修改字段格式:
alter table 表名 modify 字段名举例如下:
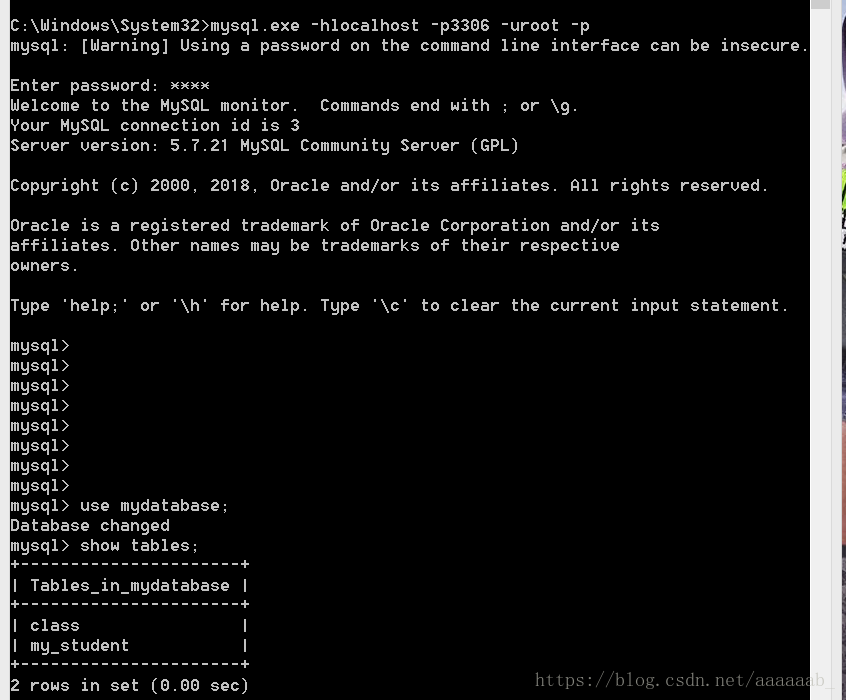
–将学生表中的number学号字段变成固定长度,且放在第二位(id之后)。
desc my_student; 查看表中数据
alter table my_student
modify number char(10) after id;
desc my_student;首先在 cmd环境下登录数据库,进入mydatabase数据库进行操作。
修改字段:
重命名字段
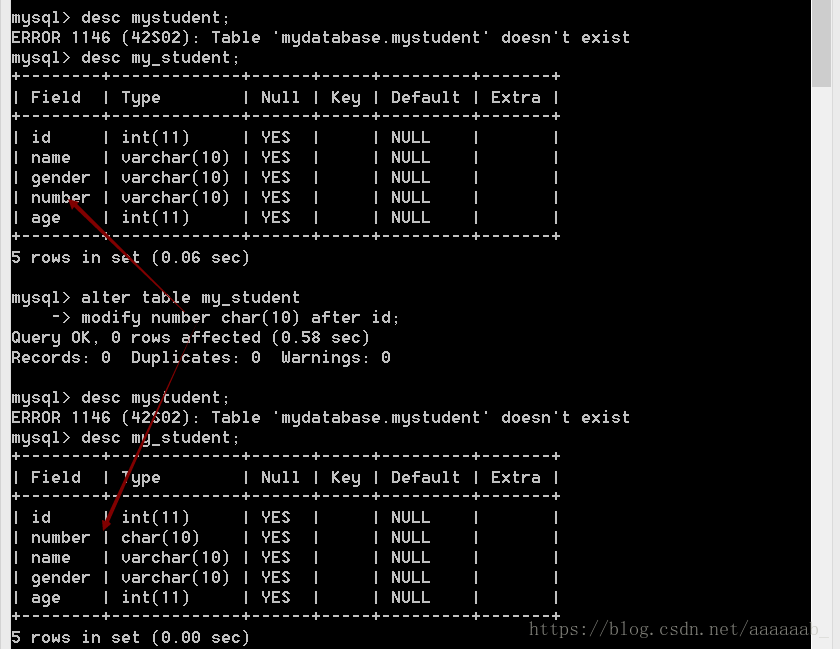
alter table 表名 change 旧字段 新字段名 数据类型 [属性][位置];举例如下:
–修改学生表中的gender字段为sex。
desc my_student;
alter table my_student
change gender sex varchar(10);
desc my_student;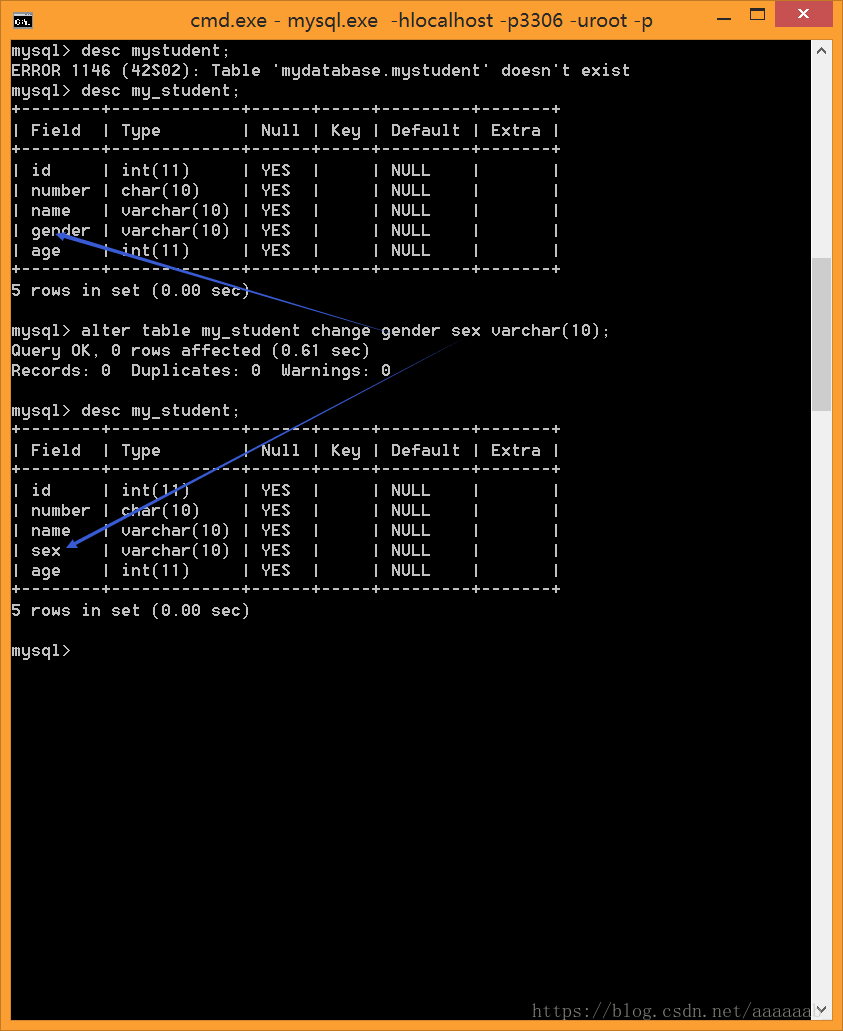
删除字段:
alter table 表名 drop 字段名;–删除学生表中的年龄字段(age)
desc my_student;
alter table my_student drop age;
desc my_student;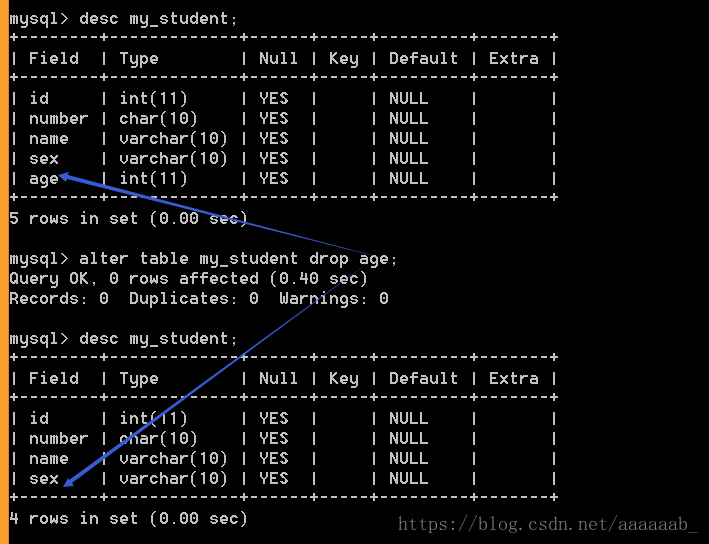
如果表中已经存在数据,那么删除字段会清空该字段的所有数据(不可逆)
删除数据表
drop table 表名1 表名2...;–一次性可以删除多张表,数据库不可以一次性删除多个,因为系统认为这是个危险的操作。
例如:
删除class数据表。
show tables;
drop tables class;
show tables;显示所有表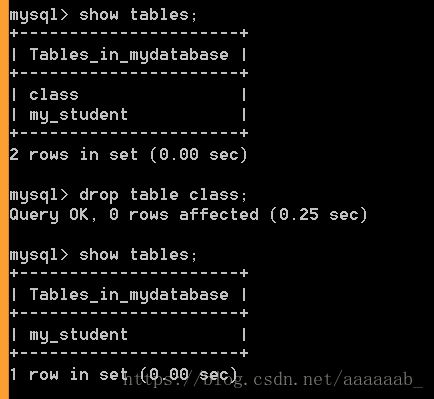
当删除数据表的指令发生时,具体执行了什么?
1、在表空间中,没有了指定的表(数据也相应没有了)。
2、在数据库文件夹下面,表对应的文件(与存储引擎有关),也会被删除。
*注意:删除有危险,操作需谨慎(不可逆)*
新增数据:
新增数据有两种方案。
方案一、给全表字段插入数据,不需要指定列表,要求数据的值出现的顺序必须与表中设计出现的字段出现的顺序一致;凡是非数值数据,都需要引号(建立是单引号)包裹。
–可以一次性插入多条记录
insert into 表名 values (值列表)[,(值列表)]; 举例如下:插入数据。
desc my_student;
insert into my_student values(1,'itcast0001','jim','male'),(2,'itcast0002','hanmeimei','female');
select * from my_stydent;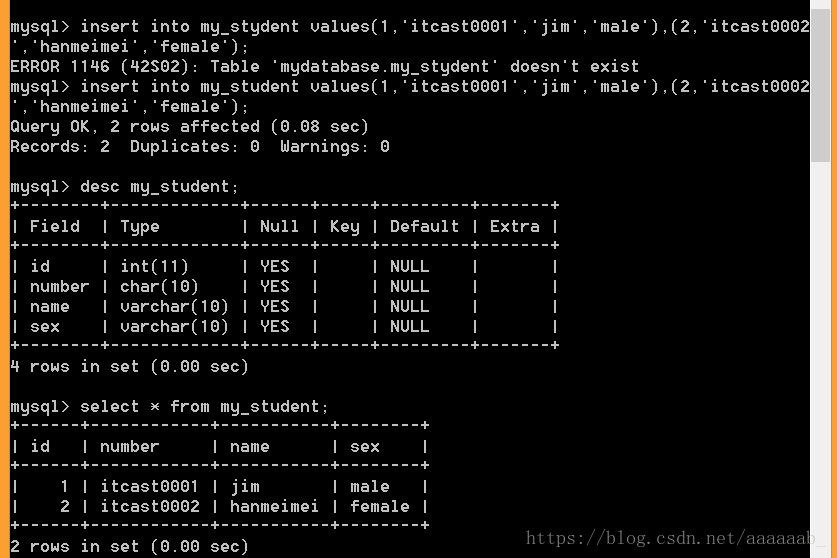
方案二、给部分字段插入数据,需要选定字段列表;字段列表出现的顺序与字段的顺序无关。
但是值列表的顺序必须与选定字段顺序一致。
insert into 表名 (字段列表)values (值列表)[,(值列表)];–插入数据,指定字段列表。
select * from my_student;
insert into my_student (numbers,sex,name,id) values ('itcast0003','male','tom',3),
('itcast0004','female','lily',4);
select * from my_student;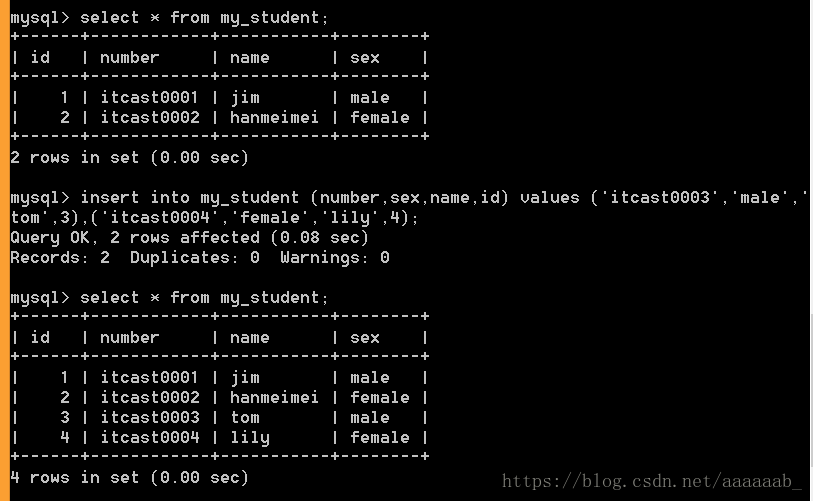
查看数据
select */字段列表 from 表名 [where 条件];查看所有数据:
select * from my_student;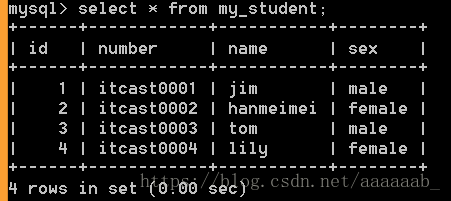
–查看指定字段,指定条件数据。
--查看满足ID为1的数据
select id,number,sex,name from my_student where id=1;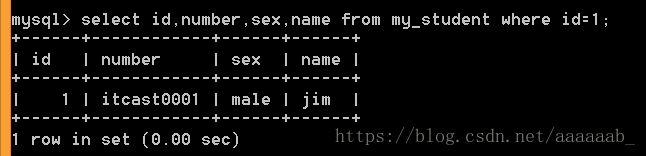
更新数据格式:
update 表名 set 字段=值[where 条件];
--建立都加上where,不然就是更新全部–更新数据,记住更新不一定成功,如果没有真正需要更新的数据,更新的意思在于看有无数据影响。
select * from my_student;
update my_student set sex = 'female' where name='jim';
select * from my_student;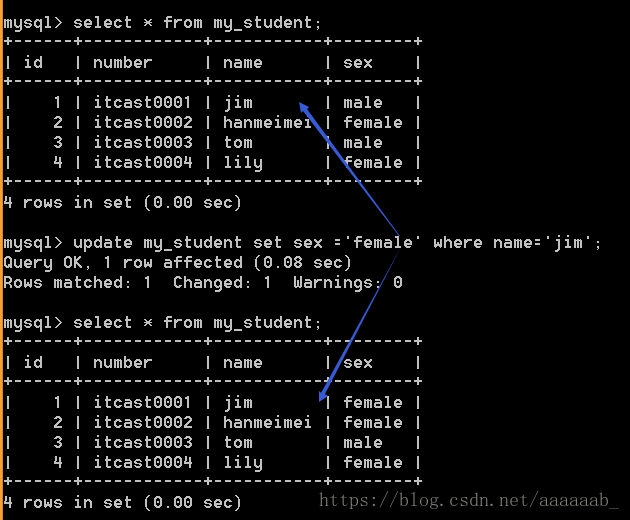
–删除数据,删除是不可逆的,删除有风险,操作需谨慎。
delete from 表名 [where 条件];例如删除男性成员:
select * from my_student;
delete from my_student where sex='male';
select * from my_student;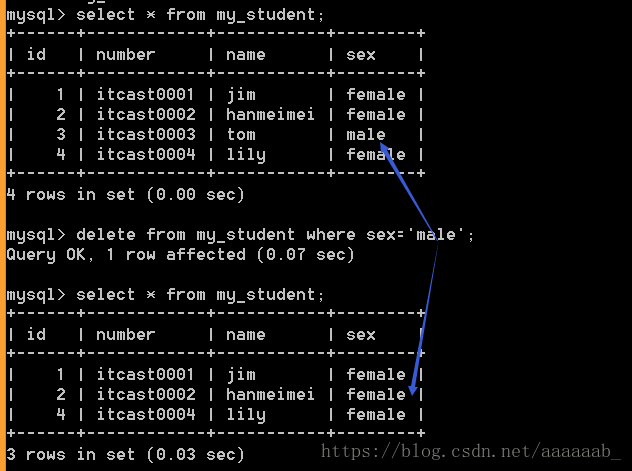
中文数据问题:
中文数据问题本质是字符集问题,计算机只识别二进制,而人类更多的是识别符号,需要有个二进制和字符的对应关系(字符集)。
–插入一组中文数据
insert into my-student values (5,'itcast0005','薛飞龙',‘男’);会报错,客户端向服务端插入中文数据未成功。
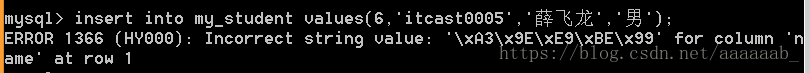
原因:\xA3\x9E\xE9\xBE\x99代表的是”薛飞龙”在当前编码(字符集)下对应的二进制编码转换成的十六进制。两个汉字==》四个字节(GBK)。
报错:服务器没有识别到对应的四个字节,服务器认为数据是utf8,一个汉字有三个字节,读取三个字节转换成汉字(失败),剩余的再读取三个字节(显然就不够了),最终失败。
所有的数据库服务器认为(表现的)一些特殊性都是通过服务器端的变量来保存,系统先读取自己的变量然后看如何表现。
1、//查看服务器到底识别那些字符集。
show character set;
查看所有字符集。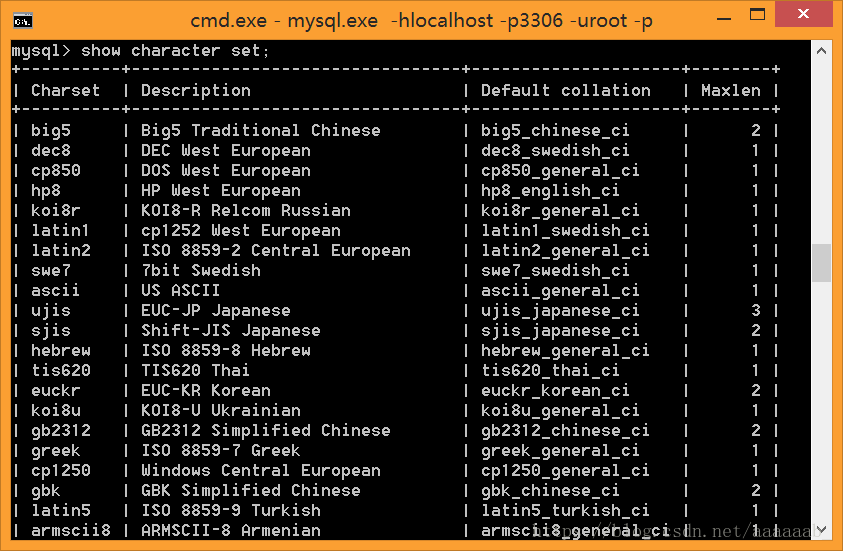
基本上,服务器是万能的什么字符集都支持。
2、//既然服务器识别这么多,总有一种是服务器默认和客户端打交道的字符集。
show variables like 'character_set%';
查看服务器默认的对外处理的字符集。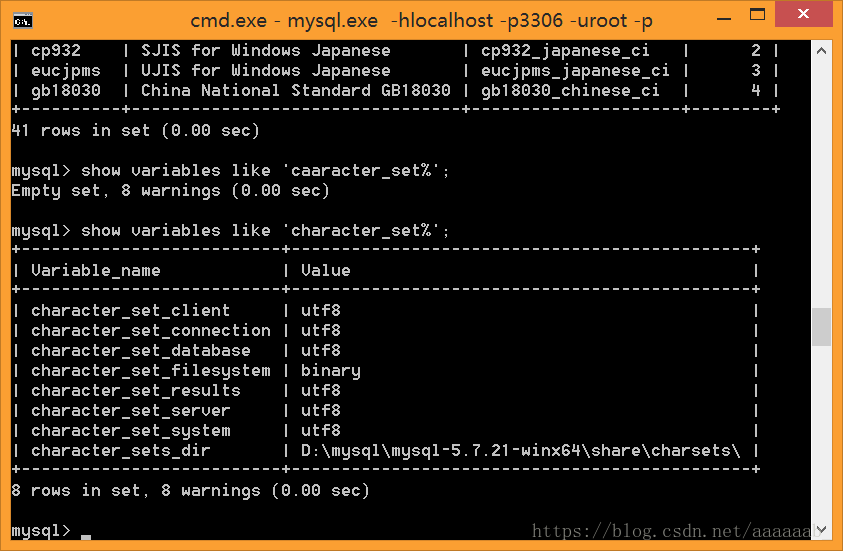
