背景
非精确:牺牲一定准确度换取空间效率和时间效率。
- 统计网站的UV(独立访客数):当用户数量非常多时,比如几千万甚至上亿,那么使用普通的哈希表去重将会占用可怕的巨大内存空间。引用吴军博士的《数学之美》中所言,这是因为哈希表的空间效率不够高,哈希表的存储效率一般只有50%。如果用哈希表存储一亿个userId,每个userId对应 8bytes,那么一个id就需要占用16bytes。因此一亿个userId占用1.6GB,如果存储几十亿个userId则需要上百GB的内存。而内存又是非常宝贵的资源,单单为了统计普通页面的UV就需要这么多内存无疑非常浪费。并且在实际中我们也不需要非常精确的数据,不需要精确到个位数。
[初试牛刀]HyperLogLog
HyperLogLog 是一种基数估算算法。也就是估算在一批数据中,不重复元素的个数有多少。基数估计的结果是一个带有 0.81% 标准误差的近似值。是可接受的范围。思路是通过给定 n 个的元素集合,记录集合中数字的比特串第一个1出现位置的最大值k,也可以理解为统计二进制低位连续为零(前导零)的最大个数。通过k值可以估算集合中不重复元素的数量N,N近似等于 2^k。

下面编写一个实验来观察一下K和N的关系:

可以发现K和N的对数之间存在显著的线性相关性(输出分别是 随机数数量N,N的对数,K值):
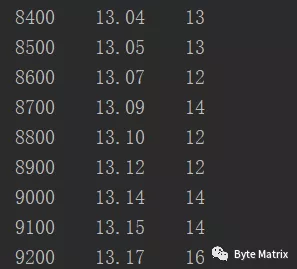
使用了SPSS分析,可以看的更清晰

但是这种预估方法存在较大误差,为了改善误差情况,HyperLogLog中引入分桶平均的概念,计算 m 个桶(多个BitKeeper)的调和平均值。
Redis 中 HyperLogLog 一共分了 2^14 个桶,也就是 16384 个桶。每个桶中是一个 6 bit 的数组,如下图所示。

HyperLogLog 将上文所说的 64 位比特串的低 14 位单独拿出,它的值就对应桶的序号,然后将剩下 50 位中第一次出现 1 的位置值设置到桶中。50位中出现1的位置值最大为50,所以每个桶中的 6 位数组正好可以表示该值。
在设置前,要设置进桶的值是否大于桶中的旧值,如果大于才进行设置,否则不进行设置。

其实Redis也对HyperLogLog存储进行了优化,当计数比较少时,使用的是稀疏矩阵进行存储,占用的空间很小,当计数逐渐变大,超过了稀疏矩阵的阈值时,才会转变成稠密矩阵,占用(2^14)*6/8=12KB的空间,却可以记录2^50个不同的64位长度的数值。
使用
pfadd 添加
时间复杂度O(1)
> pfadd m1 1 2 3 4 1 2 3 2 2 2 2
(integer) 1
pfcount 获得基数值
> pfcount m1
(integer) 4
pfmerge 合并多个key
取多个key的并集
> pfmerge mergeDes m1 m2
OK
缺点
只能得到计数,无法判断一个元素是否存在于一个集合中;
数据量不大就用不上,会有点大材小用浪费空间
[进阶]布隆过滤器
用于预防缓存穿透,如在秒杀系统中,预先加载有效商品的id到缓存中,避免无效请求都去查数据库,浪费数据库资源。除此之外还可用于邮件系统的垃圾过滤,爬虫URL地址去重等。
它的优点是空间效率和查询时间都远远超过一般的算法,布隆过滤器存储空间和插入 / 查询时间都是常数O(k)。另外, 散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
实际的数据结构就是一个大型的位数组和几个无偏hash函数(如下图的f,g,h),无偏就是能把元素的hash值计算的比较均匀,让元素能够被映射到位数组中的位置比较随机。可以看到误判率也是由于hash碰撞导致的。随着存入的元素数量增加,误判率随之增加。

布隆过滤器在添加key时,会使用多个hash函数计算,每个hash函数都会得到一个在位数组中不同的位置,再把位数组的这几个位置置为1,便完成了add操作。
布隆过滤器在查询key是否存在时,也会通过hash函数把key的几个位置都算出来,再判断这几个位置是否都为1,只要有一个位置为0,那么就说明这个key不存在。如果几个位置都为1,也不一定能够说明该key一定存在,只是极有可能存在。
移除集合中的元素这个在布隆过滤器中是不允许的,理解原理我们就知道,如果将是1的位置重置成0会影响其他元素是不是在集合中的判断。我们很容易想到把位数组变成整数数组,每插入一个元素相应的计数器加 1, 这样删除元素时将计数器减掉就可以了。然而要保证安全地删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
错误率
错误率有两种:
FP = false positive
FN = false negative
对应Bloom Filter的情况下,FP就是「集合里没有某元素,查找结果是有该元素」即误判,FN就是「集合里有某元素,查找结果是没有该元素」。FN显然总是0,FP会随着Bloom Filter中插入元素的数量而增加——极限情况就是所有bit都为1,这时任何元素都会被认为在集合里。
假设 Hash 函数以等概率条件选择并设置 Bit Array 中的某一位,假定由每个 Hash 计算出需要设置的位(bit) 的位置是相互独立, m 是该位数组的大小,k 是 Hash 函数的个数.
-
位数组中某一特定的位在进行元素插入时的 Hash 操作中没有被置位的概率是:
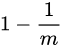
-
在所有 k 次 Hash 操作后该位都没有被置 “1” 的概率是:
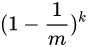
-
如果我们插入了 n 个元素,那么某一位仍然为 “0” 的概率是:
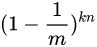
-
该位为 "1"的概率是:
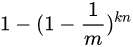
检测某一元素是否在该集合中。标明某个元素是否在集合中所需的 k 个位置都按照如上的方法设置为 “1”,但是该方法可能会使算法错误的认为某一原本不在集合中的元素却被检测为在该集合中(False Positives),该概率由以下公式确定:
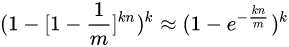
所以在实际使用时,随着添加的元素数量的增加,可以通过增大位数组大小、增加多个hash函数来降低误判率。
使用
bf.add
添加元素到指定键键的布隆过滤器。
如果键不存在先创建键。
返回1表示元素添加成功
0表示元素已经存在本次不添加
用法 bf.add key element
bf.exists
解释
判断元素是否存在于键的类型为布隆过滤器中
1: 存在
0: 不存在
用法 bf.exists key element
bf.reserve
在 redis 中有两个值决定布隆过滤器的准确率:
error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。
initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
[大杀器]布谷鸟过滤器
相比布谷鸟过滤器,布隆过滤器有以下不足:查询性能弱、空间利用效率低、不支持反向操作(删除)以及不支持计数。
-
查询性能弱是因为布隆过滤器需要使用多个 hash 函数探测位图中多个不同的位点,这些位点在内存上跨度很大,会导致 CPU 缓存行命中率低。
-
空间效率低是因为在相同的误判率下,布谷鸟过滤器的空间利用率要明显高于布隆,空间上大概能节省 40% 多。不过布隆过滤器并没有要求位图的长度必须是 2 的指数,而布谷鸟过滤器必须有这个要求。从这一点出发,似乎布隆过滤器的空间伸缩性更强一些。
-
不支持反向删除操作这个问题着实是击中了布隆过滤器的软肋。在一个动态的系统里面元素总是不断的来也是不断的走。布隆过滤器就好比是印迹,来过来就会有痕迹,就算走了也无法清理干净。比如你的系统里本来只留下 1kw 个元素,但是整体上来过了上亿的流水元素,布隆过滤器很无奈,它会将这些流失的元素的印迹也会永远存放在那里。随着时间的流失,这个过滤器会越来越拥挤,直到有一天你发现它的误判率太高了,不得不进行重建。
布谷鸟过滤器在论文里声称自己解决了这个问题,它可以有效支持反向删除操作。而且将它作为一个重要的卖点,诱惑大家放弃布隆过滤器改用布谷鸟过滤器。
为啥要取名布谷鸟呢?
