据Javac对异常的处理要求,将异常类分为2类。
非检查异常(unckecked exception):Error 和 RuntimeException 以及他们的子类。javac在编译时,不会提示和发现这样的异常,不要求在程序处理这些异常。所以如果愿意,我们可以编写代码处理(使用try…catch…finally)这样的异常,也可以不处理。
对于这些异常,我们应该修正代码,而不是去通过异常处理器处理 。这样的异常发生的原因多半是代码写的有问题。如除0错误ArithmeticException,错误的强制类型转换错误ClassCastException,数组索引越界ArrayIndexOutOfBoundsException,使用了空对象NullPointerException等等。
检查异常(checked exception):除了Error 和 RuntimeException的其它异常。javac强制要求程序员为这样的异常做预备处理工作(使用try…catch…finally或者throws)。在方法中要么用try-catch语句捕获它并处理,要么用throws子句声明抛出它,否则编译不会通过。
这样的异常一般是由程序的运行环境导致的。因为程序可能被运行在各种未知的环境下,而程序员无法干预用户如何使用他编写的程序,于是程序员就应该为这样的异常时刻准备着。如SQLException , IOException,ClassNotFoundException 等。
需要明确的是:检查和非检查是对于javac来说的,这样就很好理解和区分了。
初识异常
异常是在执行某个函数时引发的,而函数又是层级调用,形成调用栈的,因为,只要一个函数发生了异常,那么他的所有的caller都会被异常影响。当这些被影响的函数以异常信息输出时,就形成的了异常追踪栈。
异常最先发生的地方,叫做异常抛出点。
public class 异常 {
public static void main (String [] args )
{
System . out. println( "----欢迎使用命令行除法计算器----" ) ;
CMDCalculate ();
}
public static void CMDCalculate ()
{
Scanner scan = new Scanner ( System. in );
int num1 = scan .nextInt () ;
int num2 = scan .nextInt () ;
int result = devide (num1 , num2 ) ;
System . out. println( "result:" + result) ;
scan .close () ;
}
public static int devide (int num1, int num2 ){
return num1 / num2 ;
}
// ----欢迎使用命令行除法计算器----
// 1
// 0
// Exception in thread "main" java.lang.ArithmeticException: / by zero
// at com.javase.异常.异常.devide(异常.java:24)
// at com.javase.异常.异常.CMDCalculate(异常.java:19)
// at com.javase.异常.异常.main(异常.java:12)
复制代码从上面的例子可以看出,当devide函数发生除0异常时,devide函数将抛出ArithmeticException异常,因此调用他的CMDCalculate函数也无法正常完成,因此也发送异常,而CMDCalculate的caller——main 因为CMDCalculate抛出异常,也发生了异常,这样一直向调用栈的栈底回溯。
这种行为叫做异常的冒泡,异常的冒泡是为了在当前发生异常的函数或者这个函数的caller中找到最近的异常处理程序。由于这个例子中没有使用任何异常处理机制,因此异常最终由main函数抛给JRE,导致程序终止。
上面的代码不使用异常处理机制,也可以顺利编译,因为2个异常都是非检查异常。但是下面的例子就必须使用异常处理机制,因为异常是检查异常。
代码中我选择使用throws声明异常,让函数的调用者去处理可能发生的异常。但是为什么只throws了IOException呢?因为FileNotFoundException是IOException的子类,在处理范围内。
异常和错误
下面看一个例子
//错误即error一般指jvm无法处理的错误
//异常是Java定义的用于简化错误处理流程和定位错误的一种工具。
public class 错误和错误 {
Error error = new Error();
public static void main(String[] args) {
throw new Error();
}
//下面这四个异常或者错误有着不同的处理方法
public void error1 (){
//编译期要求必须处理,因为这个异常是最顶层异常,包括了检查异常,必须要处理
try {
throw new Throwable();
} catch (Throwable throwable) {
throwable.printStackTrace();
}
}
//Exception也必须处理。否则报错,因为检查异常都继承自exception,所以默认需要捕捉。
public void error2 (){
try {
throw new Exception();
} catch (Exception e) {
e.printStackTrace();
}
}
//error可以不处理,编译不报错,原因是虚拟机根本无法处理,所以啥都不用做
public void error3 (){
throw new Error();
}
//runtimeexception众所周知编译不会报错
public void error4 (){
throw new RuntimeException();
}
// Exception in thread "main" java.lang.Error
// at com.javase.异常.错误.main(错误.java:11)
}
复制代码异常的处理方式
在编写代码处理异常时,对于检查异常,有2种不同的处理方式:
使用try…catch…finally语句块处理它。
或者,在函数签名中使用throws 声明交给函数调用者caller去解决。
下面看几个具体的例子,包括error,exception和throwable
上面的例子是运行时异常,不需要显示捕获。 下面这个例子是可检查异常需,要显示捕获或者抛出
@Test
public void testException() throws IOException
{
//FileInputStream的构造函数会抛出FileNotFoundException
FileInputStream fileIn = new FileInputStream("E:\\a.txt");
int word;
//read方法会抛出IOException
while((word = fileIn.read())!=-1)
{
System.out.print((char)word);
}
//close方法会抛出IOException
fileIn.close();
}
复制代码一般情况下的处理方式 try catch finally
public class 异常处理方式 {
@Test
public void main() {
try{
//try块中放可能发生异常的代码。
InputStream inputStream = new FileInputStream("a.txt");
//如果执行完try且不发生异常,则接着去执行finally块和finally后面的代码(如果有的话)。
int i = 1/0;
//如果发生异常,则尝试去匹配catch块。
throw new SQLException();
//使用1.8jdk同时捕获多个异常,runtimeexception也可以捕获。只是捕获后虚拟机也无法处理,所以不建议捕获。
}catch(SQLException | IOException | ArrayIndexOutOfBoundsException exception){
System.out.println(exception.getMessage());
//每一个catch块用于捕获并处理一个特定的异常,或者这异常类型的子类。Java7中可以将多个异常声明在一个catch中。
//catch后面的括号定义了异常类型和异常参数。如果异常与之匹配且是最先匹配到的,则虚拟机将使用这个catch块来处理异常。
//在catch块中可以使用这个块的异常参数来获取异常的相关信息。异常参数是这个catch块中的局部变量,其它块不能访问。
//如果当前try块中发生的异常在后续的所有catch中都没捕获到,则先去执行finally,然后到这个函数的外部caller中去匹配异常处理器。
//如果try中没有发生异常,则所有的catch块将被忽略。
}catch(Exception exception){
System.out.println(exception.getMessage());
//...