对每一行进行简单的解释:
一、服务器默认的客户端来的数据的字符集UTF8。
二、连接层字符集。
三、当前所在数据库字符集。
四、文件系统。
五、服务器默认的给外部数据的字符集。
八、字符集处理。
报错问题来源:客户端只能是GBK,而服务器认为是UTF8,矛盾产生。
解决方案:改变服务器,默认的接受字符集为GBK。
set character_set_client=gbk;修改服务器认为的客户端数据的字符集为GBK。
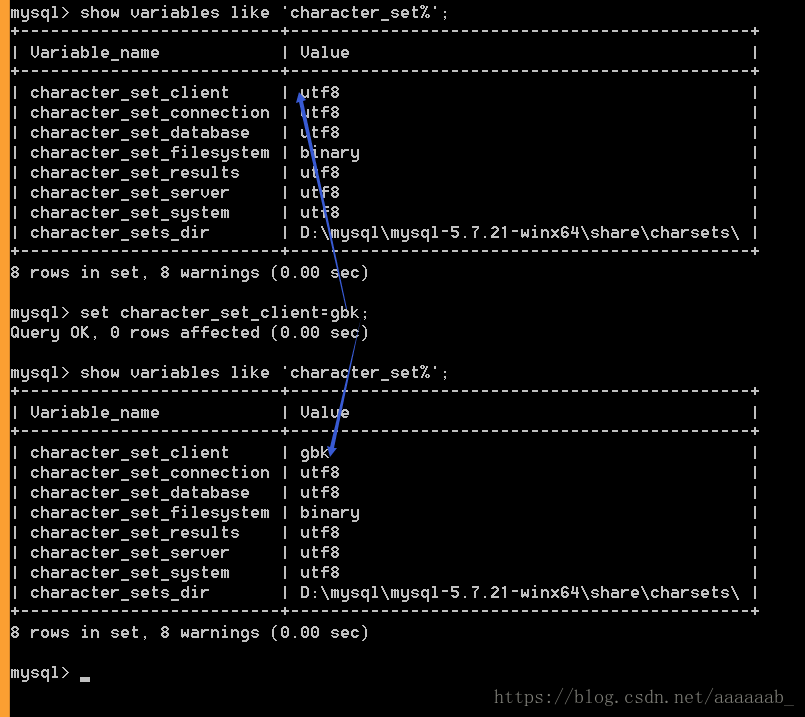
但是插入中文之后仍然会乱码,只是不会报错
原因:数据来源是服务器,解析数据是客户端(客户端只识别GBK,只会两个字节一个汉字),但是事实上服务器给的数据是utf8,三个字节一个汉字,所以会导致乱码。
解决方案:修改服务器给客户端的数据字符集为GBK。
set character_set_results=gbk;
修改给定的数据字符集为GBK。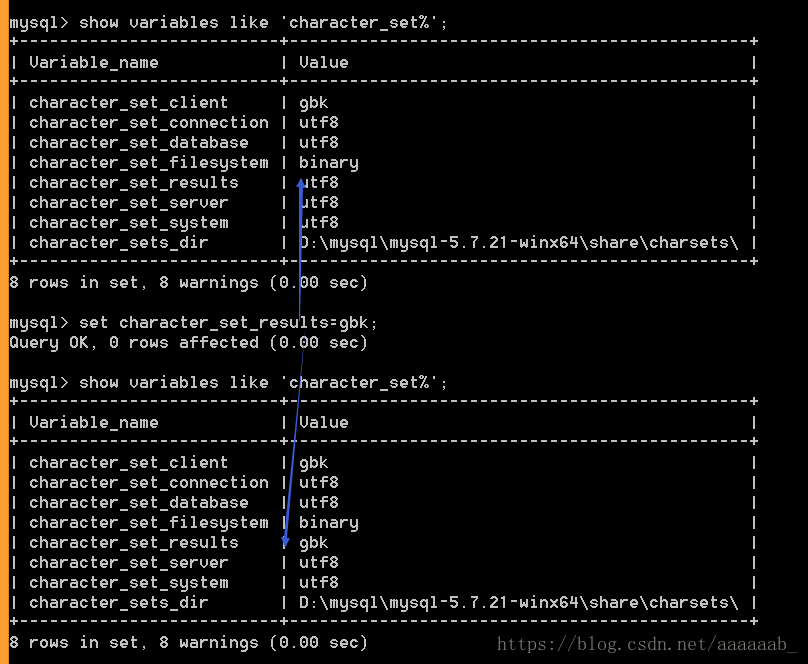
查看数据效果:
set变量=值;修改只是会话级别(当前客户端,当前连接有效,关闭失效)
关闭查看时又变回原来的UTF8,我们可以采用快捷方式设置服务器对客户端的字符集的认知
set names 字符集;set names gbk;会改变三个位置。
1、character_set_client
2、character_set_results
3、character_set_connection
快捷设置字符集
set names gbk;如图所示三个信息进行了更改。
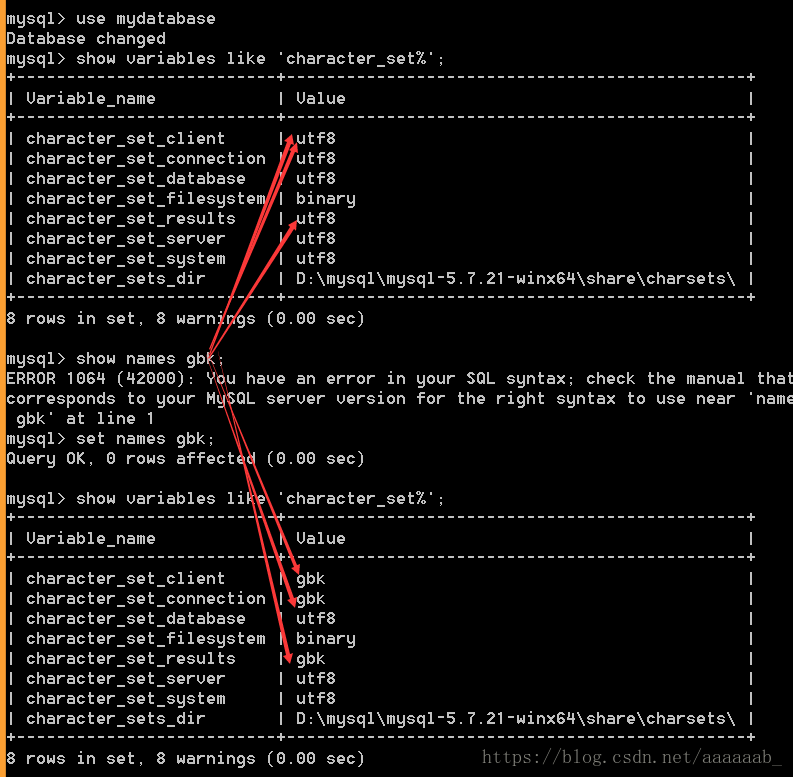
connection连接层:是字符集转变的中间者,如果统一了效率更高,不同意也没有问题。
校对集问题:
校对集:数据比较的方式
校对集有三种格式
_bin:binary,二进制比较,取出二进制位一位一位的比较,区分大小写。
_cs:case sensitive,大小写敏感,区分大小写。
_ci:case insensitive,大小写不敏感,不区分大小写。
查看数据库所支持的校对集:
show collation;
查看所有校对集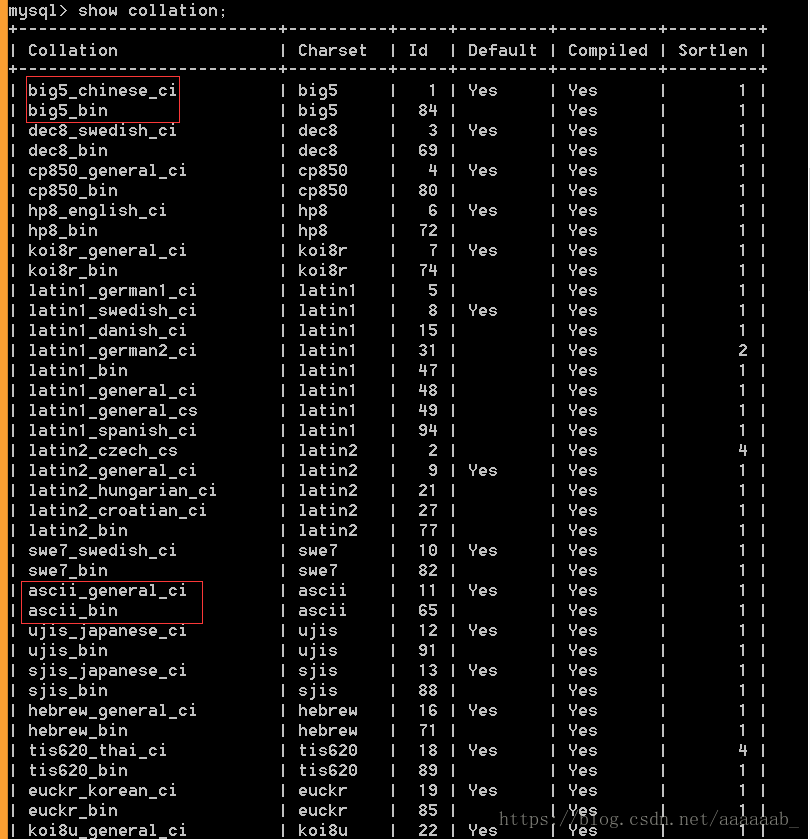
校对集应用:只有当数据产生比较的时候,校对集才会生效。
对比:使用UTF8的_bin和_ci来验证不同的校对集效果。
--创建不同的校对集
create table my_collate_bin(
name char(1)
)charset utf8 collate utf8-bin;
create table my_collate_ci(
name char(1)
)charset utf8 collate utf8_general_ci;
--插入数据
insert into my_collate_bin values ('a'),('A'),('B'),('b');
insert into my_collate_ci values ('a'),('A'),('B'),('b');
--查看
select * from my_collate_bin;
select * from my_collate_ci;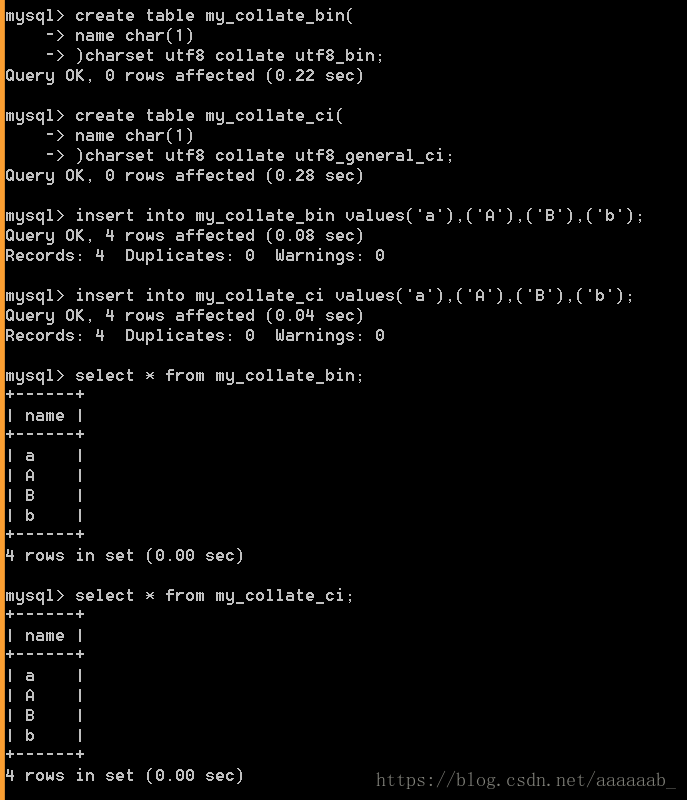
比较,根据某个字段进行排序:order by 字段名 [asc|desc];asc升序,desc降序,默认是升序。
–排序查找
select * from my_collate_bin order by name;
区分大小写,顺序按照ascll码顺序改变。
select * from my_collate_ci order by name;
不区分大小写,不改变。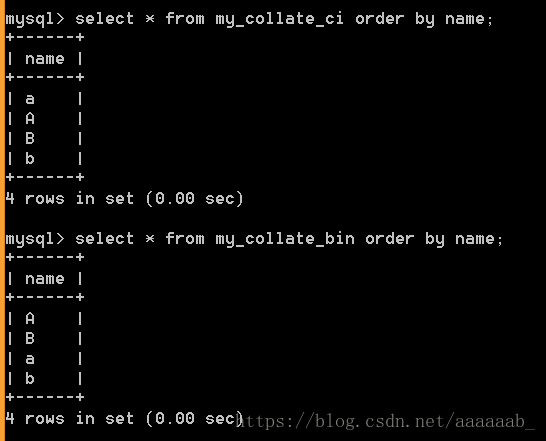
校对集:必须在没有数据之前申明好,如果有了数据,那么再对校对集进行修改,则修改无效。
–有数据后修改校对集
alter table my_collate_ci collate=utf8_bin;
select * from my_collate_ci order by name;查看时候还是没有变化。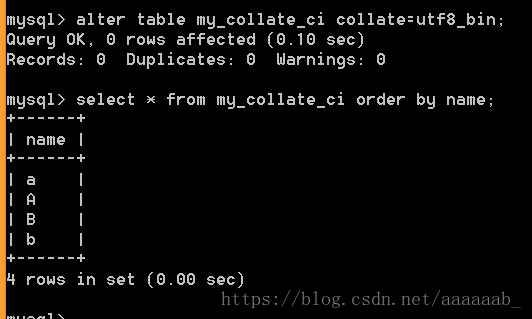
我们将其改回来:
alter table my_collate_ci collate=utf8_general_ci;
乱码问题:
WEB乱码问题:
动态网络由三部分组成:浏览器,阿帕奇(Apache)服务器(PHP),数据库服务器,三个部分都有自己的字符集(中文),数据需要在三个部分之间来回传递,很容易产生乱码。
解决方案:统一编码(三码合一)
但是事实上不可能:浏览器是用户管理(根本不可能控制),但是必须要解决这些问题,主要靠PHP操作。图解所示:
