TTS(Text-To-Speech)是指文本语音的简称,即通过TTS引擎把文本转化为语音输出。TTS语音引擎有微软TTS语音引擎、科大讯飞语音引擎等。科大讯飞tts sdk参考这个页面http://www.xfyun.cn/sdk/dispatcher
文本主要介绍如何使用微软TTS语音引擎实现文本朗读,以及生成wav格式的声音文件。
1、语音引擎及语音库的安装
微软TTS语音引擎提供了Windows Speech SDK开发包供编程者使用。Windows Speech SDK包含语音合成SS引擎和语音识别SR引擎两种,语音合成引擎用于将文字转换成语音输出,语音识别引擎用于识别语音命令。
Windows Speech SDK可以在微软的官网上免费下载,下载地址为:http://www.microsoft.com/download/en/details.aspx?id=10121
在该下载界面中,选择下载SpeechSDK51.exe、SpeechSDK51LangPach.exe和sapi.chm 即可。
| SpeechSDK51.exe |
语音合成引擎 |
| SpeechSDK51LangPach.exe |
语音库,支持日语和简体中文需要这个支持。 |
| sapi.chm |
帮助文档 |
| speechsdk51MSM.exe |
语音引擎集成到你的产品跟产品一起发布。解压出来三个文件夹1033、1041和2052。其中,1033下主要是用于英文的TTS和SR的.msm文件,1041下主要是用于日文SR的.msm文件,2052下是用于中文TTS和SR的msm文件。 |
| Sp5TTintXP.exe |
XP下Mike和Mary语音。 |
下载完成后,先安装语音引擎SpeechSDK51.exe,再安装中文语音库SpeechSDK51LangPach.exe。
目前最常用的Windows Speech SDK版本有三种:5.1、5.3和5.4。
Windows Speech SDK 5.1版本支持xp系统和server 2003系统,需要下载安装。XP系统默认只带了个Microsoft Sam英文男声语音库,想要中文引擎就需要安装Windows Speech SDK 5.1。
Windows Speech SDK 5.3版本支持Vista系统和Server 2008系统,已经集成到系统里。Vista和Server 2003默认带Microsoft lili中文女声语音库和Microsoft Anna英文女声语音库。
Windows Speech SDK 5.4版本支持Windows7系统,也已经集成到系统里,不需要下载安装。Win7系统同样带了Microsoft lili中文女声语音库和Microsoft Anna英文女声语音库。Microsoft lili支持中英文混读。
2、SAPI接口的使用说明1)、基本朗读过程的实现
在使用语音引擎之前进行初始化:
ISpVoice *pSpVoice; // 重要COM接口 ::CoInitialize(NULL); // COM初始化 // 获取ISpVoice接口 CoCreateInstance(CLSID_SpVoice, NULL, CLSCTX_INPROC_SERVER, IID_ISpVoice, (void**)&pSpVoice);
获取到ISpVoice接口以后,我们就可以通过pSpVoice指针调用SAPI接口了。
我们可以设置音量:pSpVoice->SetVolume(80);。SetVolume的参数即音量的范围在0到100之间。
可以这样朗读字符串内容:pSpVoice->Speak(string, SPF_DEFAULT, NULL);。这样string里的内容就会被朗读出来了,第二个参数SPF_DEFAULT表示使用默认设置,包括同步朗读的设置。异步朗读可以设置成 SPF_ASYNC。同步朗读表示读完string中的内容,speak函数才会返回,而异步朗读则将字符串送进去就返回,不会阻塞。
使用完语音引擎后应执行:
pSpVoice->Release(); ::CoUninitialize();
这样资源被释放,语音朗读过程结束。
以上就完成了一个简单的语音合成朗读的功能。
2)、ISpVoice的成员函数
鸡啄米再简单说明几个ISpVoice接口的成员函数:
HRESULT Speak(LPCWSTR *pwcs, DWORD dwFlags, ULONG *pulStreamNumber);