}finally{
//finally块通常是可选的。
//无论异常是否发生,异常是否匹配被处理,finally都会执行。
//finally主要做一些清理工作,如流的关闭,数据库连接的关闭等。
}
复制代码一个try至少要跟一个catch或者finally
try {
int i = 1;
}finally {
//一个try至少要有一个catch块,否则, 至少要有1个finally块。但是finally不是用来处理异常的,finally不会捕获异常。
}
}
复制代码异常出现时该方法后面的代码就不会再执行了,即使异常已经被捕获了。这里举一个不一样的例子,在catch语句块之后仍然可以试用 try catch finally
@Test
public void test() {
try {
throwE();
System.out.println("我前面抛出异常了");
System.out.println("我不会执行了");
} catch (StringIndexOutOfBoundsException e) {
System.out.println(e.getCause());
}catch (Exception ex) {
//在catch块中仍然可以使用try catch finally
try {
throw new Exception();
}catch (Exception ee) {
}finally {
System.out.println("我所在的catch块没有执行,我也不会执行的");
}
}
}
//在方法声明中抛出的异常必须由调用方法处理或者继续往上抛,
// 当抛到jre时由于无法处理终止程序
public void throwE (){
// Socket socket = new Socket("127.0.0.1", 80);
//手动抛出异常时,不会报错,但是调用该方法的方法需要处理这个异常,否则会出错。
// java.lang.StringIndexOutOfBoundsException
// at com.javase.异常.异常处理方式.throwE(异常处理方式.java:75)
// at com.javase.异常.异常处理方式.test(异常处理方式.java:62)
throw new StringIndexOutOfBoundsException();
}
复制代码"不负责任"的throws
throws是另一种处理异常的方式,它不同于try…catch…finally,throws仅仅是将函数中可能出现的异常向调用者声明,而自己则不具体处理。
采取这种异常处理的原因可能是:方法本身不知道如何处理这样的异常,或者说让调用者处理更好,调用者需要为可能发生的异常负责。
public void foo() throws ExceptionType1 , ExceptionType2 ,ExceptionTypeN
{
//foo内部可以抛出 ExceptionType1 , ExceptionType2 ,ExceptionTypeN 类的异常,或者他们的子类的异常对象。
}
复制代码纠结的finally
finally块不管异常是否发生,只要对应的try执行了,则它一定也执行。只有一种方法让finally块不执行:**System.exit()。**因此finally块通常用来做资源释放操作:关闭文件,关闭数据库连接等等。
良好的编程习惯是:在try块中打开资源,在finally块中清理释放这些资源。
需要注意的地方:
1、finally块没有处理异常的能力。处理异常的只能是catch块。
2、在同一try…catch…finally块中 ,如果try中抛出异常,且有匹配的catch块,则先执行catch块,再执行finally块。如果没有catch块匹配,则先执行finally,然后去外面的调用者中寻找合适的catch块。
3、在同一try…catch…finally块中 ,try发生异常,且匹配的catch块中处理异常时也抛出异常,那么后面的finally也会执行:首先执行finally块,然后去外围调用者中寻找合适的catch块。
public class finally使用 {
public static void main(String[] args) {
try {
throw new IllegalAccessException();
}catch (IllegalAccessException e) {
// throw new Throwable();
//此时如果再抛异常,finally无法执行,只能报错。
//finally无论何时都会执行
//除非我显示调用。此时finally才不会执行
System.exit(0);
}finally {
System.out.println("你真狠");
}
}
}
复制代码throw : JRE也使用的关键字
throw exceptionObject
程序员也可以通过throw语句手动显式的抛出一个异常。throw语句的后面必须是一个异常对象。
throw 语句必须写在函数中,执行throw 语句的地方就是一个异常抛出点,==它和由JRE自动形成的异常抛出点没有任何差别。==
public void save(User user)
{
if(user == null)
throw new IllegalArgumentException("User对象为空");
//......
}
复制代码自定义异常
如果要自定义异常类,则扩展Exception类即可,因此这样的自定义异常都属于检查异常(checked exception)。如果要自定义非检查异常,则扩展自RuntimeException。
按照国际惯例,自定义的异常应该总是包含如下的构造函数:
一个无参构造函数 一个带有String参数的构造函数,并传递给父类的构造函数。 一个带有String参数和Throwable参数,并都传递给父类构造函数 一个带有Throwable 参数的构造函数,并传递给父类的构造函数。 下面是IOException类的完整源代码,可以借鉴。
public class IOException extends Exception
{
static final long serialVersionUID = 7818375828146090155L;
public IOException()
{
super();
}
public IOException(String message)
{
super(message);
}
public IOException(String message, Throwable cause)
{
super(message, cause);
}
public IOException(Throwable cause)
{
super(cause);
}
}
复制代码异常的注意事项
异常的注意事项
当子类重写父类的带有 throws声明的函数时,其throws声明的异常必须在父类异常的可控范围内——用于处理父类的throws方法的异常处理器,必须也适用于子类的这个带throws方法 。这是为了支持多态。
例如,父类方法throws 的是2个异常,子类就不能throws 3个及以上的异常。父类throws IOException,子类就必须throws IOException或者IOException的子类。
至于为什么?我想,也许下面的例子可以说明。
class Father
{
public void start() throws IOException
{
throw new IOException();
}
}
class Son extends Father
{
public void start() throws Exception
{
throw new SQLException();
}
}
复制代码/**************假设上面的代码是允许的(实质是错误的)*******************/
class Test
{
public static void main(String[] args)
{
Father[] objs = new Father[2];
objs[0] = new Father();
objs[1] = new Son();
for(Father obj:objs)
{
//因为Son类抛出的实质是SQLException,而IOException无法处理它。
//那么这里的try。。catch就不能处理Son中的异常。
//多态就不能实现了。
try {
obj.start();
}catch(IOException)
{
//处理IOException
}
}
}
}
复制代码JAVA异常常见面试题
下面是我个人总结的在Java和J2EE开发者在面试中经常被问到的有关Exception和Error的知识。在分享我的回答的时候,我也给这些问题作了快速修订,并且提供源码以便深入理解。我总结了各种难度的问题,适合新手码农和高级Java码农。如果你遇到了我列表中没有的问题,并且这个问题非常好,请在下面评论中分享出来。你也可以在评论中分享你面试时答错的情况。
1) Java中什么是Exception?
这个问题经常在第一次问有关异常的时候或者是面试菜鸟的时候问。我从来没见过面高级或者资深工程师的时候有人问这玩意,但是对于菜鸟,是很愿意问这个的。
简单来说,异常是Java传达给你的系统和程序错误的方式。在java中,异常功能是通过实现比如Throwable,Exception,RuntimeException之类的类,然后还有一些处理异常时候的关键字,比如throw,throws,try,catch,finally之类的。 所有的异常都是通过Throwable衍生出来的。Throwable把错误进一步划分为 java.lang.Exception 和 java.lang.Error. java.lang.Error 用来处理系统错误,例如java.lang.StackOverFlowError 之类的。然后 Exception用来处理程序错误,请求的资源不可用等等。
2) Java中的检查型异常和非检查型异常有什么区别?
这又是一个非常流行的Java异常面试题,会出现在各种层次的Java面试中。
检查型异常和非检查型异常的主要区别在于其处理方式。检查型异常需要使用try, catch和finally关键字在编译期进行处理,否则会出现编译器会报错。对于非检查型异常则不需要这样做。Java中所有继承自java.lang.Exception类的异常都是检查型异常,所有继承自RuntimeException的异常都被称为非检查型异常。
3) Java中的NullPointerException和ArrayIndexOutOfBoundException之间有什么相同之处?
在Java异常面试中这并不是一个很流行的问题,但会出现在不同层次的初学者面试中,用来测试应聘者对检查型异常和非检查型异常的概念是否熟悉。顺便说一下,该题的答案是,
这两个异常都是非检查型异常,都继承自RuntimeException。该问题可能会引出另一个问题,即Java和C的数组有什么不同之处,因为C里面的数组是没有大小限制的,绝对不会抛出ArrayIndexOutOfBoundException。
4)在Java异常处理的过程中,你遵循的那些最好的实践是什么?
这个问题在面试技术经理是非常常见的一个问题。因为异常处理在项目设计中是非常关键的,所以精通异常处理是十分必要的。异常处理有很多最佳实践,下面列举集中,它们提高你代码的健壮性和灵活性:
- 调用方法的时候返回布尔值来代替返回null,这样可以 NullPointerException。由于空指针是java异常里最恶心的异常
- catch块里别不写代码。空catch块是异常处理里的错误事件,因为它只是捕获了异常,却没有任何处理或者提示。通常你起码要打印出异常信息,当然你最好根据需求对异常信息进行处理。
3)能抛受控异常(checked Exception)就尽量不抛受非控异常(checked Exception)。通过去掉重复的异常处理代码,可以提高代码的可读性。
- 绝对不要让你的数据库相关异常显示到客户端。由于绝大多数数据库和SQLException异常都是受控异常,在Java中,你应该在DAO层把异常信息处理,然后返回处理过的能让用户看懂并根据异常提示信息改正操作的异常信息。
- 在Java中,一定要在数据库连接,数据库查询,流处理后,在finally块中调用close()方法。
5) 既然我们可以用RuntimeException来处理错误,那么你认为为什么Java中还存在检查型异常?
这是一个有争议的问题,在回答该问题时你应当小心。虽然他们肯定愿意听到你的观点,但其实他们最感兴趣的还是有说服力的理由。我认为其中一个理由是,存在检查型异常是一个设计上的决定,受到了诸如C++等比Java更早编程语言设计经验的影响。绝大多数检查型异常位于java.io包内,这是合乎情理的,因为在你请求了不存在的系统资源的时候,一段强壮的程序必须能够优雅的处理这种情况。通过把IOException声明为检查型异常,Java 确保了你能够优雅的对异常进行处理。另一个可能的理由是,可以使用catch或finally来确保数量受限的系统资源(比如文件描述符)在你使用后尽早得到释放。 Joshua Bloch编写的 Effective Java 一书 中多处涉及到了该话题,值得一读。
6) throw 和 throws这两个关键字在java中有什么不同?
一个java初学者应该掌握的面试问题。 throw 和 throws乍看起来是很相似的尤其是在你还是一个java初学者的时候。尽管他们看起来相似,都是在处理异常时候使用到的。但在代码里的使用方法和用到的地方是不同的。throws总是出现在一个函数头中,用来标明该成员函数可能抛出的各种异常, 你也可以申明未检查的异常,但这不是编译器强制的。如果方法抛出了异常那么调用这个方法的时候就需要将这个异常处理。另一个关键字 throw 是用来抛出任意异常的,按照语法你可以抛出任意 Throwable (i.e. Throwable 或任何Throwable的衍生类) , throw可以中断程序运行,因此可以用来代替return . 最常见的例子是用 throw 在一个空方法中需要return的地方抛出
UnSupportedOperationException 代码如下 :
| 123 | private``static ````void show() {thrownew ``````UnsupportedOperationException("Notyet implemented"`);``} ``` |
|---|---|
可以看下这篇 文章查看这两个关键字在java中更多的差异 。
7) 什么是“异常链”?
“异常链”是Java中非常流行的异常处理概念,是指在进行一个异常处理时抛出了另外一个异常,由此产生了一个异常链条。该技术大多用于将“ 受检查异常” ( checked exception)封装成为“非受检查异常”(unchecked exception)或者RuntimeException。顺便说一下,如果因为因为异常你决定抛出一个新的异常,你一定要包含原有的异常,这样,处理程序才可以通过getCause()和initCause()方法来访问异常最终的根源。
8) 你曾经自定义实现过异常吗?怎么写的?
很显然,我们绝大多数都写过自定义或者业务异常,像AccountNotFoundException。在面试过程中询问这个Java异常问题的主要原因是去发现你如何使用这个特性的。这可以更准确和精致的去处理异常,当然这也跟你选择checked 还是unchecked exception息息相关。通过为每一个特定的情况创建一个特定的异常,你就为调用者更好的处理异常提供了更好的选择。相比通用异常(general exception),我更倾向更为精确的异常。大量的创建自定义异常会增加项目class的个数,因此,在自定义异常和通用异常之间维持一个平衡是成功的关键。
9) JDK7中对异常处理做了什么改变?
这是最近新出的Java异常处理的面试题。JDK7中对错误(Error)和异常(Exception)处理主要新增加了2个特性,一是在一个catch块中可以出来多个异常,就像原来用多个catch块一样。另一个是自动化资源管理(ARM), 也称为try-with-resource块。这2个特性都可以在处理异常时减少代码量,同时提高代码的可读性。对于这些特性了解,不仅帮助开发者写出更好的异常处理的代码,也让你在面试中显的更突出。我推荐大家读一下Java 7攻略,这样可以更深入的了解这2个非常有用的特性。
10) 你遇到过 OutOfMemoryError 错误嘛?你是怎么搞定的?
这个面试题会在面试高级程序员的时候用,面试官想知道你是怎么处理这个危险的OutOfMemoryError错误的。必须承认的是,不管你做什么项目,你都会碰到这个问题。所以你要是说没遇到过,面试官肯定不会买账。要是你对这个问题不熟悉,甚至就是没碰到过,而你又有3、4年的Java经验了,那么准备好处理这个问题吧。在回答这个问题的同时,你也可以借机向面试秀一下你处理内存泄露、调优和调试方面的牛逼技能。我发现掌握这些技术的人都能给面试官留下深刻的印象。
11) 如果执行finally代码块之前方法返回了结果,或者JVM退出了,finally块中的代码还会执行吗?