有个成语,「鸠占鹊巢」,布谷鸟也是,布谷鸟从来不自己筑巢。它将自己的蛋产在别人的巢里,让别人来帮忙孵化。待小布谷鸟破壳而出之后,因为布谷鸟的体型相对较大,它又将养母的其它孩子(还是蛋)从巢里挤走 —— 从高空摔下夭折了。
最简单的布谷鸟哈希结构是一维数组结构,会有两个 hash 算法将新来的元素映射到数组的两个位置。如果两个位置中有一个位置为空,那么就可以将元素直接放进去。但是如果这两个位置都满了,它就不得不「鸠占鹊巢」,随机踢走一个,然后自己霸占了这个位置。
p1 = hash1(x) % size
p2 = hash2(x) % size
比布谷鸟负责任的是,布谷鸟哈希算法会帮这些受害者(被挤走的蛋)寻找其它的窝。因为每一个元素都可以放在两个位置,只要任意一个有空位置,就可以塞进去。所以这个被挤走的蛋会看看自己的另一个位置有没有空,如果空了,自己挪过去也就皆大欢喜了。但是如果这个位置也被别人占了呢?好,那么它会再来一次「鸠占鹊巢」,将受害者的角色转嫁给别人。然后这个新的受害者还会重复这个过程直到所有的蛋都找到了自己的巢为止。
但是会遇到一个问题,那就是如果数组太拥挤了,连续踢来踢去几百次还没有停下来,这时候会严重影响插入效率。这时候布谷鸟哈希会设置一个阈值,当连续占巢行为超出了某个阈值,就认为这个数组已经几乎满了。这时候就需要对它进行扩容,重新放置所有元素。
还会有另一个问题,那就是可能会存在挤兑循环。比如两个不同的元素,hash 之后的两个位置正好相同,这时候它们一人一个位置没有问题。但是这时候来了第三个元素,它 hash 之后的位置也和它们一样,很明显,这时候会出现挤兑的循环。不过让三个不同的元素经过两次 hash 后位置还一样,这样的概率并不是很高,除非你的 hash 算法太挫了。
布谷鸟哈希算法对待这种挤兑循环的态度就是认为数组太拥挤了,需要扩容(实际上并不是这样)。
优化
上面的布谷鸟哈希算法的平均空间利用率并不高,大概只有 50%。到了这个百分比,就会很快出现连续挤兑次数超出阈值。这样的哈希算法价值并不明显,所以需要对它进行改良。
改良的方案之一是增加 hash 函数,让每个元素不止有两个巢,而是三个巢、四个巢。这样可以大大降低碰撞的概率,将空间利用率提高到 95%左右。
另一个改良方案是在数组的每个位置上挂上多个座位,这样即使两个元素被 hash 在了同一个位置,也不必立即「鸠占鹊巢」,因为这里有多个座位,你可以随意坐一个。除非这多个座位都被占了,才需要进行挤兑。很明显这也会显著降低挤兑次数。这种方案的空间利用率只有 85%左右,但是查询效率会很高,同一个位置上的多个座位在内存空间上是连续的,可以有效利用 CPU 高速缓存。
所以更加高效的方案是将上面的两个改良方案融合起来,比如使用 4 个 hash 函数,每个位置上放 2 个座位。这样既可以得到时间效率,又可以得到空间效率。这样的组合甚至可以将空间利用率提到高 99%,这是非常了不起的空间效率。
布谷鸟过滤器
布谷鸟过滤器和布谷鸟哈希结构一样,它也是一维数组,但是不同于布谷鸟哈希的是,布谷鸟哈希会存储整个元素,而布谷鸟过滤器中只会存储元素的指纹信息(几个bit,类似于布隆过滤器)。这里过滤器牺牲了数据的精确性换取了空间效率。正是因为存储的是元素的指纹信息,所以会存在误判率,这点和布隆过滤器如出一辙。
首先布谷鸟过滤器还是只会选用两个 hash 函数,但是每个位置可以放置多个座位。这两个 hash 函数选择的比较特殊,因为过滤器中只能存储指纹信息。当这个位置上的指纹被挤兑之后,它需要计算出另一个对偶位置。而计算这个对偶位置是需要元素本身的,我们来回忆一下前面的哈希位置计算公式。
fp = fingerprint(x)
p1 = hash1(x) % size
p2 = hash2(x) % size
我们知道了 p1 和 x 的指纹,是没办法直接计算出 p2 的。
特殊的 hash 函数
布谷鸟过滤器巧妙的地方就在于设计了一个独特的 hash 函数,使得可以根据 p1 和 元素指纹 直接计算出 p2,而不需要完整的 x 元素。
fp = fingerprint(x)
p1 = hash(x)
p2 = p1 ^ hash(fp) // 异或
从上面的公式中可以看出,当我们知道 fp 和 p1,就可以直接算出 p2。同样如果我们知道 p2 和 fp,也可以直接算出 p1 —— 对偶性。
p1 = p2 ^ hash(fp)
所以我们根本不需要知道当前的位置是 p1 还是 p2,只需要将当前的位置和 hash(fp) 进行异或计算就可以得到对偶位置。而且只需要确保 hash(fp) != 0 就可以确保 p1 != p2,如此就不会出现自己踢自己导致死循环的问题。
为什么要对“指纹”进行一个 hash 计算之后,再进行异或运算呢?
论文中给出了一个反证法:如果不进行 hash 计算,假设“指纹”的长度是 8bit,那么其对偶位置算出来,距离当前位置最远也才 256。
为啥,论文里面写了:
因为如果“指纹”的长度是 8bit,那么异或操作只会改变当前位置 h1(x) 的低 8 位,高位不会改变。
就算把低 8 位全部改了,算出来的位置也就是最远 256 位。
所以,对“指纹”进行哈希处理可确保被踢出去的元素,可以重新定位到哈希表中完全不同的存储桶中,从而减少哈希冲突并提高表利用率。
也许你会问为什么这里的 hash 函数不需要对数组的长度取模呢?实际上是需要的,但是布谷鸟过滤器强制数组的长度必须是 2 的指数,所以对数组的长度取模等价于取 hash 值的最后 n 位。在进行异或运算时,忽略掉低 n 位 之外的其它位就行。将计算出来的位置 p 保留低 n 位就是最终的对偶位置。
删除
标准布隆过滤器不能删除,因此删除单个项需要重建整个过滤器,而计数布隆过滤器需要更多的空间。布谷鸟过滤器就像计数布隆过滤器,可以通过从哈希表删除相应的指纹删除插入的项。其他具有类似删除过程的过滤器比布谷鸟过滤器更复杂。例如,d-left计数布隆过滤器必须使用额外的计数器,以防止指纹碰撞1的“假删除”问题,商过滤器必须移动指纹序列去填补删除之后的“空”条目并维持其“桶结构”2。
它检查给定项的两个候选桶;如果任何桶中的指纹匹配,则从该桶中删除匹配指纹的一份副本。
删除不需要在删除项后清除条目。它还避免了两个项共享一个候选桶并具有相同指纹时的“错误删除”问题。 例如,如果项x和y都驻留在桶i1中并在指纹f上碰撞,部分键布谷鸟哈希确保它们也可以驻留在桶i2中,因为i2 = i1 ^ hash(f)。 删除x时,进程是否删除插入x或y时添加的f的副本并不重要。 x删除后, y仍被视为集合成员,因为在任何一个桶i1和i2中都留下了相应的指纹。这样做的一个重要结果是,删除后过滤器的假阳性行为保持不变。(在上面的示例中,表中的y会导致查找x时出现假阳性,根据定义:它们共享相同的桶和指纹。)这是近似集合隶属数据结构的预期假阳性行为,其概率仍以ϵ为界。
请注意,要安全地删除项x,必须事先插入它。否则删除非插入项可能会无意中删除碰巧共享相同指纹的真实、不同的项。这一要求也适用于所有其他支持删除的过滤器。
使用
https://github.com/seiflotfy/cuckoofilter
Ref
《Redis深度历险》