1、分区表支持hash分区和range分区,根据主键列上的分区模式将table划分为 tablets 。每个 tablet 由至少一台 tablet server提供。理想情况下,一张table分成多个tablets分布在不同的tablet servers ,以最大化并行操作。
2、Kudu目前没有在创建表之后拆分或合并 tablets 的机制。
3、创建表时,必须为表提供分区模式。
4、在设计表格时,使用主键,就可以将table分为以相同速率增长的 tablets 。
5、您可以使用 Impala 的 PARTITION BY 关键字对表进行分区,该关键字支持 RANGE 或 HASH分发。分区方案可以包含零个或多个 HASH 定义,后面是可选的 RANGE 定义。 RANGE 定义可以引用一个或多个主键列
1、PARTITION BY RANGE ( 按范围划分 )
范围分区使用全序的范围分区键对数据行进行分配。(全序是指,集合中的任两个元素之间都可以比较的关系。比如实数中的任两个数都可以比较大小,那么“大小”就是实数集的一个全序关系。)
每个分区都是根据范围分区键分配的连续段。范围分区键必须是主键的子集。
如果表只存在范围分区,不存在散列分区,则每个分区恰好对应一个tablet。

优点:允许根据所选分区键的特定值或值的范围拆分表。这样可以平衡并行写入与扫描效率
缺点:如果您在其值单调递增的列上按范围进行分区,则最后一个tablet的增长将远大于其他的,此外,插入的所有数据将一次写入单个 tablet ,限制了数据摄取的可扩展性
例子:
CREATE TABLE customers (
state STRING,
name STRING,
purchase_count int,
PRIMARY KEY (state, name)
) PARTITION BY RANGE (state) (
PARTITION VALUE = 'al',
PARTITION VALUE = 'ak',
PARTITION VALUE = 'ar',
PARTITION VALUE = 'wv',
PARTITION VALUE = 'wy'
) STORED AS KUDU
TBLPROPERTIES(
'kudu.table_name' = 'customers ','kudu.master_addresses' = 'hadoop1:7051');2、PARTITION BY HASH ( 哈希分区 )
散列分区是根据hash值把行数据分配到某个buckets里面。如果只是一层hash,则一个bucket对应一个tablet。
buckets的数量是在创建表的时候指定的。
散列分区使用的分区列是主键列,同范围分区,可以使用主键列的任意子集做分区。
散列分区是一种高效的策略,当不需要要有序的访问表的时候。
散列分区对在tablet之间的随机写入非常有效,这样有助于缓解tablet的热点问题和数据分布不均匀的问题。
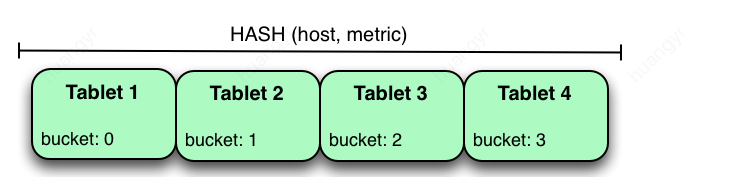
优点:数据均匀地分布在数据桶之间
缺点:对值的查询可能要读取所有的tablet,也就是自定义的3个
例子:
CREATE TABLE cust_behavior (
id BIGINT,
sku STRING,
salary STRING,
edu_level INT,
usergender STRING,
group STRING,
city STRING,
postcode STRING,
last_purchase_price FLOAT,
last_purchase_date BIGINT,
category STRING,
rating INT,
fulfilled_date BIGINT,
PRIMARY KEY (id, sku)
)
PARTITION BY HASH PARTITIONS 3
STORED AS KUDU
TBLPROPERTIES(
'kudu.table_name' = 'cust_behavior ','kudu.master_addresses' = 'hadoop1:7051');3、高级分区:PARTITION BY HASH and RANGE
kudu允许在一个表中指定多级分区。零个或多个散列分区级别可以和可选的范围分区级别组合。多级分区与单个分区的区别是增加了约束条件,多级散列分区不能散列相同的列。(存在多级散列分区时候,各个散列分区计算散列值使用的列不能一样)如果使用正确,多级分区可以保留各个分区类型的好处,同时减少每个分区类型的缺点。多级分区表中的tablet总数是每个级别中分区数的乘积。

优点:既可以数据分布均匀,又可以在每个分片中保留指定的数据
例子:
CREATE TABLE cust_behavior_1 (
id BIGINT,
sku STRING,
salary STRING,
edu_level INT,
usergender STRING,
group STRING,
city STRING,
postcode STRING,
last_purchase_price FLOAT,
last_purchase_date BIGINT,
category STRING,
rating INT,
fulfilled_date BIGINT,
PRIMARY KEY (id, sku)
)
PARTITION BY HASH (id) PARTITIONS 4,
RANGE (sku)
(
PARTITION VALUES < 'g',
PARTITION 'g' <= VALUES < 'o',
PARTITION 'o' <= VALUES < 'u',
PARTITION 'u' <= VALUES
) STORED AS KUDU
TBLPROPERTIES(
'kudu.table_name' = 'cust_behavior_1 ','kudu.master_addresses' = 'hadoop1:7051');