这个问题也可以换个方式问:“如果在try或者finally的代码块中调用了System.exit(),结果会是怎样”。了解finally块是怎么执行的,即使是try里面已经使用了return返回结果的情况,对了解Java的异常处理都非常有价值。只有在try里面是有System.exit(0)来退出JVM的情况下finally块中的代码才不会执行。
12)Java中final,finalize,finally关键字的区别
这是一个经典的Java面试题了。我的一个朋友为Morgan Stanley招电信方面的核心Java开发人员的时候就问过这个问题。final和finally是Java的关键字,而finalize则是方法。final关键字在创建不可变的类的时候非常有用,只是声明这个类是final的。而finalize()方法则是垃圾回收器在回收一个对象前调用,但也Java规范里面没有保证这个方法一定会被调用。finally关键字是唯一一个和这篇文章讨论到的异常处理相关的关键字。在你的产品代码中,在关闭连接和资源文件的是时候都必须要用到finally块。
集合
一、集合大纲
Connection 集合:
Map集合:
1. 集合和数组的区别
2. #### Connection集合的方法:
-
常用集合的分类:
Collection 接口的接口 对象的集合(单列集合)
——>>>List 接口:元素按进入先后有序保存,可重复 ——>>> LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全 ——>>> ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全 ——>>> Vector 接口实现类 数组, 同步, 线程安全 ——>>> Stack 是Vector类的实现类 ——>>> Set 接口: 仅接收一次,不可重复,并做内部排序 ——>>> └HashSet 使用hash表(数组)存储元素 ——>>> LinkedHashSet 链表维护元素的插入次序 ——>>> TreeSet 底层实现为二叉树,元素排好序
Map 接口 键值对的集合 (双列集合)
——>>> Hashtable 接口实现类, 同步, 线程安全 ——>>> HashMap 接口实现类 ,没有同步, 线程不安全- ——>>> LinkedHashMap 双向链表和哈希表实现 ——>>> WeakHashMap ——>>> TreeMap 红黑树对所有的key进行排序 ——>>> IdentifyHashMap
二、List和Set集合详解
1.list 和 set的区别:
2.List:
- ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
- LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
- Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
3.Set:
- HashSet底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。 具体实现唯一性的比较过程:存储元素首先会使用hash()算法函数生成一个int类型hashCode散列值,然后已经的所存储的元素的hashCode值比较,如果hashCode不相等,则所存储的两个对象一定不相等,此时存储当前的新的hashCode值处的元素对象;如果hashCode相等,存储元素的对象还是不一定相等,此时会调用equals()方法判断两个对象的内容是否相等,如果内容相等,那么就是同一个对象,无需存储;如果比较的内容不相等,那么就是不同的对象,就该存储了,此时就要采用哈希的解决地址冲突算法,在当前hashCode值处类似一个新的链表, 在同一个hashCode值的后面存储存储不同的对象,这样就保证了元素的唯一性。 Set的实现类的集合对象中不能够有重复元素,HashSet也一样他是使用了一种标识来确定元素的不重复,HashSet用一种算法来保证HashSet中的元素是不重复的, HashSet采用哈希算法,底层用数组存储数据。默认初始化容量16,加载因子0.75。 Object类中的hashCode()的方法是所有子类都会继承这个方法,这个方法会用Hash算法算出一个Hash(哈希)码值返回,HashSet会用Hash码值去和数组长度取模, 模(这个模就是对象要存放在数组中的位置)相同时才会判断数组中的元素和要加入的对象的内容是否相同,如果不同才会添加进去。
Hash算法是一种散列算法。 Set hs=new HashSet();
hs.add(o); | o.hashCode(); | o%当前总容量 (0–15) | | 不发生冲突 是否发生冲突—————–直接存放 | | 发生冲突 | 假(不相等) o1.equals(o2)——————-找一个空位添加 | | 是(相等)
不添加覆盖hashCode()方法的原则:
1、一定要让那些我们认为相同的对象返回相同的hashCode值
2、尽量让那些我们认为不同的对象返回不同的hashCode值,否则,就会增加冲突的概率。
3、尽量的让hashCode值散列开(两值用异或运算可使结果的范围更广) HashSet 的实现比较简单,相关HashSet的操作,基本上都是直接调用底层HashMap的相关方法来完成,我们应该为保存到HashSet中的对象覆盖hashCode()和equals(),因为再将对象加入到HashSet中时,会首先调用hashCode方法计算出对象的hash值,接着根据此hash值调用HashMap中的hash方法,得到的值& (length-1)得到该对象在hashMap的transient Entry[] table中的保存位置的索引,接着找到数组中该索引位置保存的对象,并调用equals方法比较这两个对象是否相等,如果相等则不添加,注意:所以要存入HashSet的集合对象中的自定义类必须覆盖hashCode(),equals()两个方法,才能保证集合中元素不重复。在覆盖equals()和hashCode()方法时, 要使相同对象的hashCode()方法返回相同值,覆盖equals()方法再判断其内容。为了保证效率,所以在覆盖hashCode()方法时, 也要尽量使不同对象尽量返回不同的Hash码值。
如果数组中的元素和要加入的对象的hashCode()返回了相同的Hash值(相同对象),才会用equals()方法来判断两个对象的内容是否相同。
-
LinkedHashSet底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。
-
TreeSet底层数据结构采用二叉树来实现,元素唯一且已经排好序;唯一性同样需要重写hashCode和equals()方法,二叉树结构保证了元素的有序性。根据构造方法不同,分为自然排序(无参构造)和比较器排序(有参构造),自然排序要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储;比较器排需要在TreeSet初始化是时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法;
-
小结:Set具有与Collection完全一样的接口,因此没有任何额外的功能,不像前面有两个不同的List。实际上Set就是Collection,只 是行为不同。(这是继承与多态思想的典型应用:表现不同的行为。)Set不保存重复的元素。 Set 存入Set的每个元素都必须是唯一的,因为Set不保存重复元素。加入Set的元素必须定义equals()方法以确保对象的唯一性。Set与Collection有完全一样的接口。Set接口不保证维护元素的次序。
4.List和Set总结:
-
List,Set都是继承自Collection接口,Map则不是
-
List特点:元素有放入顺序,元素可重复 ,Set特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的,加入Set 的Object必须定义equals()方法 ,另外list支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想要的值。)
-
.Set和List对比:
Set:
检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:
和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
-
ArrayList与LinkedList的区别和适用场景 Arraylist:
优点:ArrayList是实现了基于动态数组的数据结构,因为地址连续,一旦数据存储好了,查询操作效率会比较高(在内存里是连着放的)。
缺点:因为地址连续, ArrayList要移动数据,所以插入和删除操作效率比较低。
LinkedList:
优点:LinkedList基于链表的数据结构,地址是任意的,所以在开辟内存空间的时候不需要等一个连续的地址,对于新增和删除操作add和remove,LinedList比较占优势。LinkedList 适用于要头尾操作或插入指定位置的场景
缺点:
因为LinkedList要移动指针,所以查询操作性能比较低。
适用场景分析: 当需要对数据进行对此访问的情况下选用ArrayList,当需要对数据进行多次增加删除修改时采用LinkedList。
ArrayList与Vector的区别和适用场景
ArrayList有三个构造方法:
public ArrayList(int initialCapacity)//构造一个具有指定初始容量的空列表。
public ArrayList() //默认构造一个初始容量为10的空列表。
public ArrayList(Collection<? extends E> c)//构造一个包含指定 collection 的元素的列表
复制代码Vector有四个构造方法:
public Vector()//使用指定的初始容量和等于0的容量增量构造一个空向量。
public Vector(int initialCapacity)//构造一个空向量,使其内部数据数组的大小,其标准容量增量为零。
public Vector(Collection<? extends E> c)//构造一个包含指定 collection 中的元素的向量
public Vector(int initialCapacity,int capacityIncrement)//使用指定的初始容量和容量增量构造一个空的向量
复制代码ArrayList和Vector都是用数组实现的,主要有这么三个区别:
-
Vector是多线程安全的,线程安全就是说多线程访问同一代码,不会产生不确定的结果。而ArrayList不是,这个可以从源码中看出,Vector类中的方法很多有synchronized进行修饰,这样就导致了Vector在效率上无法与ArrayList相比;
-
两个都是采用的线性连续空间存储元素,但是当空间不足的时候,两个类的增加方式是不同。
-
Vector可以设置增长因子,而ArrayList不可以。
-
Vector是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
适用场景分析:
-
Vector是线程同步的,所以它也是线程安全的,而ArrayList是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用ArrayList效率比较高。
-
如果集合中的元素的数目大于目前集合数组的长度时,在集合中使用数据量比较大的数据,用Vector有一定的优势。
-
TreeSet 是二差树(红黑树的树据结构)实现的,Treeset中的数据是自动排好序的,不允许放入null值。
-
HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束
-
HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例
适用场景分析:
HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
5. 何时使用?