用于读取字符串pwcs里的内容。参数pwcs为要朗读的字符串。dwFlags是用于控制朗读方式的标志,具体意义可以查看文档中的枚举 SPEAKFLAGS。pulStreamNumber为输出参数,它指向本次朗读请求对应的当前输入流编号,每次朗读一个字符串时都会有一个流编号返 回,异步朗读时使用。
HRESULT SetRate( long RateAdjust); // 设置朗读速度,取值范围:-10到10 HRESULT GetRate(long *pRateAdjust); // 获取朗读速度 HRESULT SetVoice(ISpObjectToken *pToken); // 设置使用的语音库 HRESULT GetVoice(ISpObjectToken** ppToken); // 获取语音库 HRESULT Pause ( void ); // 暂停朗读 HRESULT Resume ( void ); // 恢复朗读 // 在当前朗读文本中根据lNumItems的符号向前或者向后跳过指定数量(lNumItems的绝对值)的句子。 HRESULT Skip(LPCWSTR *pItemType, long lNumItems, ULONG *pulNumSkipped); // 播放WAV文件 HRESULT SpeakStream(IStream *pStream, DWORD dwFlags, ULONG *pulStreamNumber); // 将声音输出到WAV文件 HRESULT SetOutput(IUnknown *pUnkOutput,BOOL fAllowFormatChanges); HRESULT SetVolume(USHORT usVolume); // 设置音量,范围:0到100 HRESULT GetVolume(USHORT *pusVolume); // 获取音量 HRESULT SetSyncSpeakTimeout(ULONG msTimeout); // 设置同步朗读超时时间,单位为毫秒 HRESULT GetSyncSpeakTimeout(ULONG *pmsTimeout); // 获取同步朗读超时时间
因为在同步朗读时,speak函数是阻塞的,如果语音输出设备被其他程序占用,则speak则会一直等待,所以最好设置好超时时间,超时后speak函数自行返回。
3)、使用XML朗读
在进行TTS开发时可以使用XML,SAPI可以分析XML标签,通过XML能够实现一些ISpVoice的成员函数的功能。比如设置语音库、音量、语速等。此时speak函数的dwFlags参数要设置为包含SPF_IS_XML。如:
// 选择语音库Microsoft Sam pSpVoice->speak(L"<VOICE REQUIRED='NAME=Microsoft Sam'/>鸡啄米", SPF_DEFAULT | SPF_IS_XML, NULL); // 设置音量 <VOLUME LEVEL='90'>鸡啄米</VOLUME> // 设置语言 <lang langid='804'>鸡啄米</lang>
804代表中文,409代表英文。如果用函数SpGetLanguageFromToken获取语言时,0x804表示中文,0x409表示英文。
4)、设置SAPI通知消息。
SAPI在朗读的过程中,会给指定窗口发送消息,窗口收到消息后,可以主动获取SAPI的事件,根据事件的不同,用户可以得到当前SAPI的一些信息,比如正在朗读的单词的位置,当前的朗读口型值(用于显示动画口型,中文语音的情况下并不提供这个事件)等等。要获取SAPI的通知,首先要注册一个消息:
m_cpVoice->SetNotifyWindowMessage( hWnd,WM_TTSAPPCUSTOMEVENT, 0, 0 );
这个代码一般是在主窗口初始化的时候调用,hWnd是主窗口(或者接收消息的窗口)句柄。WM_TTSAPPCUSTOMEVENT是用户自定义消息。在窗口响应WM_TTSAPPCUSTOMEVENT消息的函数中,通过如下代码获取sapi的通知事件:
CSpEvent event; // 使用这个类,比用 SPEVENT结构更方便
while(event.GetFrom(m_cpVoice) == S_OK )
{
switch( event.eEventId )
{
...
