目录
- 直接爬取HTML (30%)
- 爬取数据接口(50%)
- Selenium爬取(既没有HTML内容,也没找到合适的数据接口)(20%)【入门】 【验证、校验等信息】
今天:
- Selenium 自动测试(爬虫)工具;
- 启动浏览器,按照真实的用户操作和用户所见,提取网页数据。
1、网络爬虫-课后练习题
爬虫技巧 + 基础编程能力(对数据的处理)
课后习题:爬取并分析汽油价格
网址:东方财富网-油价模块 https://data.eastmoney.com/cjsj/oil_default.html
要求:
1、爬取所有汽油价格变动信息(2000-06-06至今)
2、一共涨价多少次,降价多少次
3、哪个时间段油价是最便宜的 (开始和结束的年月日)
4、哪个时间段油价是最贵的(开始和结束的年月日)
5、油价停留在2000-3000元之间的有多长时间(天数)(一小时内,看是否能完成)
提示:
接口地址:
https://datacenter-web.eastmoney.com/api/data/get?type=RPTA_WEB_YJ_BD&sty=ALL&st=dim_date&sr=-1&p=2&ps=10
#2为页码
1.1、写法1
'''
爬取并分析汽油价格
网址:东方财富网 - 油价模块 https://data.eastmoney.com/cjsj/oil_default.html
要求:
1.爬取所有汽油价格变动信息(2000-06-06~至今)。
2.一共涨价多少次,降价多少次。
3.哪个时间段油价是最便宜的(开始和结束的年月日)。
4.哪个时间段油价是最贵的(开始和结束的年月日)。
5.油价停留在2000-3000元之间的有多长时间(天数)。
'''
import requests as req
import json
import datetime
hds = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'}
url = 'https://datacenter-web.eastmoney.com/api/data/get?type=RPTA_WEB_YJ_BD&sty=ALL&st=dim_date&sr=-1&p={}&ps=10';
infos = [];
# 1.爬取所有汽油价格变动信息(2000-06-06~至今)。
for i in range(23):
resp = req.get(url.format(i + 1), headers=hds)
ls = json.loads(resp.content.decode('utf-8'))['result']['data'];
for l in ls:
r = [l['dim_date'], l['value'], l['qy_fd']]; # ['2021-07-13 00:00:00',8120,70] ;
infos.append(r);
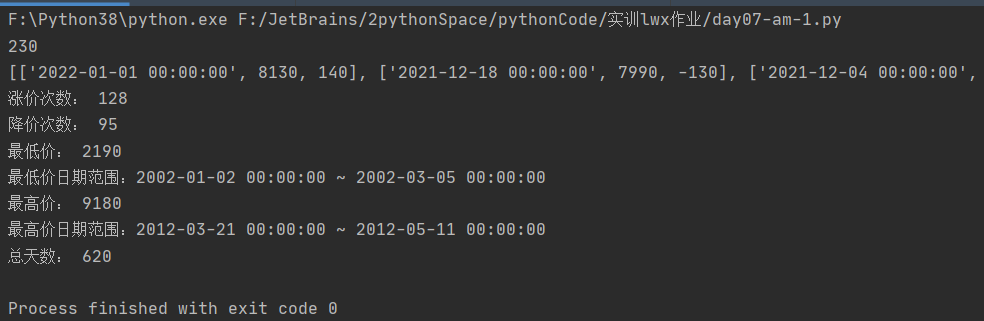
print(len(infos))
print(infos)
infos[-1][2] = 0; # 将最后一个None值,设为0
# ['2022-01-01 00:00:00', 8130, 140], ['2021-12-18 00:00:00', 7990, -130],
# ['2021-12-04 00:00:00', 8120, -430], ['2021-11-20 00:00:00', 8550, -95],
# ['2021-10-23 00:00:00', 8645, 300], ['2021-10-10 00:00:00', 8345, 345]
# filter来实现也可以
ct_up = 0;
ct_down = 0;
for info in infos:
if info[2] > 0:
ct_up = ct_up + 1;
elif info[2] < 0:
ct_down = ct_down + 1;
# 2.一共涨价多少次,降价多少次。
print('涨价次数:', ct_up)
print('降价次数:', ct_down)
ps = [x[1] for x in infos]; # 将所有的油价提取出来
# 3.哪个时间段油价是最便宜的(开始和结束的年月日)。
minprice = min(ps); # 找到油价最低的值
print('最低价:', minprice);
print('最低价日期范围:', end='')
for i, info in enumerate(infos): # 既能得到下标i,又能得到元素本身
if info[1] == minprice:
if i == 0: # 更严谨
print(info[0], '~ 至今');
else:
print(info[0], '~', infos[i - 1][0]);
# 4.哪个时间段油价是最贵的(开始和结束的年月日)。
maxprice = max(ps); # 找到油价最高的值
print('最高价:', maxprice);
print('最高价日期范围:', end='')
for i, info in enumerate(infos): # 既能得到下标i,又能得到元素本身
if info[1] == maxprice:
if i == 0: # 更严谨
print(info[0], '~ 至今');
else:
print(info[0], '~', infos[i - 1][0]);
def days(startstr, endstr):
start = datetime.datetime.strptime(startstr[:10], '%Y-%m-%d').date();
end = datetime.datetime.strptime(endstr[:10], '%Y-%m-%d').date();
return (end - start).days;
# 5.油价停留在2000-3000元之间的有多长时间(天数)。
infos.reverse(); # 倒序