请看下面这个图具体分析
三、Map详解
Map用于保存具有映射关系的数据,Map里保存着两组数据:key和value,它们都可以使任何引用类型的数据,但key不能重复。所以通过指定的key就可以取出对应的value。
1. 注意事项:
Map 没有继承 Collection 接口, Map 提供 key 到 value 的映射,你可以通过“键”查找“值”。一个 Map 中不能包含相同的 key ,每个 key 只能映射一个 value 。 Map 接口提供 3 种集合的视图, Map 的内容可以被当作一组 key 集合,一组 value 集合,或者一组 key-value 映射。
复制代码2.Map:
3. HashMap和HashTable的比较:
4. TreeMap:
5. Map的其他类:
IdentityHashMap和HashMap的具体区别,IdentityHashMap使用 == 判断两个key是否相等,而HashMap使用的是equals方法比较key值。有什么区别呢?
对于==,如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等; 如果作用于引用类型的变量,则比较的是所指向的对象的地址。 对于equals方法,注意:equals方法不能作用于基本数据类型的变量 如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址; 诸如String、Date等类对equals方法进行了重写的话,比较的是所指向的对象的内容。
6. 小结:
HashMap 非线程安全 HashMap:基于哈希表实现。使用HashMap要求添加的键类明确定义了hashCode()和equals()[可以重写hashCode()和equals()],为了优化HashMap空间的使用,您可以调优初始容量和负载因子。
TreeMap:非线程安全基于红黑树实现。TreeMap没有调优选项,因为该树总处于平衡状态。
适用场景分析:
复制代码HashMap和HashTable:HashMap去掉了HashTable的contains方法,但是加上了containsValue()和containsKey()方法。HashTable同步的,而HashMap是非同步的,效率上比HashTable要高。HashMap允许空键值,而HashTable不允许。
HashMap:适用于Map中插入、删除和定位元素。 Treemap:适用于按自然顺序或自定义顺序遍历键(key)。
7. 其他小结:
线程安全集合类与非线程安全集合类
LinkedList、ArrayList、HashSet是非线程安全的,Vector是线程安全的; HashMap是非线程安全的,HashTable是线程安全的; StringBuilder是非线程安全的,StringBuffer是线程安全的。
数据结构
ArrayXxx:底层数据结构是数组,查询快,增删慢 LinkedXxx:底层数据结构是链表,查询慢,增删快 HashXxx:底层数据结构是哈希表。依赖两个方法:hashCode()和equals() TreeXxx:底层数据结构是二叉树。两种方式排序:自然排序和比较器排序
JavaIO流
一、初始IO流
IO,即in和out,也就是输入和输出,指应用程序和外部设备之间的数据传递,常见的外部设备包括文件、管道、网络连接。
Java 中是通过流处理IO 的,那么什么是流?
流(Stream),是一个抽象的概念,是指一连串的数据(字符或字节),是以先进先出的方式发送信息的通道。
当程序需要读取数据的时候,就会开启一个通向数据源的流,这个数据源可以是文件,内存,或是网络连接。类似的,当程序需要写入数据的时候,就会开启一个通向目的地的流。这时候你就可以想象数据好像在这其中“流”动一样。
一般来说关于流的特性有下面几点:
-
先进先出:最先写入输出流的数据最先被输入流读取到。
-
顺序存取:可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。(RandomAccessFile除外)
-
只读或只写:每个流只能是输入流或输出流的一种,不能同时具备两个功能,输入流只能进行读操作,对输出流只能进行写操作。在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
IO流分类
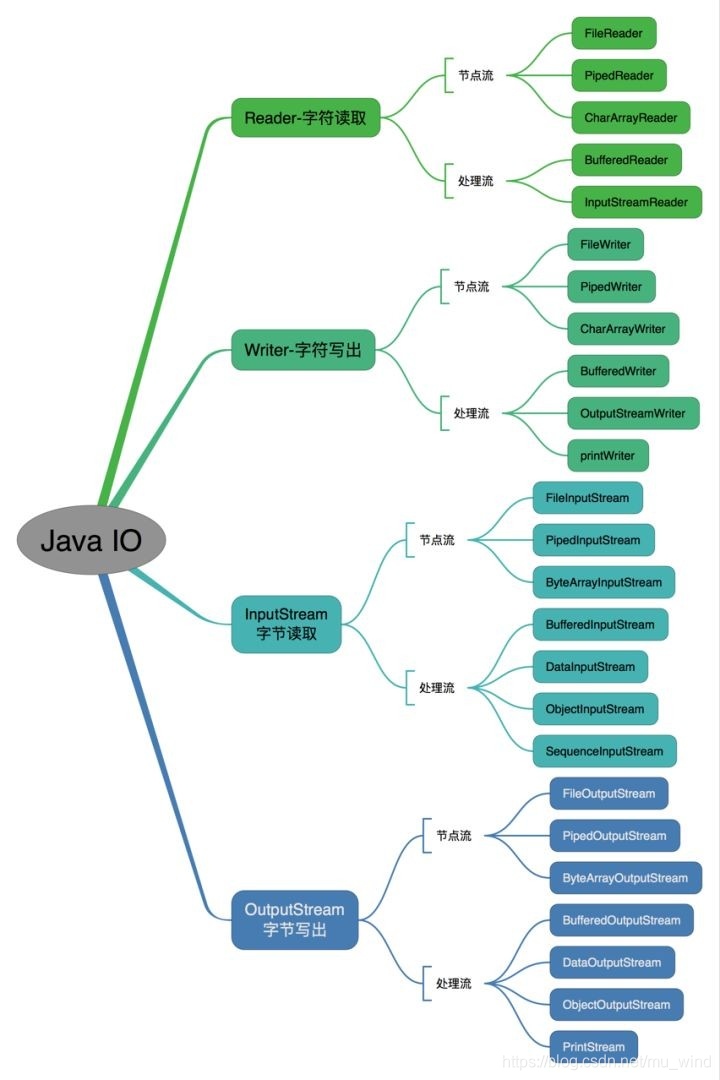
IO流主要的分类方式有以下3种:
-
按数据流的方向:输入流、输出流
-
按处理数据单位:字节流、字符流
-
按功能:节点流、处理流
1. 输入输出流
输入与输出是相对于程序而言的,比如文件的读写,读取文件就是输入流 ;写文件就是输出流,这点很容易记混!
2. 字节流与字符流
字节流和字符流的用法几乎一样,区别于字节流和字符流的所操作的数据单元不一样,字节流操作的数据单元是8位的字节,而字符流操作的数据单元是16位的字符
为什么要有字符流?
Java中字符是采用Unicode标准,Unicode 编码中,一个英文字母或一个中文汉字为两个字节。
而在UTF-8编码中,一个中文字符是3个字节。例如下面图中,“云深不知处”5个中文对应的是15个字节:-28-70-111-26-73-79-28-72-115-25-97-91-27-92-124
那么问题来了,如果使用字节流处理中文,如果一次读写一个字符对应的字节数就不会有问题,一旦将一个字符对应的字节分裂开来,就会出现乱码了。为了更方便地处理中文这些字符,Java就推出了字符流。
字节流和字符流的其他区别:
-
字节流一般用来处理图像、视频、音频、PPT、Word等类型的文件。字符流一般用于处理纯文本类型的文件,如TXT文件等,但不能处理图像视频等非文本文件。用一句话说就是:字节流可以处理一切文件,而字符流只能处理纯文本文件。
-
字节流本身没有缓冲区,缓冲字节流相对于字节流,效率提升非常高。而字符流本身就带有缓冲区,缓冲字符流相对于字符流效率提升就不是那么大了。详见文末效率对比。
以写文件为例,我们查看字符流的源码,发现确实有利用到缓冲区:
3、节点流和处理流
节点流:直接操作数据读写的流类,比如FileInputStream
处理流(也叫包装流):对一个已存在的流的链接和封装,通过对数据进行处理为程序提供功能强大、灵活的读写功能,例如BufferedInputStream(缓冲字节流)
处理流和节点流应用了Java的装饰者设计模式。
下图就很形象地描绘了节点流和处理流,处理流是对节点流的封装,最终的数据处理 还是由节点流完成的。
在诸多处理流中,有一个非常重要,那就是缓冲流。
复制代码我们知道,程序与磁盘的交互相对于内存运算是很慢的,容易成为程序的性能瓶颈。减少程序与磁盘的交互,是提升程序效率一种有效手段。缓冲流,就应用这种思路:普通流每次读写一个字节,而缓冲流在内存中设置一个缓存区,缓冲区先存储足够的待操作数据后,再与内存或磁盘进行交互。这样,在总数据量不变的情况下,通过提高每次交互的数据量,减少了交互次数。
联想一下生活中的例子,我们搬砖的时候,一块一块地往车上装肯定是很低效的。我们可以使用一个小推车,先把砖装到小推车上,再把这小推车推到车前,把砖装到车上。这个例子中,小推车可以视为缓冲区,小推车的存在,减少了我们装车次数,从而提高了效率。
需要注意的是,缓冲流效率一定高吗?不一定,某些情形下,缓冲流效率反而更低,具体请见IO流效率对比。
完整的IO分类图如下:
案例实操
接下来,我们看看如何使用Java IO。
文本读写的例子,也就是文章开头所说的,将“松下问童子,言师采药去。只在此山中,云深不知处。”写入本地文本,然后再从文件读取内容并输出到控制台。
1、FileInputStream、FileOutputStream(字节流)
字节流的方式效率较低,不建议使用
public class IOTest {
public static void main(String[] args) throws IOException {
File file = new File("D:/test.txt");
write(file);
System.out.println(read(file));
}
public static void write(File file) throws IOException {
OutputStream os = new FileOutputStream(file, true);
// 要写入的字符串
String string = "松下问童子,言师采药去。只在此山中,云深不知处。";
// 写入文件
os.write(string.getBytes());
// 关闭流
os.close();
}
public static String read(File file) throws IOException {
InputStream in = new FileInputStream(file);
// 一次性取多少个字节
byte[] bytes = new byte[1024];
// 用来接收读取的字节数组
StringBuilder sb = new StringBuilder();
// 读取到的字节数组长度,为-1时表示没有数据
int length = 0;
// 循环取数据
while ((length = in.read(bytes)) != -1) {
// 将读取的内容转换成字符串
sb.append(new String(bytes, 0, length));
}
// 关闭流
in.close();
return sb.toString();
}
}
复制代码2、BufferedInputStream、BufferedOutputStream(缓冲字节流)
缓冲字节流是为高效率而设计的,真正的读写操作还是靠
FileOutputStream和FileInputStream,所以其构造方法入参是这两个类的对象也就不奇怪了。
public class IOTest {
public static void write(File file) throws IOException {
// 缓冲字节流,提高了效率
BufferedOutputStream bis = new BufferedOutputStream(new FileOutputStream(file, true));
// 要写入的字符串
String string = "松下问童子,言师采药去。只在此山中,云深不知处。";
// 写入文件
bis.write(string.getBytes());
// 关闭流
bis.close();
}
public static String read(File file) throws IOException {
BufferedInputStream fis = new BufferedInputStream(new FileInputStream(file));
// 一次性取多少个字节
byte[] bytes = new byte[1024];
// 用来接收读取的字节数组
StringBuilder sb = new StringBuilder();
// 读取到的字节数组长度,为-1时表示没有数据
int length = 0;
// 循环取数据
while ((length = fis.read(bytes)) != -1) {
// 将读取的内容转换成字符串
sb.append(new String(bytes, 0, length));
}
// 关闭流
fis.close();
return sb.toString();
}
}
复制代码3、InputStreamReader、OutputStreamWriter(字符流)
字符流适用于文本文件的读写,
OutputStreamWriter类其实也是借助FileOutputStream类实现的,故其构造方法是FileOutputStream的对象
public class IOTest {
public static void write(File file) throws IOException {
// OutputStreamWriter可以显示指定字符集,否则使用默认字符集
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(file, true), "UTF-8");
// 要写入的字符串
String string = "松下问童子,言师采药去。只在此山中,云深不知处。";
osw.write(string);
osw.close();
}
public static String read(File file) throws IOException {
InputStreamReader isr = new InputStreamReader(new FileInputStream(file), "UTF-8");
// 字符数组:一次读取多少个字符
char[] chars = new char[1024];
// 每次读取的字符数组先append到StringBuilder中
StringBuilder sb = new StringBuilder();
// 读取到的字符数组长度,为-1时表示没有数据
int length;
// 循环取数据
while ((length = isr.read(chars)) != -1) {
// 将读取的内容转换成字符串
sb.append(chars, 0, length);
}
// 关闭流
isr.close();
return sb.toString()
}
}
复制代码4、字符流便捷类
Java提供了
FileWriter和FileReader简化字符流的读写,new FileWriter等同于new OutputStreamWriter(new FileOutputStream(file, true))
public class IOTest {
public static void write(File file) throws IOException {
FileWriter fw = new FileWriter(file, true);
// 要写入的字符串
String string = "松下问童子,言师采药去。只在此山中,云深不知处。";
fw.write(string);
fw.close();
}
public static String read(File file) throws IOException {
FileReader fr = new FileReader(file);
// 一次性取多少个字节
char[] chars = new char[1024];
// 用来接收读取的字节数组
StringBuilder sb = new StringBuilder();
// 读取到的字节数组长度,为-1时表示没有数据
int length;
// 循环取数据
while ((length = fr.read(chars)) != -1) {
// 将读取的内容转换成字符串
sb.append(chars, 0, length);
}
// 关闭流
fr.close();
return sb.toString();
}
}
复制代码5、BufferedReader、BufferedWriter(字符缓冲流)
public class IOTest {
public static void write(File file) throws IOException {
// BufferedWriter fw = new BufferedWriter(new OutputStreamWriter(new
// FileOutputStream(file, true), "UTF-8"));
// FileWriter可以大幅度简化代码
BufferedWriter bw = new BufferedWriter(new FileWriter(file, true));
// 要写入的字符串
String string = "松下问童子,言师采药去。只在此山中,云深不知处。";
bw.write(string);
bw.close();
}
public static String read(File file) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(file));
// 用来接收读取的字节数组
StringBuilder sb = new StringBuilder();
// 按行读数据
String line;
// 循环取数据
while ((line = br.readLine()) != null) {
// 将读取的内容转换成字符串
sb.append(line);
}
// 关闭流
br.close();
return sb.toString();
}
}
复制代码二、IO流对象
第一节中,我们大致了解了IO,并完成了几个案例,但对IO还缺乏更详细的认知,那么接下来我们就对Java IO细细分解,梳理出完整的知识体系来。
Java种提供了40多个类,我们只需要详细了解一下其中比较重要的就可以满足日常应用了。
File类
File类是用来操作文件的类,但它不能操作文件中的数据。
public class File extends Object implements Serializable, Comparable<File>
复制代码File类实现了Serializable、 Comparable<File>,说明它是支持序列化和排序的。
File类的构造方法
| 方法名 | 说明 |
|---|---|
| File(File parent, String child) | 根据 parent 抽象路径名和 child 路径名字符串创建一个新 File 实例。 |
| File(String pathname) | 通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例。 |
| File(String parent, String child) | 根据 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例。 |
| File(URI uri) | 通过将给定的 file: URI 转换为一个抽象路径名来创建一个新的 File 实例。 |
File类的常用方法
| 方法 | 说明 |
|---|---|
| createNewFile() | 当且仅当不存在具有此抽象路径名指定名称的文件时,不可分地创建一个新的空文件。 |
| delete() | 删除此抽象路径名表示的文件或目录。 |
| exists() | 测试此抽象路径名表示的文件或目录是否存在。 |
| getAbsoluteFile() | 返回此抽象路径名的绝对路径名形式。 |
| getAbsolutePath() | 返回此抽象路径名的绝对路径名字符串。 |
| length() | 返回由此抽象路径名表示的文件的长度。 |
| mkdir() | 创建此抽象路径名指定的目录。 |
File类使用实例
public class FileTest {
public static void main(String[] args) throws IOException {
File file = new File("C:/Mu/fileTest.txt");
// 判断文件是否存在
if (!file.exists()) {
// 不存在则创建
file.createNewFile();
}
System.out.println("文件的绝对路径:" + file.getAbsolutePath());
System.out.println("文件的大小:" + file.length());
// 刪除文件
file.delete();
}
}
复制代码字节流
InputStream与OutputStream是两个抽象类,是字节流的基类,所有具体的字节流实现类都是分别继承了这两个类。
以InputStream为例,它继承了Object,实现了Closeable
public abstract class InputStream
extends Object
implements Closeable
复制代码InputStream类有很多的实现子类,下面列举了一些比较常用的:
详细说明一下上图中的类:
-
InputStream:InputStream是所有字节输入流的抽象基类,前面说过抽象类不能被实例化,实际上是作为模板而存在的,为所有实现类定义了处理输入流的方法。
-
FileInputSream:文件输入流,一个非常重要的字节输入流,用于对文件进行读取操作。
-
PipedInputStream:管道字节输入流,能实现多线程间的管道通信
-
ByteArrayInputStream:字节数组输入流,从字节数组(byte[])中进行以字节为单位的读取,也就是将资源文件都以字节的形式存入到该类中的字节数组中去。
-
FilterInputStream:装饰者类,具体的装饰者继承该类,这些类都是处理类,作用是对节点类进行封装,实现一些特殊功能。
-
DataInputStream:数据输入流,它是用来装饰其它输入流,作用是“允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型”。
-
BufferedInputStream:缓冲流,对节点流进行装饰,内部会有一个缓存区,用来存放字节,每次都是将缓存区存满然后发送,而不是一个字节或两个字节这样发送,效率更高。
-
ObjectInputStream:对象输入流,用来提供对基本数据或对象的持久存储。通俗点说,也就是能直接传输对象,通常应用在反序列化中。它也是一种处理流,构造器的入参是一个InputStream的实例对象。
OutputStream类继承关系图:
OutputStream类继承关系与InputStream类似,需要注意的是PrintStream.
字符流
与字节流类似,字符流也有两个抽象基类,分别是Reader和Writer。其他的字符流实现类都是继承了这两个类。
以Reader为例,它的主要实现子类如下图:
各个类的详细说明:
-
InputStreamReader:从字节流到字符流的桥梁(InputStreamReader构造器入参是FileInputStream的实例对象),它读取字节并使用指定的字符集将其解码为字符。它使用的字符集可以通过名称指定,也可以显式给定,或者可以接受平台的默认字符集。
-
BufferedReader:从字符输入流中读取文本,设置一个缓冲区来提高效率。BufferedReader是对InputStreamReader的封装,前者构造器的入参就是后者的一个实例对象。
-
FileReader:用于读取字符文件的便利类,new FileReader(File file)等同于new InputStreamReader(new FileInputStream(file, true),"UTF-8"),但FileReader不能指定字符编码和默认字节缓冲区大小。
-
PipedReader :管道字符输入流。实现多线程间的管道通信。
-
CharArrayReader:从Char数组中读取数据的介质流。
-
StringReader :从String中读取数据的介质流。
Writer与Reader结构类似,方向相反,不再赘述。唯一有区别的是,Writer的子类PrintWriter。
序列化
待续
IO流方法
字节流方法
字节输入流InputStream主要方法:
-
read() :从此输入流中读取一个数据字节。
-
read(byte[] b) :从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中。
-
read(byte[] b, int off, int len) :从此输入流中将最多 len 个字节的数据读入一个 byte 数组中。
-
close():关闭此输入流并释放与该流关联的所有系统资源。
字节输出流OutputStream主要方法:
-
write(byte[] b) :将 b.length 个字节从指定 byte 数组写入此文件输出流中。
-
write(byte[] b, int off, int len) :将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此文件输出流。
-
write(int b) :将指定字节写入此文件输出流。
-
close() :关闭此输入流并释放与该流关联的所有系统资源。
字符流方法
字符输入流Reader主要方法:
-
read():读取单个字符。
-
read(char[] cbuf) :将字符读入数组。
-
read(char[] cbuf, int off, int len) : 将字符读入数组的某一部分。
-
read(CharBuffer target) :试图将字符读入指定的字符缓冲区。
-
flush() :刷新该流的缓冲。
-
close() :关闭此流,但要先刷新它。
字符输出流Writer主要方法:
-
write(char[] cbuf) :写入字符数组。
-
write(char[] cbuf, int off, int len) :写入字符数组的某一部分。
-
write(int c) :写入单个字符。
-
write(String str) :写入字符串。
-
write(String str, int off, int len) :写入字符串的某一部分。
-
flush() :刷新该流的缓冲。
-
close() :关闭此流,但要先刷新它。
另外,字符缓冲流还有两个独特的方法:
BufferedWriter类newLine():写入一个行分隔符。这个方法会自动适配所在系统的行分隔符。BufferedReader类readLine():读取一个文本行。
附加内容
位、字节、字符
字节(Byte)是计量单位,表示数据量多少,是计算机信息技术用于计量存储容量的一种计量单位,通常情况下一字节等于八位。
字符(Character)计算机中使用的字母、数字、字和符号,比如’A’、‘B’、’$’、’&'等。
一般在英文状态下一个字母或字符占用一个字节,一个汉字用两个字节表示。
字节与字符:
-
ASCII 码中,一个英文字母(不分大小写)为一个字节,一个中文汉字为两个字节。
-
UTF-8 编码中,一个英文字为一个字节,一个中文为三个字节。
-
Unicode 编码中,一个英文为一个字节,一个中文为两个字节。
-
符号:英文标点为一个字节,中文标点为两个字节。例如:英文句号 . 占1个字节的大小,中文句号 。占2个字节的大小。
-
UTF-16 编码中,一个英文字母字符或一个汉字字符存储都需要 2 个字节(Unicode 扩展区的一些汉字存储需要 4 个字节)。
-
UTF-32 编码中,世界上任何字符的存储都需要 4 个字节。
IO流效率相比
public class MyTest { public static void main(String[] args) throws IOException { File file = new File("C:/Mu/test.txt"); StringBuilder sb = new StringBuilder(); for (int i = 0; i < 3000000; i++) { sb.append("abcdefghigklmnopqrstuvwsyz"); } byte[] bytes = sb.toString().getBytes(); long start = System.currentTimeMillis(); write(file, bytes); long end = System.currentTimeMillis(); long start2 = System.currentTimeMillis(); bufferedWrite(file, bytes); long end2 = System.currentTimeMillis(); System.out.println("普通字节流耗时:" + (end - start) + " ms"); System.out.println("缓冲字节流耗时:" + (end2 - start2) + " ms"); } // 普通字节流 public static void write(File file, byte[] bytes) throws IOException { OutputStream os = new FileOutputStream(file); os.write(bytes); os.close(); } // 缓冲字节流 public static void bufferedWrite(File file, byte[] bytes) throws IOException { BufferedOutputStream bo = new BufferedOutputStream(new FileOutputStream(file)); bo.write(bytes); bo.close(); } } 复制代码运行结果:
普通字节流耗时:250 ms 缓冲字节流耗时:268 ms 复制代码这个结果让我大跌眼镜,不是说好缓冲流效率很高么?要知道为什么,只能去源码里找答案了。翻看字节缓冲流的
write方法:public synchronized void write(byte b[], int off, int len) throws IOException { if (len >= buf.length) { /* If the request length exceeds the size of the output buffer, flush the output buffer and then write the data directly. In this way buffered streams will cascade harmlessly. */ flushBuffer(); out.write(b, off, len); return; } if (len > buf.length - count) { flushBuffer(); } System.arraycopy(b, off, buf, count, len); count += len; } 复制代码注释里说得很明白:如果请求长度超过输出缓冲区的大小,刷新输出缓冲区,然后直接写入数据。这样,缓冲流将无害地级联。
但是,至于为什么这么设计,我没有想明白,有哪位明白的大佬可以留言指点一下。
基于上面的情形,要想对比普通字节流和缓冲字节流的效率差距,就要避免直接读写较长的字符串,于是,设计了下面这个对比案例:用字节流和缓冲字节流分别复制文件。
public class MyTest {
public static void main(String[] args) throws IOException {
File data = new File("C:/Mu/data.zip");
File a = new File("C:/Mu/a.zip");
File b = new File("C:/Mu/b.zip");
StringBuilder sb = new StringBuilder();
long start = System.currentTimeMillis();
copy(data, a);
long end = System.currentTimeMillis();
long start2 = System.currentTimeMillis();
bufferedCopy(data, b);
long end2 = System.currentTimeMillis();
System.out.println("普通字节流耗时:" + (end - start) + " ms");
System.out.println("缓冲字节流耗时:" + (end2 - start2) + " ms");
}
// 普通字节流
public static void copy(File in, File out) throws IOException {
// 封装数据源
InputStream is = new FileInputStream(in);
// 封装目的地
OutputStream os = new FileOutputStream(out);
int by = 0;
while ((by = is.read()) != -1) {
os.write(by);
}
is.close();
os.close();
}
// 缓冲字节流
public static void bufferedCopy(File in, File out) throws IOException {
// 封装数据源
BufferedInputStream bi = new BufferedInputStream(new FileInputStream(in));
// 封装目的地
BufferedOutputStream bo = new BufferedOutputStream(new FileOutputStream(out));
int by = 0;
while ((by = bi.read()) != -1) {
bo.write(by);
}
bo.close();
bi.close();
}
}
复制代码运行结果:
普通字节流耗时:184867 ms
缓冲字节流耗时:752 ms
复制代码这次,普通字节流和缓冲字节流的效率差异就很明显了,达到了245倍。
再看看字符流和缓冲字符流的效率对比:
public class IOTest {
public static void main(String[] args) throws IOException {
// 数据准备
dataReady();
File data = new File("C:/Mu/data.txt");
File a = new File("C:/Mu/a.txt");
File b = new File("C:/Mu/b.txt");
File c = new File("C:/Mu/c.txt");
long start = System.currentTimeMillis();
copy(data, a);
long end = System.currentTimeMillis();
long start2 = System.currentTimeMillis();
copyChars(data, b);
long end2 = System.currentTimeMillis();
long start3 = System.currentTimeMillis();
bufferedCopy(data, c);
long end3 = System.currentTimeMillis();
System.out.println("普通字节流1耗时:" + (end - start) + " ms,文件大小:" + a.length() / 1024 + " kb");
System.out.println("普通字节流2耗时:" + (end2 - start2) + " ms,文件大小:" + b.length() / 1024 + " kb");
System.out.println("缓冲字节流耗时:" + (end3 - start3) + " ms,文件大小:" + c.length() / 1024 + " kb");
}
// 普通字符流不使用数组
public static void copy(File in, File out) throws IOException {
Reader reader = new FileReader(in);
Writer writer = new FileWriter(out);
int ch = 0;
while ((ch = reader.read()) != -1) {
writer.write((char) ch);
}
reader.close();
writer.close();
}
// 普通字符流使用字符流
public static void copyChars(File in, File out) throws IOException {
Reader reader = new FileReader(in);
Writer writer = new FileWriter(out);
char[] chs = new char[1024];
while ((reader.read(chs)) != -1) {
writer.write(chs);
}
reader.close();
writer.close();
}
// 缓冲字符流
public static void bufferedCopy(File in, File out) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(in));
BufferedWriter bw = new BufferedWriter(new FileWriter(out));
String line = null;
while ((line = br.readLine()) != null) {
bw.write(line);
bw.newLine();
bw.flush();
}
// 释放资源
bw.close();
br.close();
}
// 数据准备
public static void dataReady() throws IOException {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 600000; i++) {
sb.append("abcdefghijklmnopqrstuvwxyz");
}
OutputStream os = new FileOutputStream(new File("C:/Mu/data.txt"));
os.write(sb.toString().getBytes());
os.close();
System.out.println("完毕");
}
}
复制代码运行结果:
普通字符流1耗时:1337 ms,文件大小:15234 kb
普通字符流2耗时:82 ms,文件大小:15235 kb
缓冲字符流耗时:205 ms,文件大小:15234 kb
复制代码测试多次,结果差不多,可见字符缓冲流效率上并没有明显提高,我们更多的是要使用它的readLine()和newLine()方法。