}
}
eEventID有很多种,比如SPEI_START_INPUT_STREAM表示开始朗读,SPEI_END_INPUT_STREAM表示朗读结束等。
可以根据需要进行判断使用。
5)、speech sdk语音识别,识别语音生成英文/中文等字符串。
具体参考这篇文章:http://blog.csdn.net/artemisrj/article/details/8723095
3、编程实例
1)、首先将需要将Windows Speech SDK开发包的头文件和库文件所在路径添加到编译器中。
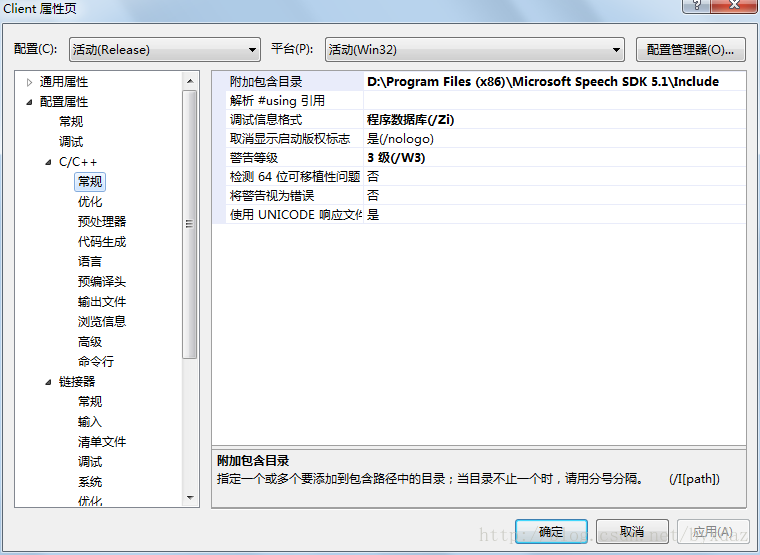

2)、封装tts操作类。
//TextToSpeech.h文件
//tts
#pragma once
#include <sapi.h> //包含TTS语音引擎头文件和库文件
#include <sphelper.h>
#include <string.h>
#pragma comment(lib, "sapi.lib")
class TextToSpeech
{
public:
TextToSpeech(void);
virtual ~TextToSpeech(void);
int Init();
int UnInit();
//枚举所有语音Token
int EnumAudioToken(CString arrayVoicePackageName[],int nVoicePackageNameCount);
//创建SpVoice
int CreateSpVoice();
//释放SpVoice
int DeleteSpVoice();
//重置SpVoice(用于临时清除朗读数据)
int ResetSpVoice();
//设置朗读速度(取值范围:-10到10)
int SetRate( long RateAdjust);
//获取朗读速度
int GetRate(long *pRateAdjust);
//设置使用的语音库
int SetVoice(ISpObjectToken *pToken);
//获取语音库
int GetVoice(unsigned int nIndex,ISpObjectToken** ppToken);
//设置音量(取值范围:0到100)
int SetVolume(USHORT usVolume);
//获取音量
int GetVolume(USHORT *pusVolume);
//朗读
int Speak(CString strContent,DWORD dwFlags=SPF_DEFAULT);
//朗读生成文件
int SpeakToWaveFile(CString strContent,char *pFilePathName,DWORD dwFlags=SPF_DEFAULT);
//暂停朗读
int Pause();
//继续朗读
int Resume();
//跳过部分朗读
int Skip(CString strItemType="Sentence",long lNumItems=65535, ULONG *pulNumSkipped=NULL);
protected:
IEnumSpObjectTokens * m_pIEnumSpObjectTokens;
ISpObjectToken * m_pISpObjectToken;
ISpVoice * m_pISpVoice;
BOOL m_bComInit;
};
//TextToSpeech.cpp文件
#include "StdAfx.h"
#include "TextToSpeech.h"
TextToSpeech::TextToSpeech(void)
{
m_pIEnumSpObjectTokens = NULL;
m_pISpObjectToken = NULL;
m_pISpVoice = NULL;
m_bComInit = FALSE;
}
TextToSpeech::~TextToSpeech(void)
{
}
int TextToSpeech::Init()
{
//初始化COM组件
if(FAILED(::CoInitializeEx(NULL,0)))
{
//MessageBox("初始化COM组件失败!", "提示", MB_OK|MB_ICONWARNING);
return -1;
}
m_bComInit = TRUE;
return 0;
}
int TextToSpeech::UnInit()
{
if(m_bComInit)
{
::CoUninitialize();
}
return 0;
}
int TextToSpeech::EnumAudioToken(CString arrayVoicePackageName[],int nVoicePackageNameCount)
{
//枚举所有语音Token
if(SUCCEEDED(SpEnumTokens(SPCAT_VOICES, NULL, NULL, &m_pIEnumSpObjectTokens)))
{
//得到所有语音Token的个数
ULONG ulTokensNumber = 0;
m_pIEnumSpObjectTokens->GetCount(&ulTokensNumber);
//检测该机器是否安装有语音包
if(ulTokensNumber == 0)
{
//MessageBox("该机器没有安装语音包!", "提示", MB_OK|MB_ICONWARNING);
return -1;
}
if(ulTokensNumber > nVoicePackageNameCount)
{
//缓冲区过小
return 0;
}
//将语音包的名字加入数组中
CString strVoicePackageName = _T("");
CString strTokenPrefixText = _T("HKEY_LOCAL_MACHINE\\SOFTWARE\\Microsoft\\Speech\\Voices\\Tokens\\");
for(ULONG i=0; i<ulTokensNumber; i++)
{
m_pIEnumSpObjectTokens->Item(i, &m_pISpObjectToken);
