前言:
读书报告非得做区块链攻防综述相关的,那我这个共识算法的报告就白做了咯
那就放上来和大家一起分享呗
正文:
摘要
在分布式系统中,我们需要制定一定的规则使得多个服务节点对某一个提案达成一致的意见,从而避免脑裂现象。这就是共识算法,它负责来维护系统的一致性。在区块链系统中,公链主要采用的是PoW共识算法、联盟链主要采取的是PBFT共识算法、私链主要采取的是Raft或Paxos共识算法,本文主要对这四种算法展开研究和分析。
关键词: 共识算法、区块链、一致性
Abstract
In a distributed system, we need to make certain rules so that multiple service nodes agree on a proposal, so as to avoid brain-splitting. This is the consensus algorithm, which is responsible for maintaining the consistency of the system. In blockchain system, public chain mainly adopts PoW consensus algorithm, federation chain mainly adopts PBFT consensus algorithm, and private chain mainly adopts Raft or Paxos consensus algorithm. This paper mainly conducts research and analysis on these four algorithms.
Keywords: consensus algorithms, blockchain, consistency
1 共识算法概述
在区块链系统中,我们需要共识算法来使得所有共识节点按照相同顺序执行交易、写入账本。然而,根据CAP理论,一致性、可用性和分区容错性最多三者满足其二,因此我们需要结合不同类型区块链的特点,部署不同特点的共识算法。在公链中,由于完全开放的特性,因此需要尽可能地抵御拜占庭攻击。在PoW中,通过算力竞争记账权,从而保证区块链的安全掌控在大多数算力的节点上,但缺点则是牺牲了效率;在PoS中,通过财富集中趋势获得话语权,这样的设计虽然大大提高了效率,但是会由于财富集中化导致安全问题。在联盟链中,系统通常由具有相同目的的几个组织或机构组成,所以其抗拜占庭容错的力度可以稍微降低,应以进一步提高性能为目标。PBFT算法通过主从节点和视图机制,可保证容错率达到33%,性能相对于PoW大大提升,但是由于通信开销限制了其规模。在私链中,由于节点一般存在于机构内部,因此往往不存在拜占庭节点,所以可以进一步地提高效率和容错性。Paxos算法通过准备和接受两个阶段完成各节点的共识,但其细节往往难以理解;Raft算法是一个可理解性更高的共识算法,通过follower、candidate和leader间的切换和交互完成共识。
总体来说,在区块链中共识算法可分为合作或竞争类型,在合作中又可分为抗欺诈或信任Leader类型,在竞争中可分为拼算力或拼财力类型。因此,作为区块链的核心引擎,共识机制可以保证在多方参与且各方博弈的情况下,达到共同接受的唯一结果,并且保证难以欺骗和稳定运行。
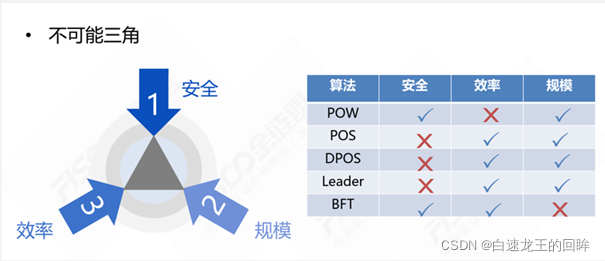
图1.共识算法的不可能三角
2 PoW算法
PoW算法作为比特币中的共识机制,是区块链应用中最成熟的共识算法之一,它通过遍历随机数计算满足条件的哈希值来争夺记账权。由于尝试随机数过程具有无记忆性,所以最终的记账节点必定是在算力上占优的,而这样的节点往往是不可能作恶的,因为它通过诚实工作获得的奖励比它作恶盗取的资产更可观。
哈希值中的元素是根据区块头中的属性组合而成,而其中可变的只有nonce和merkleRoot的值。具体源码可见下图:
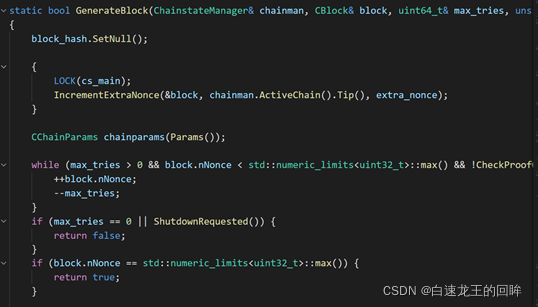
图2.比特币源码_修改Nonce进行挖矿
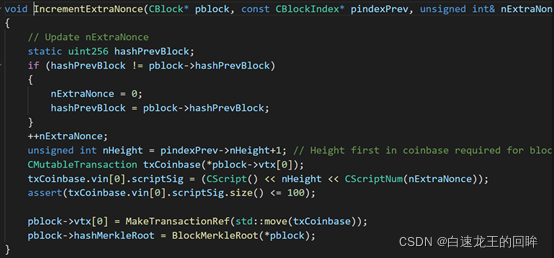
图3.比特币源码_修改MerkleRoot进行挖矿
在比特币源码中,我们可以发现:在GenerateBlock函数中,通过在max_tries范围内遍历nNonce的值来判断是否达到所需哈希;同时,若一次尝试完毕后,会跳出循环通过IncrementExtraNonce函数来改变coinbase交易的内容从而改变MerkleRoot的值来进行二次extraNonce的尝试。
最后将计算出来的哈希值和给定的nBits进行大小比较,若小于nBits则说明满足条件,从而挖矿成功。
3 PBFT算法
PBFT是一个拜占庭容错的联盟链算法,这种机制脱离了公链中的加密货币奖励。它主要的流程如下:第一,client发送请求来调用primary节点的服务操作;第二,primary节点将request广播给backup节点;第三,各个节点都执行request然后给client发送reply;第四,如果client收到来自不同节点的不少于f + 1(假设总共有3f个节点)个相同的回应,那么client就会认为这就是操作后的返回结果。
具体来说,PBFT算法的核心在于三阶段协议。
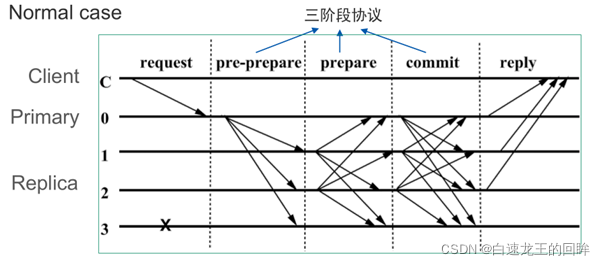
图4.PBFT三阶段协议
在第一阶段,client发起交易请求,primary将收到的交易打包成块,然后广播;在第二阶段,副本节点收到pre-prepare消息后生成prepare消息转发给其他副本节点;第三阶段,若节点收到2f + 1个prepare消息后生成commit消息并转发给其他节点,若节点收到2f + 1个commit消息后执行交易并写入账本。
为了更高的容错性和可用性,PBFT采用视图切换和日志压缩机制。在主节点突然失效的时候,即主节点在共识未超过2/3时进行答复或超过定义时长,会根据视图重新选举primary节点。视图切换(节点排位,副本1为主节点),可以让至少f+1个诚实节点迁移到新的一致状态。通过视图切换,可以选举出新的、让请求在有限时间内达成一致的主节点,向客户端响应。此外,PBFT通过Checkpoint机制来压缩日志,Checkpoint即当前节点所处理的最新请求编码,而大部分节点共识完成的最大请求编号前的日志就成为过时日志,可以删除来减少存储消耗。
进一步地,我们可以证明PBFT具有33%容错率。设节点总数为N,拜占庭节点总数为F,由于拜占庭节点可能不发信息,所以每个节点需要从N-F个节点中判断。最坏的情况下,这N-F个节点中包括了全部的F个拜占庭节点,那么诚实的节点只有N-2F个,这时就需要N-2F > F(少数服从多数),因此N > 3F,所以N的最小值为3F + 1。
反过来,若3F个节点中存在着F个拜占庭节点,我们可以通过脑裂来破坏共识。我们假设诚实节点(A),诚实节点(B),拜占庭节点(C)各F个,由于此时每个节点收到2f个有效的prepare消息就可以达成共识。因此这时候如果主节点为拜占庭节点,C向A发进攻指令(共2f个节点),A达成进攻共识。C向B发撤退指令(共2f个节点),B达成撤退共识。A和B就不一致了。
值得一提的是,Prepared是一个局部视角,此时副本仍无法确定其他副本是否也达到了Prepared状态。只有通过Commit机制获取全局视角,当得知2f + 1个节点都处于Prepared状态才可以执行请求。我们可以假设某一个节点不通过commit阶段直接将prepared信息执行,若此时恰巧primary宕机就会发生视图切换,后续马上会发生消息序列的更新从而只有这个节点执行了请求。
4 PAXOS算法
Paxos算法是Lamport教授在1990年提出来的一种基于消息传递的一致性算法,后面很多算法都是基于它改造而来的,但Paxos算法是公认的晦涩难懂,基本没有工程实现Paxos算法。Paxos算法需要解决的问题就是如何在一个可能发生异常的分布式系统中,快速正确地保持分布式系统中状态的一致性。在Paxos算法中,有Proposer、Acceptor和Learner三种角色。其中,Proposer负责提出提案、Acceptor负责对提案做出判断,Learner负责学习提案的结果。只要Proposer发起的提案被大多数的Acceptor接受,Proposer就认为提案中的value被选定了,同时Acceptor将选定的value告知Learner。
具体来说,Paxos算法主要分成两个阶段,分别是准备阶段和接受阶段。

图5.PAXOS准备阶段
图5的客户端我们可以认为是上述的Proposer, 它首先选择一个提案编号,然后向半数以上的Acceptor发送请求。每一个Acceptor只会响应比它之前响应过所有的请求编号都更大的新的请求编号,同时承诺不再接受任何小于该请求编号的其他提案。
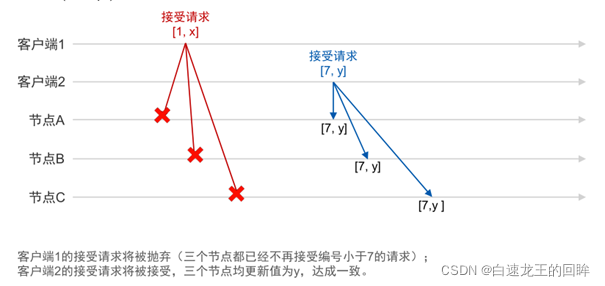
图6.PAXOS接受阶段
若一个Proposer收到半数以上Acceptor在准备阶段的回应,那么它就会发送带有编号和提案内容的信息给半数以上的Acceptor。然而,这时候Acceptor只对不小于它接受过最大的提案编号的提案内容做响应,如图6中的三个Acceptor节点都会把编号为1的提案丢弃。在这种编号机制下,就可以保证提案内容的一致性。
在两阶段协议过后,Learner需要学习第二阶段accept的结果,一般来说有三种学习方案。第一,Acceptor接受了一个提案,就把该提案发送给所有Learner,这种方案的优点是所有Learner都可以快速地获知value,缺点是通信次数大。第二,Acceptor只将提案发送给主Learner,并由主Learner再告知其他Learner,这种方案可以大大减少通信次数,但是会出现单点故障问题。第三,Acceptor将提案内容告知一个Learner集合,再让其告知所有Learner,这是一个折衷的方案,具体的Learner集合个数决定了其可靠性和复杂度。
然而,如果有多个Proposer发起提案,它们有可能会出现交替处于准备和接受阶段的情况,从而陷入无限死循环,没有一个Proposer可以完成接受阶段。因此,我们需要选取一个主Proposer,并规定只有主Proposer才能提出提案,这就可以保持算法的活性了。
5 RAFT算法
Raft作为一种管理副本日志的共识算法,它将共识的核心步骤分开,例如节点选举、日志副本和安全性等,同时它加强了更强的一致性来减少必须考虑的状态数量,它理解起来比Paxos简单得多,并在实际系统中得到广泛的使用。具体来说,Paxos并没有构建一个可行部署的方案。Lamport教授在论文只描绘了多方Paxos的一个草图,但缺失了很多细节,从而导致实现起来比较困难。
在Raft中,主要有三种状态的节点,分别是Leader节点、Candidate节点和Follower节点。它们的转化关系如下图:
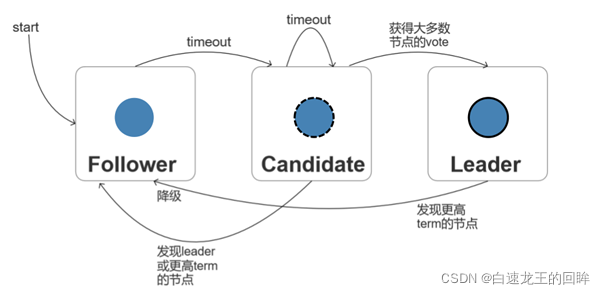
图7.Raft节点转换关系
raft是围绕日志log进行展开的,每个log都有唯一对应的term和index编号。在系统最开始的时候,所有raft节点都是Follower。每个节点都会有一个超时时间,当Follower达到它的超时时间之后它就会自动升级为Candidate。然后Candidate就会向其余节点发送RequestVoteRpc,也就是拉票的Rpc,其他节点收到该Rpc后只能进行一次投票,当Candidate获得超过半数以上的选举票后,它就可以升级成为Leader。没有异常的情况下,Leader会保持不变。Leader主要的职责就是负责和外部的client对接,并将client的操作写进log里面,然后发送给其他节点并使得集群保持一致性。然而,当Leader宕机或通信出现问题后,就会有新的Follower升级为Candidate并发起新一轮的投票,从而选出新的Leader。当原Leader回归后,会根据比较term的大小信息降级为Follower并重置其log中的内容。
raft主要的实现逻辑集中在RequestVoteRPC,AppendentriesRPC上完成raft节点之间的信息交互。此外,通过协程+定时器的方式定期进行appendentries的发送(包括心跳)、重选举的检查以及将commited的log apply的操作。在实现的过程中,raft节点的初始化除了对必要变量进行赋值外,还要拉起三个goroutine进行定期检查。

图8.Raft中的三个定时器

图9.Raft中的实现细节
CheckElection协程主要负责管理选举超时的逻辑,这里的超时时间我们选择在一定范围内的随机数。倘若某节点在这段时间内既没有收到Candidate的拉票Rpc也没有收到Leader的日志同步信息,它就会自动升级为Candidate并发起RequestVoteRpc与其余节点进行交互。在RequestVoteRpc中我们需要定义Candidate和Follower对参数的处理逻辑,而根据raft论文的Fig2我们可以通过以下逻辑进行实现。首先,作为Candidate对每个peer拉起一个goroutine,通过Rpc的交互得到peers反馈的term和投票参数,在再次检验本机状态后若candidate得到相同的term反馈且获得半数以上投票,则candidate变成leader;反之,若candidate收到的参数中发现peers的Term比自己的大,那么candidate自动降级为follower。其次,对于peer而言,若candidate的term比自身的小,或不满足论文中的UpToDate状态,则不予以投票;若candidate的term大于自身的,则更新自身的term,且peer只能进行一次有效的投票。
CheckAppendEntries协程主要实现了leader发送心跳,以及同步log entries信息的功能。类似于RequestVoteRpc的实现,AppendEntriesRpc也需要对发送者leader和接收者follower实现处理逻辑。首先,作为leader对每个peer拉起一个goroutine,然后复查自身的状态以及follower的prevLogIndex是否合法。若leader的lastIndex大于等于follower的nextindex,leader就可以将多出来的log entires放入appendEntriesRpc的参数中,否则参数中的entries信息为空,之后便可进行appendEntriesRpc交互并得到follower的输出参数。若follower返回的term更大,leader将更新term并降级为follower;若follower成功更新日志,则leader更新matchIndex和nextIndex,同时若超过半数的follower将某个log放入本地,则leader可将此log状态设置为commit;若follower更新日志失败,leader可找到回应中的conflictIndex并将其存入该follower的nextIndex中,方便下次继续询问并更新日志。其次,每个follower接受到leader发出的appendEntries的参数后,需要做如下处理:第一,若leader发出的term比本身要小,直接返回false和自身的term;若leader发出的term大于等于自身的,则更新自身的状态和重置选举超时;若自身缺失了一部分信息,则修改返回的ConflictIndex值为自身的最后一个Index;若自身的term和参数传入的term不匹配,则将此term上的log全部视为conflict,并传回上一个term最后Index作为ConflictIndex;最后若prevLogIndex之前的信息完全一致,则从其后加入参数中的logs信息。
最后,checkApplied的功能主要是将已经commit的日志结果返回给客户端,这也体现了raft的特点是先保持内部一致再向外部发送结果。进一步地,为了防止raft突然宕机,我们可以引入Persist模块进行持久化操作,使得宕机恢复的节点可以通过本地存储读取宕机前的信息。同时,为了减少存储压力,raft采取日志压缩的rpc实现只保留某一Index前的结果,但删去其详细的日志信息,有效避免了存储爆炸。
6 总结与展望
共识算法是区块链技术的核心要素,也是近年来分布式系统研究的热点。针对公链、联盟链和私链不同的架构需求,具有不同优势的共识算法分庭抗礼。我们评价共识算法的指标一般包括公平性、去中心化程度、能耗成本、参与者的激励相容性、可扩展性、吞吐量、容错性和安全性等,如何根据具体的需求和应用场景自适应地设计针对性地共识机制和算法优化将是未来研究的热点。其次,为了进一步促进共识,我们仍需要在不发币的联盟链和私链中考虑激励机制和共识算法相结合,从而通过博弈论原理保障区块链系统的健康稳定运行。
参考文献
[1] Nakamoto, Satoshi. "Bitcoin: A peer-to-peer electronic cash system,” http://bitcoin.org/bitcoin.pdf
[2] Leslie Lamport. The part-time parliament. ACM Transactions on Computer Systems, 16(2):133–169, May 1998.
[3] Lamport L. Paxos made simple[J]. ACM Sigact News, 2001, 32(4): 18-25.
[4] CASTRO M.Practical byzantine fault tolerance[C]//OSDI.1999:173-186.
[5] Ongaro, Diego, and John Ousterhout. “In search of an understandable consensus algorithm (extended version).”(2013). http://pages.cs.wisc.edu/~remzi/Classes/739/Spring2004/Papers/raft.pdf