# print(infos)
totalsum = 0;
for i, info in enumerate(infos):
if info[1] >= 2000 and info[1] <= 3000:
ds = days(info[0], infos[i + 1][0]);
totalsum = totalsum + ds;
print('总天数:', totalsum);
# 有思路(编程思维) + 有办法(积极百度)1.2、写法2

'''
爬取并分析汽油价格
网址:东方财富网 - 油价模块 https://data.eastmoney.com/cjsj/oil_default.html
要求:
1.爬取所有汽油价格变动信息(2000-06-06~至今)。
2.一共涨价多少次,降价多少次。
3.哪个时间段油价是最便宜的(开始和结束的年月日)。
4.哪个时间段油价是最贵的(开始和结束的年月日)。
5.油价停留在2000-3000元之间的有多长时间(天数)。
'''
import datetime
import json
import sys
import requests
def daytime(str1, str2):
d1 = datetime.date(int(str1[0:4]), int(str1[5:7]), int(str1[8:10]))
d2 = datetime.date(int(str2[0:4]), int(str2[5:7]), int(str2[8:10]))
return (d1 - d2).days
# 爬取数据接口,得到数据
hds = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'}
url = 'https://datacenter-web.eastmoney.com/api/data/get?callback=&type=RPTA_WEB_YJ_BD&sty=ALL&st=dim_date&sr=-1&token=894050c76af8597a853f5b408b759f5d&p=1&ps=250&source=WEB&_=1641888888471'
resp = requests.get(url, headers=hds)
ct = resp.content.decode('utf-8')
ct = json.loads(ct)
ls = list(ct["result"]["data"])
ls = list(reversed(ls))
# print(ls)
count_rise = 0
count_drop = 0
qy_expensive = -sys.maxsize - 1
qy_cheap = sys.maxsize
for i in ls:
print('时间:' + str(i['dim_date']) + '汽油价格:' + str(i['value']))
if i['qy_fd'] is not None:
if i['qy_fd'] > 0:
count_rise += 1
if i['qy_fd'] < 0:
count_drop += 1
if i['value'] > qy_expensive:
qy_expensive = i['value']
if i['value'] < qy_cheap:
qy_cheap = i['value']
print('上涨次数:' + str(count_rise))
print('降价次数:' + str(count_drop))
for i, j in zip(ls, ls[1:]):
if i['value'] == qy_expensive:
print('最贵的价格:' + str(qy_expensive))
print('最贵的时候是:' + i['dim_date'] + '到' + j['dim_date'])
for i, j in zip(ls, ls[1:]):
if i['value'] == qy_cheap:
print('最便宜的价格:' + str(qy_cheap))
print('最便宜的时候是:' + i['dim_date'] + '到' + j['dim_date'])
days = 0
for i, j in zip(ls, ls[1:]):
if 3000 >= i['value'] >= 2000:
days += daytime(j['dim_date'], i['dim_date'])
print('油价停留在2000-3000元之间的天数:' + str(days))2、Selenium自动化测试工具
2.1、安装工具
使用Selenium自动化测试工具
1、需要安装自动化测试库:pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple/
2、下载安装一下Chrome浏览器
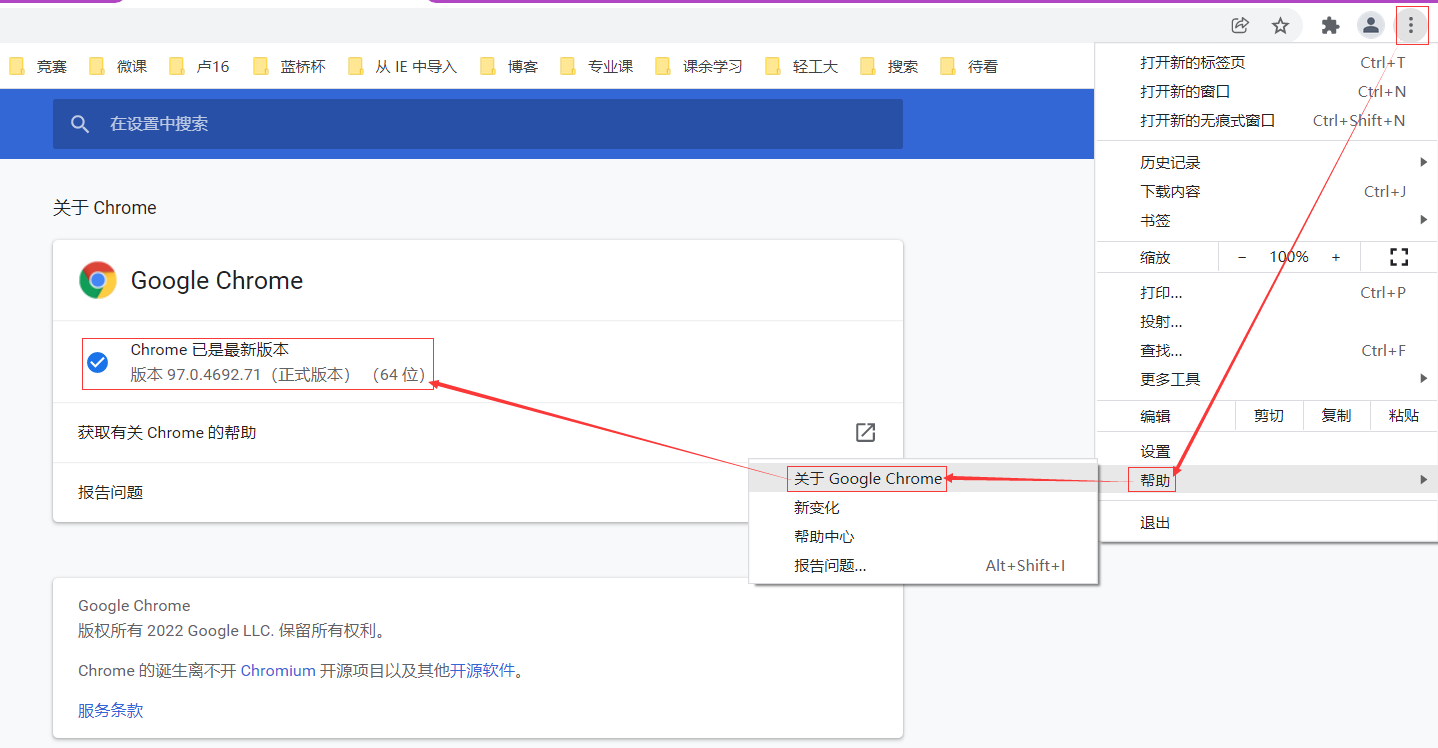
3、查看一下浏览器版本:
版本 97.0.4692.71 (我的版本)
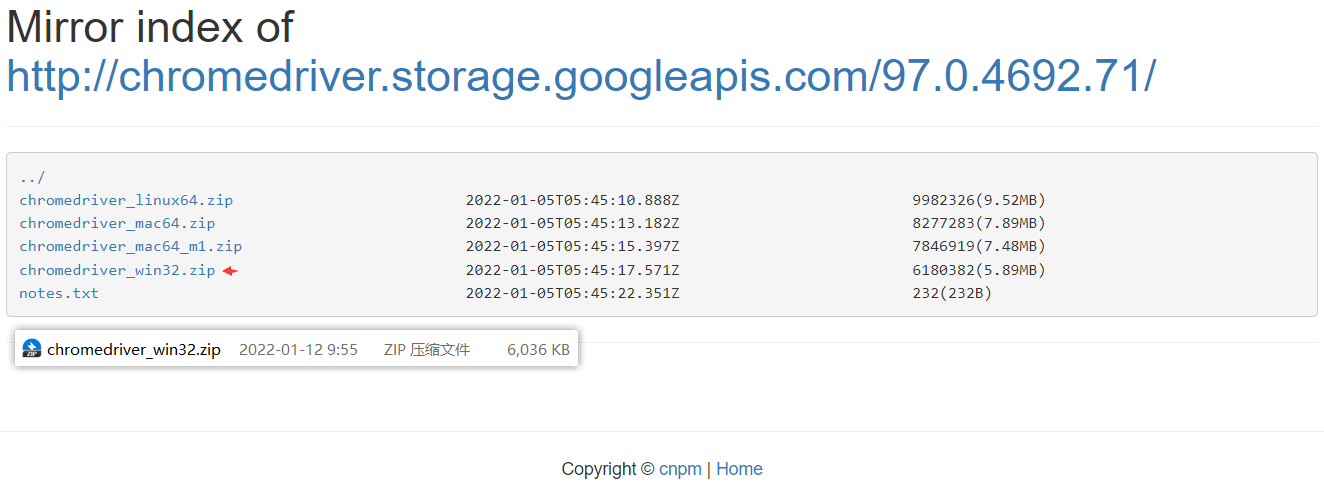
根据版本下载对应的 chromedriver (selenium中需要调用,跟你日常使用没关系)
网址:http://npm.taobao.org/mirrors/chromedriver/4、将chromedriver.zip解压缩,得到chromedriver.exe文件,将该文件放入到python安装目录。
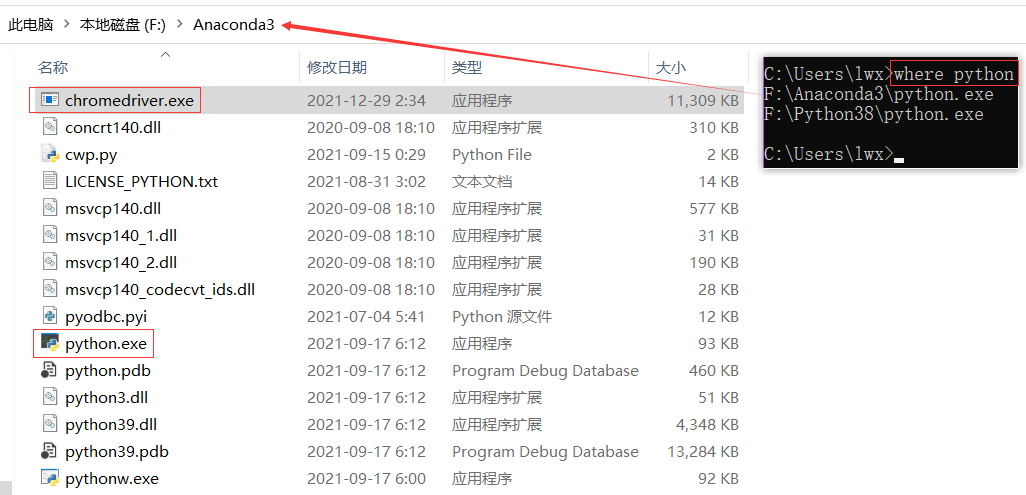
将解压好的chromedriver.exe放入到anaconda的安装目录selenium:可以通过代码来控制浏览器,点击、输入、前进、后腿、打开、关闭、访问网址等。
安装命令:pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple/


查看谷歌浏览器版本:
下载地址:ChromeDriver Mirror
将解压好的chromedriver.exe放入到anaconda的安装目录,也就是和python.exe在同一个文件夹中。
可以通过where python来查看Python的安装目录。

2.2、命令行操作
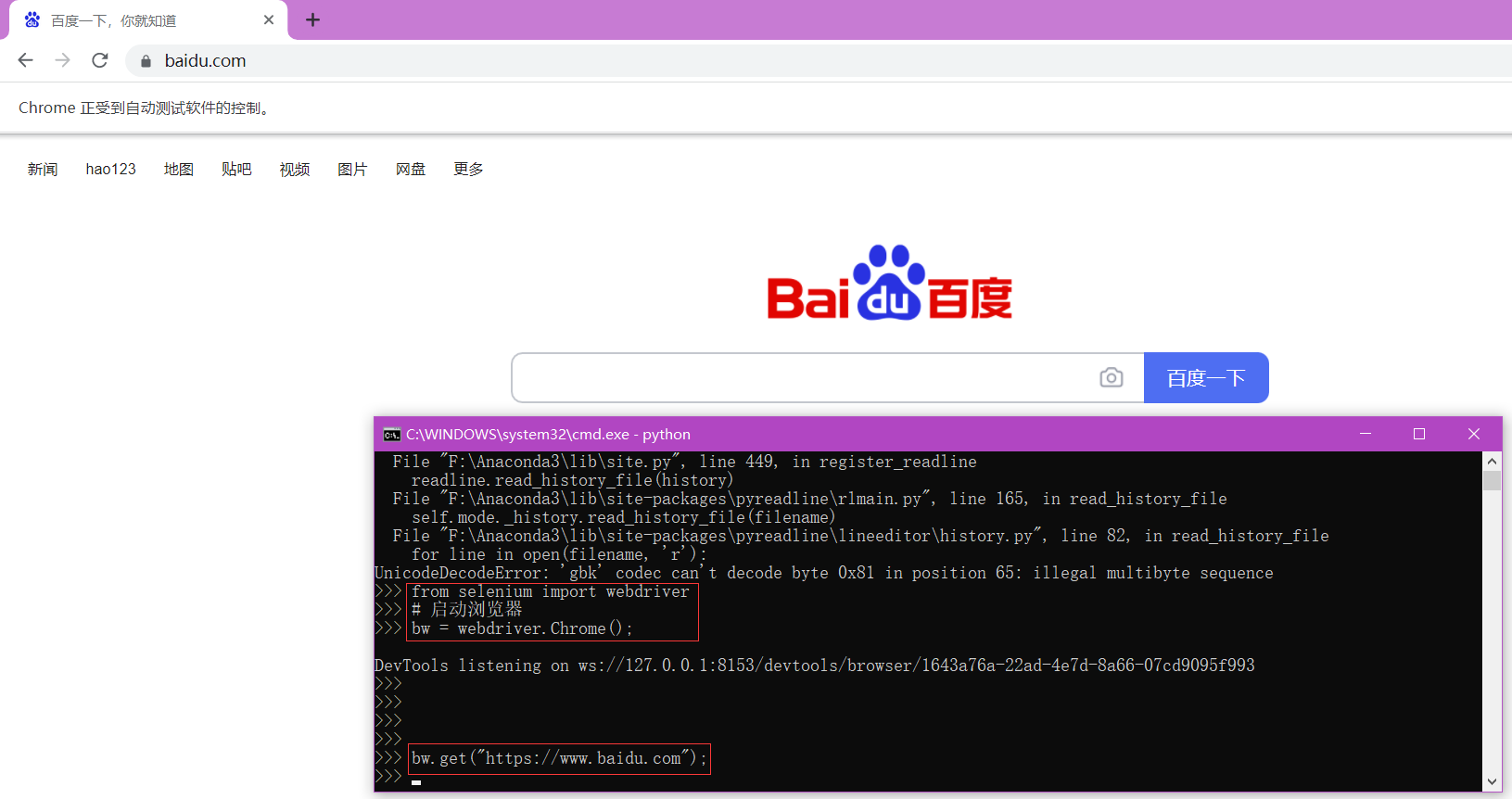
from selenium import webdriver
# 启动
bw = webdriver.Chrome(); # bw对象,就代表你的浏览器窗口
# 注意,如果杀毒软件有弹窗拦截,请点击“允许”(永久允许)
# 版本和路径都正确,才能开启浏览器。
# 访问路径
bw.get("https://www.baidu.com"); #
# 注意,没有返回值;所有的数据变动,都体现在bw对象本身。
# 获取页面内容
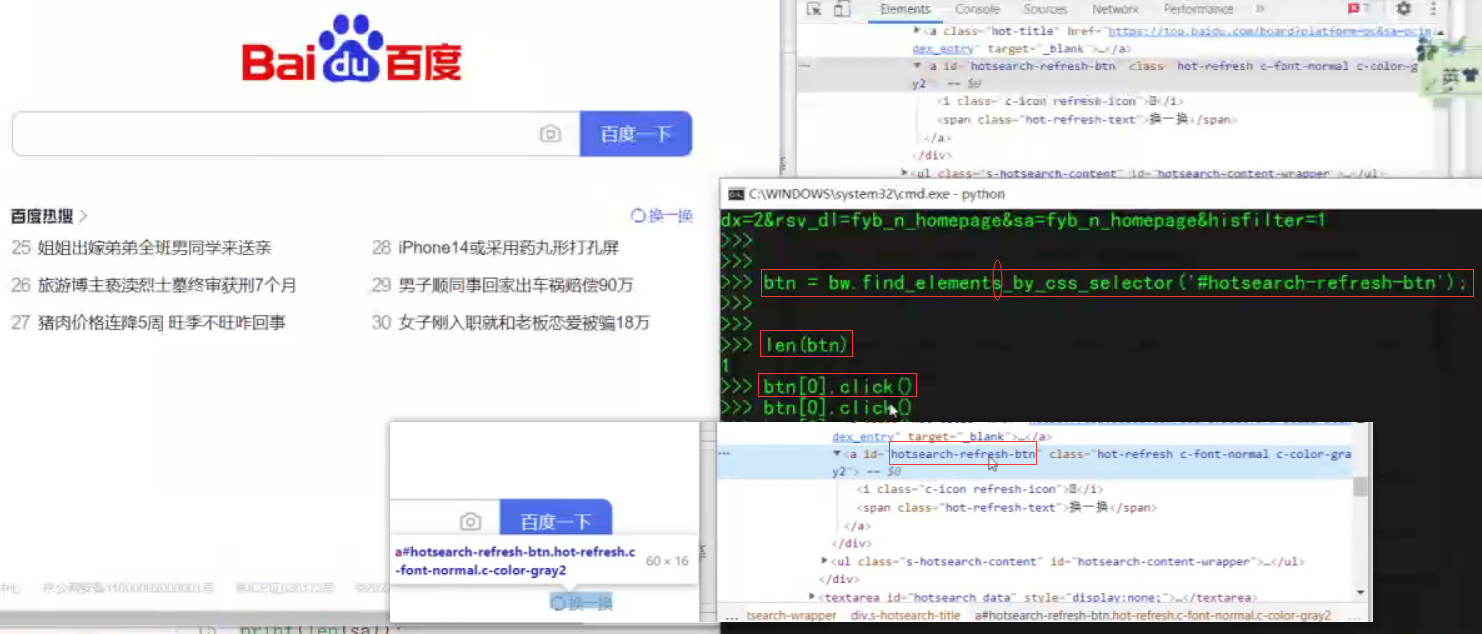
# 定位元素:find_elements_by_css_selector('选择器')--->相当于 select('选择器')
sa = bw.find_elements_by_css_selector('.hotsearch-item a')
print(len(sa));
# 获取元素内容:.text---->get_text()
# 获取元素属性:.get_attribute("属性名")--->['属性名']
for a in sa:
print(a.text);
# 实现点击
# 定位元素 调用click即可
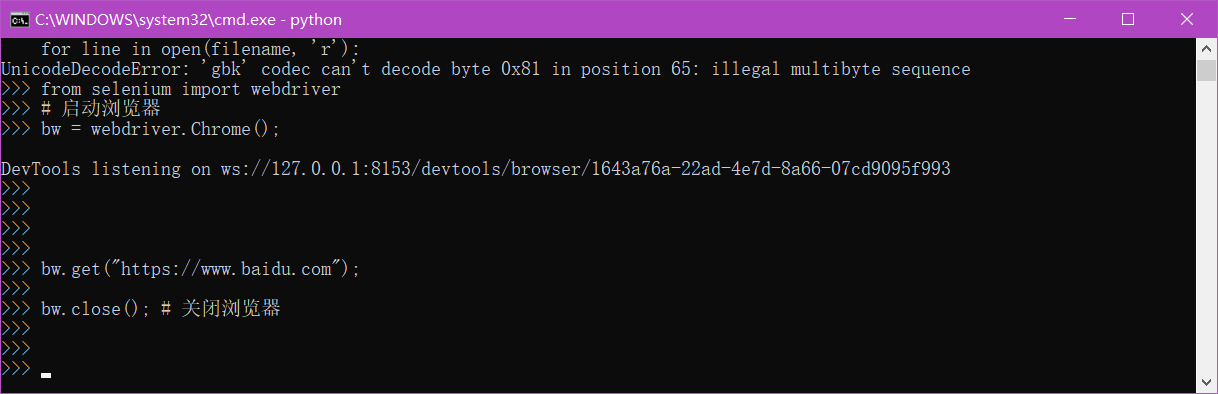
# 关闭
bw.close()>>> from selenium import webdriver
>>> # 启动浏览器
>>> bw = webdriver.Chrome();
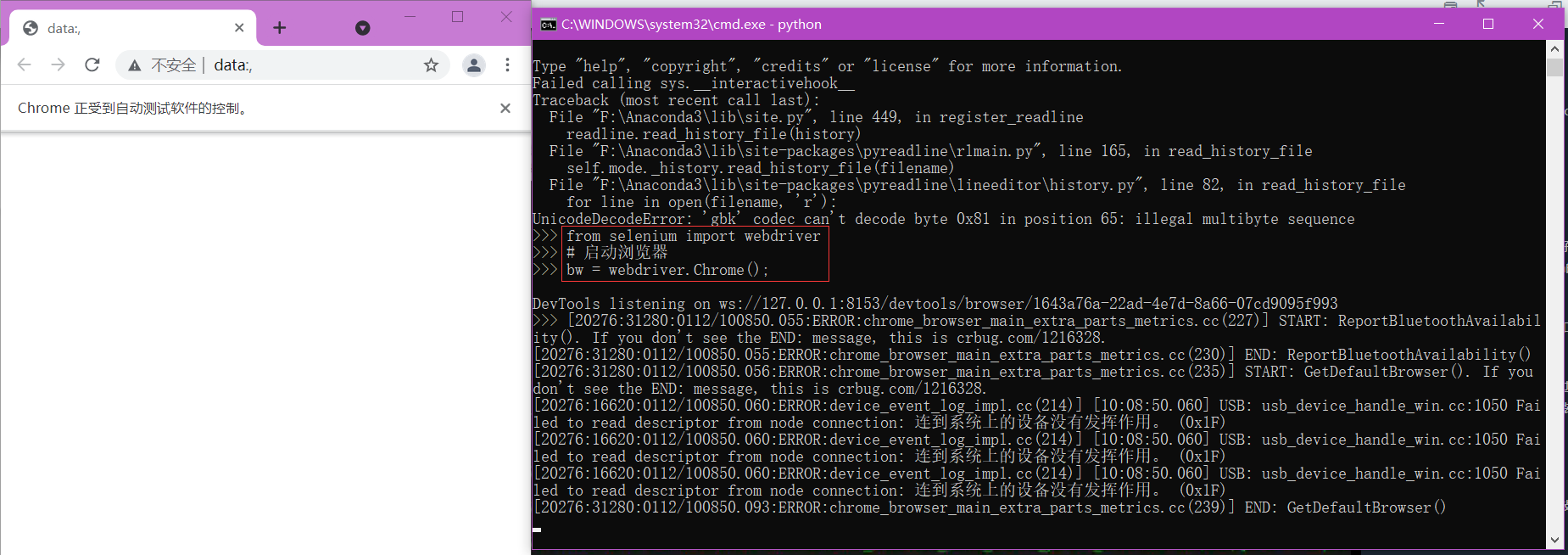



PyCharm导入selenium: