盘点2021年Apache年报中出现的国产项目:ShardingSphere, IoTDB, Carbon Data, Eagle, Kylin【施工中】
1、引言

2021年8 月 31 日,Apache 软件基金会发布 2021 财年(2020 年 5 月 1 日 - 2021 年 4 月 30 日)年度报告,报告内容由 Apache 软件基金会概览、基金会主席报告、财务主管报告、财务报表、资金募集、法律事务、基础设施、安全方面、数据隐私、营销宣传、品牌管理、会议、社区发展、多元化与包容、项目及代码、贡献方面、基金会成员、联系方式等十八个部分组成。
Apache 基金会成立于 1999 年,是世界上最大的开源基金会,管理着 2.27 亿行以上的代码,并且 100% 免费向公众提供价值约 220 亿美元的软件,这些软件几乎是每个用户计算设备上不可或缺的一部分,而开放友好的 Apache License v2 是开源行业标准,帮助了总价值超过数十亿美元的公司,并使全球无数用户受益。
报告中指出,统计周期内共有来自228个国家的用户共4095908 次访问,其中来自于中国的用户数量最多,国内用户成为了Apache项目的主要使用者。
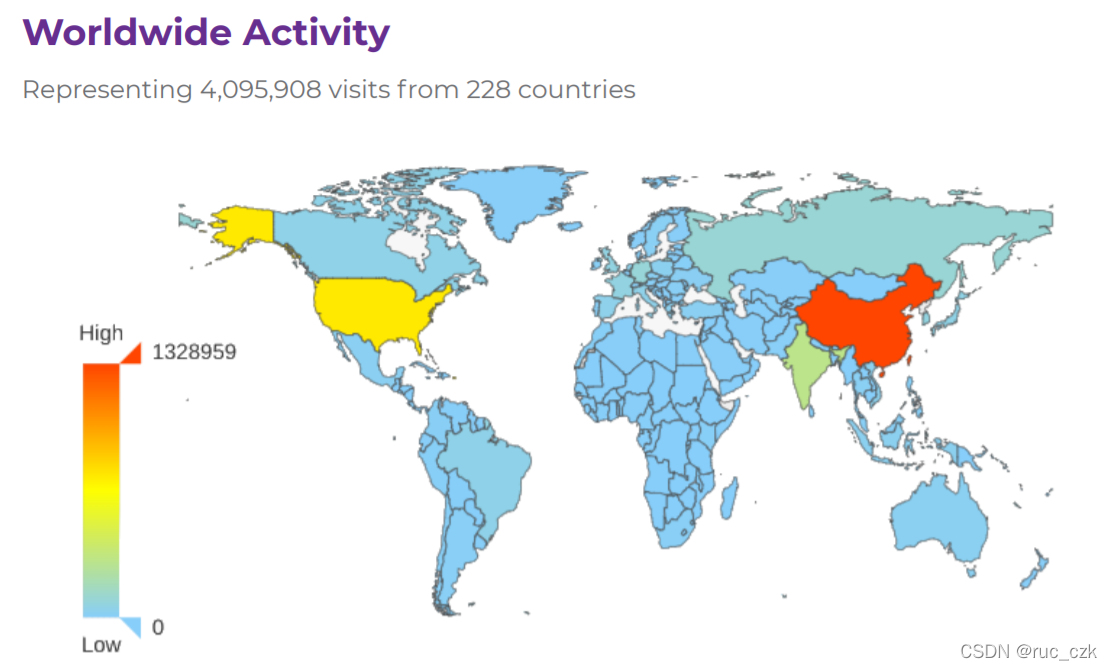
此外,在2020年7 月 15 日,由中国开源软件推进联盟(COPU)主办的2020 第十五届“开源中国开源世界”高峰论坛上,Apache 基金会副主席 Shane Curcuru表示,在过去的 20 年里,Apache 基金会已经从最初的 21 位创始人发展到了 800 多位 Apache 会员,项目提交数量稳步增长,现在已有近 8000 名提交者,这些 Apache 项目中的提交者已经发布了超过 2 亿行代码。尤其值得关注的是,来自中国的新社区和贡献者加入 Apache 项目的速度增长惊人,Shane Curcuru 这样说道:“令人兴奋的是,中国的技术专家和公司如此迅速地采用全球开源技术。现在,不仅帮助 Apache 建立新项目,而且改善开源本身的工作方式,来自中国的整个 Apache 新项目的发展也让人印象深刻。我们目前有 10 个源于中国的顶级项目,其中几个项目非常有名,现在还有 9 个来自中国的 Apache 孵化器项目正在努力成为顶级项目。重要的是,这些 Apache 项目涵盖了从大数据、流媒体到物联网,再到所有涉及云管理的技术领域。”

今天我们来盘点一下有哪些项目在2021年的Apache年报中出现,以及这些项目目前的情况。
2、项目盘点
2.1 ShardingSphere
出现次数:1次
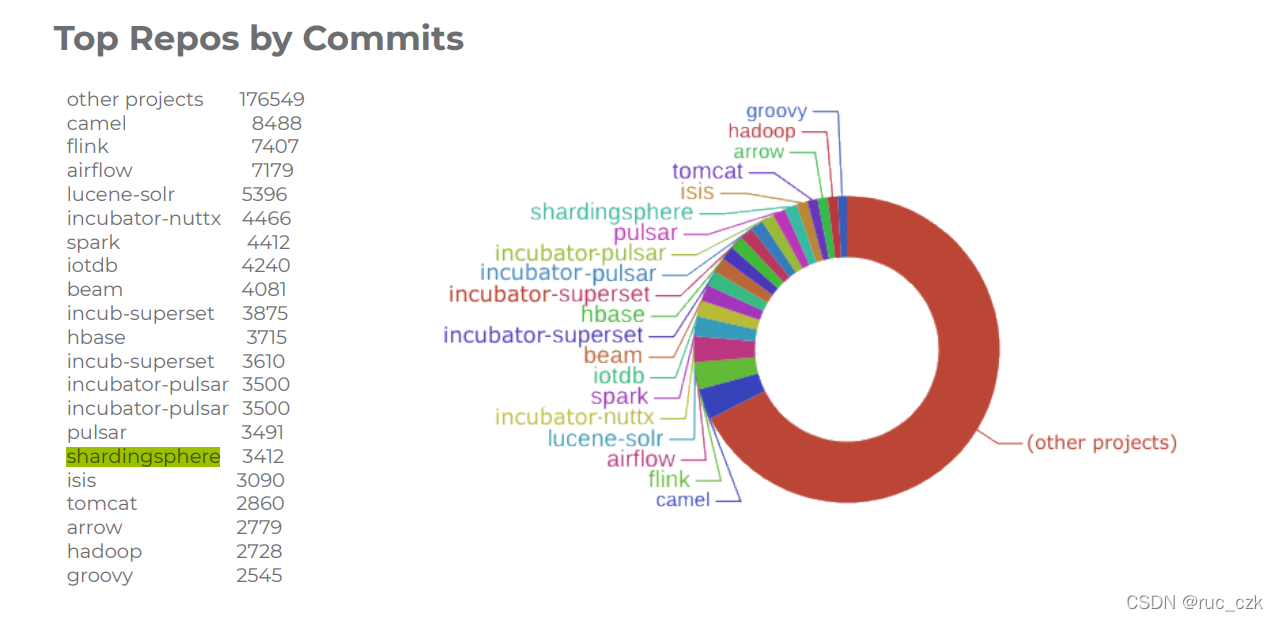
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 3 款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 由三个子项目组成,形成一个完整的数据库解决方案,合称 J.P.S. 生态系统。
- ShardingSphere-JDBC:定位为轻量级 Java 框架,在 Java 的 JDBC层提供额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC
驱动,完全兼容JDBC 和各种 ORM 框架。- ShardingSphere-Proxy:定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。目前提供MySQL/PostgreSQL
版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端操作数据,对 DBA 更加友好。- ShardingSphere-Sidecar(TODO):定位为 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问。通过无中心、零侵入的方案提供与数据库交互的的啮合层,即 Database Mesh,又可称数据网格。
Apache ShardingSphere 的亮点主要包括:
- 完整的分布式数据库解决方案:提供数据分片、分布式事务、数据弹性迁移、数据库和数据治理等核心能力。
- 独立的 SQL 解析引擎:支持多 SQL 方言的完全独立化 SQL 解析引擎,能够脱离ShardingSpher独立使用。
- 可插拔微内核:所有的 SQL 方言、数据库协议和功能都能够通过 SPI的可插拔方式加载或卸载,微内核甚至在未来可以运行于无任何功能的空白环境中。
有关ShardingSphere的孵化过程以及更多的信息可以访问:GitHub 标星 10,000+,Apache 顶级项目 ShardingSphere 的开源之路
2.2 IoTDB
出现次数:2次
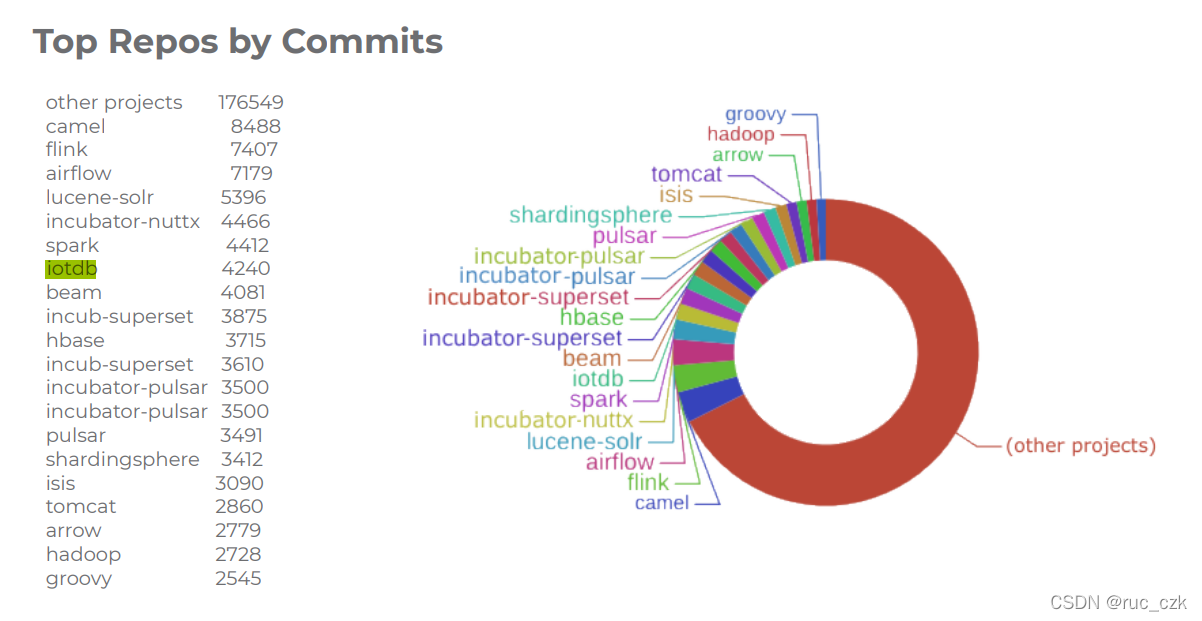

IoTDB 是一款聚焦工业物联网、高性能轻量级的时序数据管理系统,具备低存储成本、高速数据写入(百万数据点秒级写入)、快速查询(TB级数据毫秒级查询)、功能完备(数据的增删改查、丰富的聚合函数、相似性匹配)、查询分析一体化(一份数据,满足实时查询与分析挖掘)、简单易用(采用标准的 JDBC 接口、类 SQL 查询语言)等特点。
基准测试表明IoTDB读写性能均优于现有的时序数据库InfluxDB、OpenTSDB、Cassandra以及GE的工业大数据平台Predix。根据中国软件评测中心和中国人民大学的性能对标测试,IoTDB的各项性能指标均明显优于当今国际最优的时序数据库系统。
IoTDB 已通过 Apache 基金会孵化器的讨论并获得10票赞成。Apache 孵化器主席Justin Mclean、国际著名大数据公司 HortonWorks 副总裁 Joe Witt、Apache PLC4X 项目负责人 Christofer Dutz、华为开源中心负责人姜宁成为本项目的指导者。2018年11月18日,IoTDB项目正式成为 Apache孵化器项目,这是我国高校目前唯一一个进入Apache孵化器的项目*。
【*目前Apache IoTDB已从Apache基金会毕业,成为Apache顶级项目,见Apache Blog】
以上内容摘自:欢迎加入 Apache IoTDB!
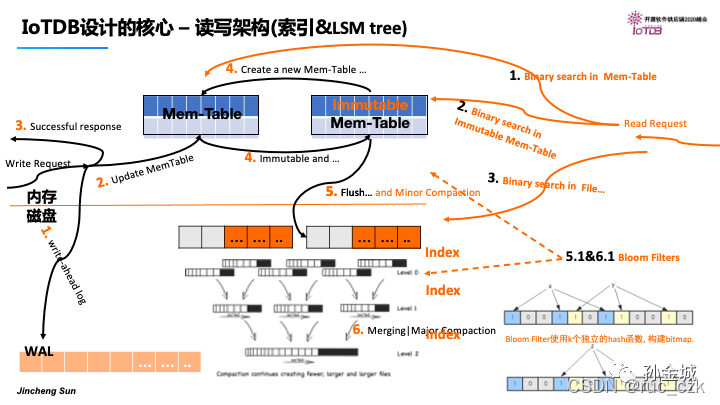
Apache IoTDB的核心技术:【from Apache IoTDB 随笔 - IoTDB核心技术剖析】
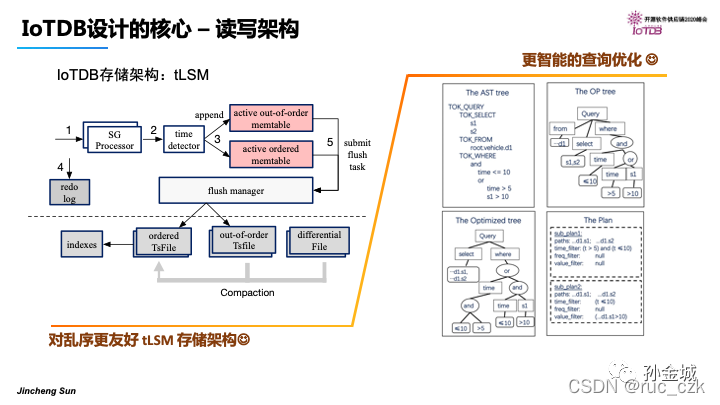
2.3 Carbon Data
出现次数:1次
 Apache CarbonData是一种新的大数据文件格式,使用先进的柱状存储、索引、压缩和编码技术来提高计算效率,这有助于在pb级的数据上以数量级的速度加快查询速度。
Apache CarbonData是一种新的大数据文件格式,使用先进的柱状存储、索引、压缩和编码技术来提高计算效率,这有助于在pb级的数据上以数量级的速度加快查询速度。
CarbonData特别设计了多种优化策略,如多级索引、压缩和编码技术,旨在提高包含filter、aggregation和counst distinct等分析查询的性能,用户期望在拥有较少节点的商用集群上获得对TB级别数据的亚秒级响应。
CarbonData具有以下优点:
-
独特的数据组织形式:以获得更快的查询性能及更少的数据检索成本
-
进一步的下推优化策略:与Spark进行深度集成,以改进Spark DataSource
API和其他实验特性,从而确保计算在接近数据的地方执行,从而最大限度地减少数据的读、处理、转换和传输(shuffle) -
多级索引:有效地修剪要扫描的文件和数据,从而减少I/O扫描和CPU处理
-
CarbonData文件格式如图所示。
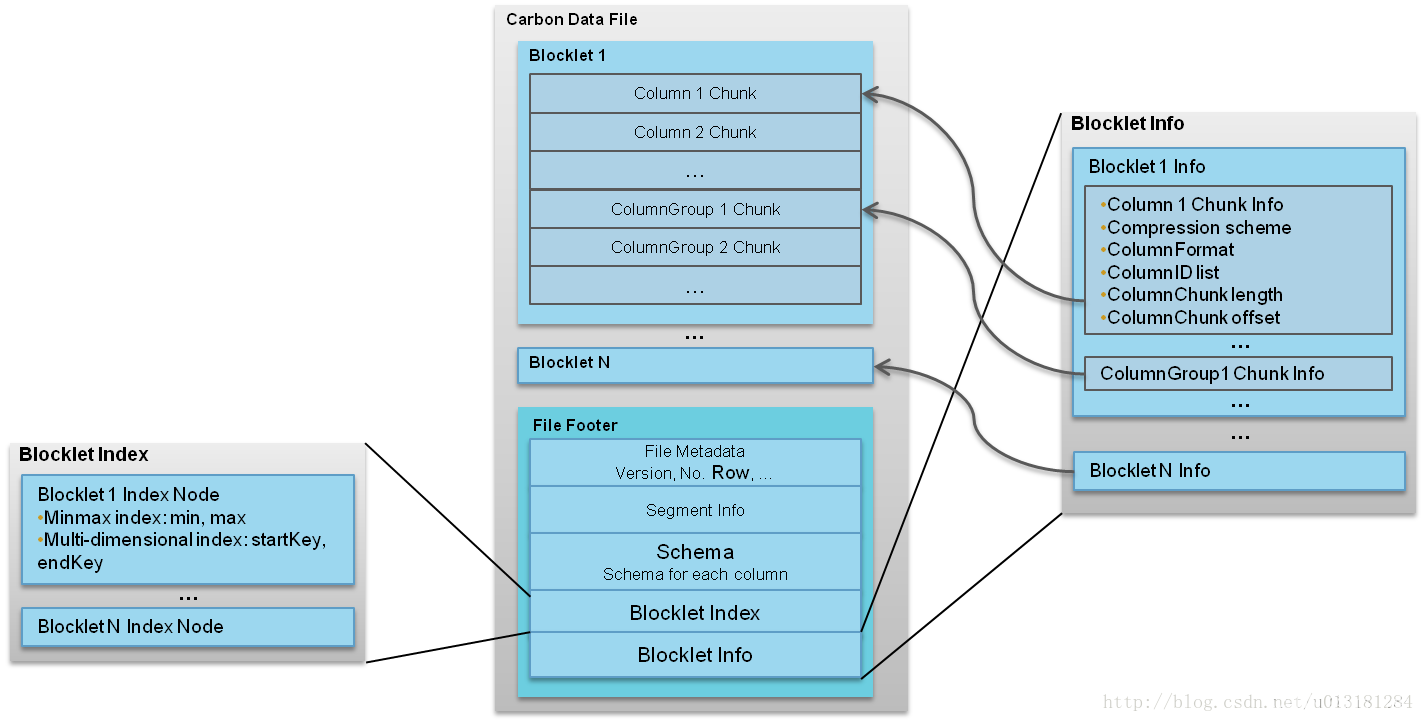
以上内容引用自carbondata 介绍
2.4 Eagle
出现次数:1次
Apache Eagle 是由 eBay 公司开源的一个识别大数据平台上的安全和性能问题的开源解决方案。该项目于2017年1月10日正式成为 Apache 顶级项目。 Apache Eagle 提供一套高效分布式的流式策略引擎,具有高实时、可伸缩、易扩展、交互友好等特点,同时集成机器学习对用户行为建立Profile以实现实时智能实时地保护 Hadoop 生态系统中大数据的安全。
Apache Eagle 主要包括三大层:
- 数据收集及存储层(Data Collection and Storage)
- 数据处理层(Data Processing)
- 可视化层(Visualize)
整个组成如下:
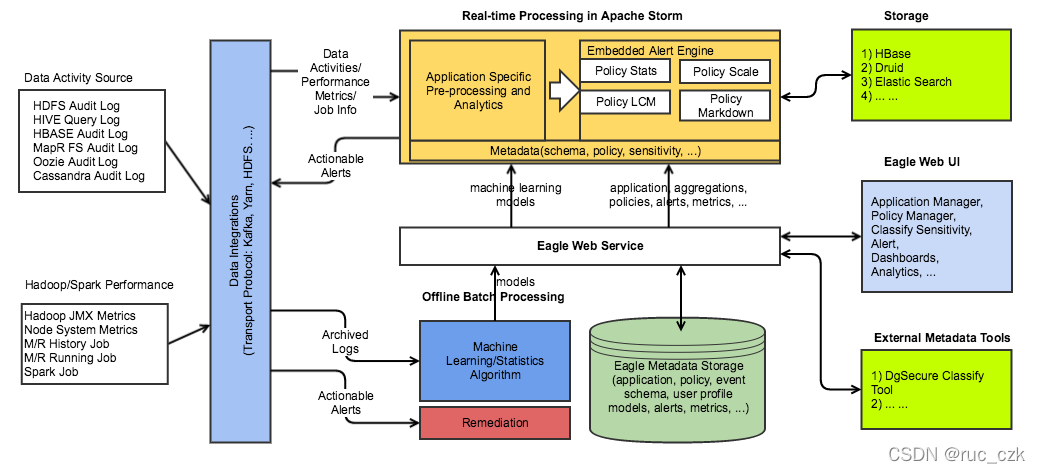
Apache Eagle 依赖于 Apache Storm 来进行数据活动和操作日志的流处理,并且可以执行基于策略的检测和报警。它提供多个API:作为基于Storm API上的一层抽象的流式处理API和 policy engine provider API的抽象,它将WSO2的开源Siddhi CEP engine作为第一类对象。Siddhi CEP engine支持报警规则的热部署,并且警报可以使用属性过滤和基于窗口的规则(例如,在10分钟内三次以上的访问)来定义。
Eagle 支持根据用户在Hadoop平台上历史使用行为习惯来定义行为模式或用户Profile的能力。拥有了这个功能,不需要在系统中预先设置固定临界值的情况下,也可以实现智能地检测出异常的行为。Eagle中用户Profile是通过机器学习算法生成,用于在用户当前实时行为模式与其对应的历史模型模式存在一定程度的差异时识别用户行为是否为异常。目前,Eagle 内置提供以下两种算法来检测异常,分别为特征值分解(Eigen-Value Decomposition)和 密度估计(Density Estimation)。这些算法从HDFS 审计日志中读取数据,对数据进行分割、审查、交叉分析,周期性地为每个用户依次创建Profile 行为模型。一旦模型生成,Eagle的实时流策略引擎能够近乎实时地识别出异常,分辨当前用户的行为可疑的或者与他们的历史行为模型不相符。
2.5 Kylin
出现次数:1次

Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
KylinJ架构图为
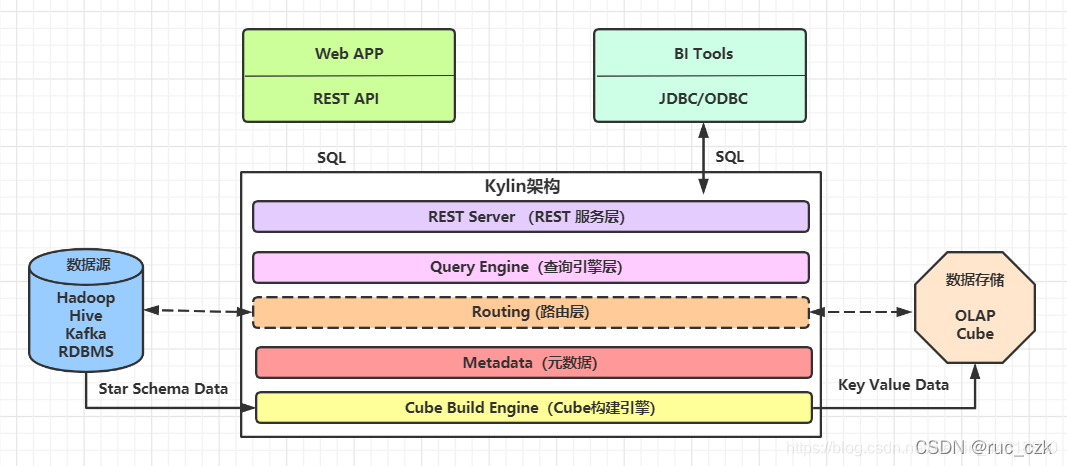
Apache Kylin核心概念
- 表(table):This is definition of hive tables as source of cubes,在build cube 之前,必须同步在 kylin中。
- 模型(model):模型描述了一个星型模式的数据结构,它定义了一个事实表(Fact Table)和多个查找表(Lookup Table)的连接和过滤关系。
- Cube 描述:描述一个Cube实例的定义和配置选项,包括使用了哪个数据模型、包含哪些维度和度量、如何将数据进行分区、如何处理自动合并等等。
- Cube实例:通过Cube描述Build得到,包含一个或者多个Cube Segment。
- 分区(Partition):用户可以在Cube描述中使用一个DATA/STRING的列作为分区的列,从而将一个Cube按照日期分割成多个segment。
- 立方体段(cube segment):它是立方体构建(build)后的数据载体,一个 segment 映射hbase中的一张表,立方体实例构建(build)后,会产生一个新的segment,一旦某个已经构建的立方体的原始数据发生变化,只需刷新(fresh)变化的时间段所关联的segment即可。
- 聚合组:每一个聚合组是一个维度的子集,在内部通过组合构建cuboid。
- 作业(job):对立方体实例发出构建(build)请求后,会产生一个作业。该作业记录了立方体实例build时的每一步任务信息。作业的状态信息反映构建立方体实例的结果信息。如作业执行的状态信息为RUNNING时,表明立方体实例正在被构建;若作业状态信息为FINISHED ,表明立方体实例构建成功;若作业状态信息为ERROR,表明立方体实例构建失败!
2.5 APIXSIX
出现次数:1次