WCHAR* pChar;
m_pISpObjectToken->GetId(&pChar);
strVoicePackageName = pChar;
strVoicePackageName.Delete(0, strTokenPrefixText.GetLength());
arrayVoicePackageName[i] = strVoicePackageName;
}
return ulTokensNumber;
}
return -1;
}
//创建SpVoice
int TextToSpeech::CreateSpVoice()
{
//获取ISpVoice接口
if(FAILED(CoCreateInstance(CLSID_SpVoice, NULL, CLSCTX_INPROC_SERVER, IID_ISpVoice, (void**)&m_pISpVoice)))
{
//MessageBox("获取ISpVoice接口失败!", "提示", MB_OK|MB_ICONWARNING);
return -1;
}
return 0;
}
//释放SpVoice
int TextToSpeech::DeleteSpVoice()
{
if(m_pISpVoice != NULL)
{
m_pISpVoice->Release();
}
m_pISpVoice = NULL;
return 0;
}
//重置SpVoice
int TextToSpeech::ResetSpVoice()
{
DeleteSpVoice();
return CreateSpVoice();
}
//设置朗读速度(取值范围:-10到10)
int TextToSpeech::SetRate( long RateAdjust)
{
if(m_pISpVoice == NULL)
return -1;
//设置播放速度
m_pISpVoice->SetRate(RateAdjust);
return 0;
}
//获取朗读速度
int TextToSpeech::GetRate(long *pRateAdjust)
{
if(m_pISpVoice == NULL)
return -1;
m_pISpVoice->GetRate(pRateAdjust);
return 0;
}
//设置使用的语音库
int TextToSpeech::SetVoice(ISpObjectToken *pToken)
{
if(m_pISpVoice == NULL)
return -1;
m_pISpVoice->SetVoice(pToken);
return 0;
}
//获取语音库
int TextToSpeech::GetVoice(unsigned int nIndex,ISpObjectToken** ppToken)
{
if(m_pIEnumSpObjectTokens == NULL)
return -1;
//设置语言
m_pIEnumSpObjectTokens->Item(nIndex, ppToken);
m_pISpObjectToken = *ppToken;
return 0;
}
//设置音量(取值范围:0到100)
int TextToSpeech::SetVolume(USHORT usVolume)
{
if(m_pISpVoice == NULL)
return -1;
//设置音量大小
m_pISpVoice->SetVolume(usVolume);
return 0;
}
//获取音量
int TextToSpeech::GetVolume(USHORT *pusVolume)
{
if(m_pISpVoice == NULL)
return -1;
//设置音量大小
m_pISpVoice->GetVolume(pusVolume);
return 0;
}
//开始朗读
int TextToSpeech::Speak(CString strContent, DWORD dwFlags)
{
if(m_pISpVoice == NULL)
return -1;
//开始进行朗读
HRESULT hSucess = m_pISpVoice->Speak(strContent.AllocSysString(), dwFlags, NULL);
return 0;
}
//朗读生成文件
int TextToSpeech::SpeakToWaveFile(CString strContent,char *pFilePathName,DWORD dwFlags)
{
if(m_pISpVoice == NULL || pFilePathName == NULL)
return -1;
//生成WAV文件
CComPtr<ISpStream> cpISpStream;
CComPtr<ISpStreamFormat> cpISpStreamFormat;
CSpStreamFormat spStreamFormat;
m_pISpVoice->GetOutputStream(&cpISpStreamFormat);
spStreamFormat.AssignFormat(cpISpStreamFormat);
HRESULT hResult = SPBindToFile(pFilePathName, SPFM_CREATE_ALWAYS,
&cpISpStream, &spStreamFormat.FormatId(), spStreamFormat.WaveFormatExPtr());
if(SUCCEEDED(hResult))
{
m_pISpVoice->SetOutput(cpISpStream, TRUE);
m_pISpVoice->Speak(strContent.AllocSysString(), dwFlags, NULL);
return 0;
//MessageBox("生成WAV文件成功!", "提示", MB_OK);
}
else
{
//MessageBox("生成WAV文件失败!", "提示", MB_OK|MB_ICONWARNING);
return 1;
}
}
//暂停朗读
int TextToSpeech::Pause()
{
if(m_pISpVoice != NULL)
{
m_pISpVoice->Pause();
}
return 0;
}
//继续朗读
int TextToSpeech::Resume()
{
if(m_pISpVoice != NULL)
{
m_pISpVoice->Resume();
}
return 0;
}
3)调用实例代码。
TextToSpeech ttsSpeech;
ttsSpeech.Init();
CString arrayVoicePackageName[50] = {0};
int nVoicePackageNameCount = 50;
int nCount = ttsSpeech.EnumAudioToken(arrayVoicePackageName,nVoicePackageNameCount);
ttsSpeech.CreateSpVoice();
ISpObjectToken* ppToken = NULL;
ttsSpeech.GetVoice(0,&ppToken);
ttsSpeech.SetVoice(ppToken);
ttsSpeech.SetRate(0);
ttsSpeech.SetVolume(100);
ttsSpeech.Speak("我是中国人");
//ttsSpeech.SpeakToWaveFile("我是中国人","d:\\11.wav");
ttsSpeech.DeleteSpVoice();
ttsSpeech.UnInit();
4、注意事项
1)、sphelper.h编译错误解决方案
SAPI 包含sphelper.h编译错误解决方案 在使用Microsoft Speech SDK 5.1开发语音识别程序时,包含了头文件“sphelper.h”和库文件“sapi.lib”。编译时出错: 1>c:\program files\microsoft speech sdk 5.1\include\sphelper.h(769): error C4430: missing type specifier - int assumed. Note: C++ does not supportdefault-int 1>c:\program files\microsoft speech sdk5.1\include\sphelper.h(1419) : error C4430: missing type specifier - intassumed. Note: C++ does not support default-int 1>c:\program files\microsoftspeech sdk 5.1\include\sphelper.h(2373) : error C2065: 'psz' : undeclaredidentifier 1>c:\program files\microsoft speech sdk5.1\include\sphelper.h(2559) : error C2440: 'initializing' : cannot convert from'CSpDynamicString' to 'SPPHONEID *' 1> No user-defined-conversion operatoravailable that can perform this conversion, or the operator cannot be called1>c:\program files\microsoft speech sdk 5.1\include\sphelper.h(2633) : errorC2664: 'wcslen' : cannot convert parameter 1 from 'SPPHONEID *' to 'constwchar_t *' 1> Types pointed to are unrelated; conversion requiresreinterpret_cast, C-style cast or function-style cast 搜索了一圈,根据大家的经验汇总,应该是Speech代码编写时间太早,语法不严密。而VS2008对于语法检查非常严格,导致编译无法通过。修改头文件中的以下行即可正常编译:
Ln769 const ulLenVendorPreferred = wcslen(pszVendorPreferred);
const unsigned long ulLenVendorPreferred = wcslen(pszVendorPreferred);
Ln 1418static CoMemCopyWFEX(const WAVEFORMATEX * pSrc, WAVEFORMATEX ** ppCoMemWFEX)
static HRESULT CoMemCopyWFEX(const WAVEFORMATEX * pSrc, WAVEFORMATEX ** ppCoMemWFEX)
Ln 2372for (const WCHAR * psz = (const WCHAR *)lParam; *psz; psz++) {}
const WCHAR * psz; for (psz = (const WCHAR *)lParam; *psz; psz++) {}
Ln 2559SPPHONEID* pphoneId = dsPhoneId;
SPPHONEID* pphoneId = (SPPHONEID*)((WCHAR *)dsPhoneId);
Ln 2633pphoneId += wcslen(pphoneId) + 1;
pphoneId+= wcslen((const wchar_t *)pphoneId) + 1;
2)、Speak指定为SPF_ASYNC(异步)时,不要过早的释放ISpVoice对象,否则就没有声音,因为ISpVoice生命周期结束了,就不会播放。一般将ISpVoice对象放到类的成员变量中,类析构时才释放ISpVoice对象。
3)、Speak第一次朗读时很慢,因为加载引擎需要一段时间,可以使用线程预先Speak("",SPF_ASYNC)而加载引擎,但需要注意的是在初始化COM的时候使用CoInitializeEx,而不要使用CoInitialize。