指路《PyTorch深度学习实践》
用pytorch实现线性回归主要包含四个部分:
一、prepare dataset准备好数据集
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
二、Design model using Class 设计模型
'''建立模型'''
class LinearModel(torch.nn.Module):
def __init__(self):
'继承 nn.Module 的神经网络模块在实现自己的 __init__ 函数时,一定要先调用 super().__init__()。'
'只有这样才能正确地初始化自定义的神经网络模块'
super(LinearModel, self).__init__()
'class torch.nn.Linear(in_features,out_features,bias=True)'
'torch.nn.Linear就是torch.nn计算Linear的类,调用设置:是否有b以及input、output的维度'
'bias=True是默认的,如果没有b时设置为False'
'in_features是指输入的维度'
'out_features是指输出的维度'
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
'送入x,然后用linear计算y_pred'
return y_pred
'实例化,后面可以直接用model(x),将x送入LinearModel进行运算'
model = LinearModel()
“”"
torch.nn是专门为神经网络设计的模块化接口。nn构建于autograd之上,可以用来定义和运行神经网络。nn.Module 其实是 PyTorch 体系下所有神经网络模块的基类。
nn.Module是nn中十分重要的类,包含网络各层的定义及forward方法。
定义自已的网络:
需要继承nn.Module类,并实现forward方法。
一般把网络中具有可学习参数的层放在构造函数__init__()中,
不具有可学习参数的层(如ReLU)可放在构造函数中,也可不放在构造函数中(而在forward中使用nn.functional来代替)
只要在nn.Module的子类中定义了forward函数,backward函数就会被自动实现(利用Autograd)。
在forward函数中可以使用任何Variable支持的函数,毕竟在整个pytorch构建的图中,是Variable在流动。还可以使用
if,for,print,log等python语法.
注:Pytorch基于nn.Module构建的模型中,只支持mini-batch的Variable输入方式,
比如,只有一张输入图片,也需要变成 N x C x H x W 的形式:
input_image = torch.FloatTensor(1, 28, 28)
input_image = Variable(input_image)
input_image = input_image.unsqueeze(0) # 1 x 1 x 28 x 28
三、Construct loss and optimizer构造损失函数和优化器
'''计算损失函数和优化器'''
'class torch.nn.MSELoss(size_average=True,reduce=True)'
criterion = torch.nn.MSELoss(size_average=False)
'model.parameters()可以把模型中的成员参数都找到,如果成员中有相应权重,那么都会将结果加到要训练的参数集合上,lr是学习率'
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
四、Training cycle
'''training cycle'''
for epoch in range(200):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()#将所有权重的梯度归零,在反向传播之前一定要释放梯度
loss.backward()
optimizer.step()#更新权重
代码
import torch
import matplotlib.pyplot as plt
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
epoch_list = []
loss_list = []
for epoch in range(200):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w=', model.linear.weight.item())
print('b=', model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred=', y_test.data)
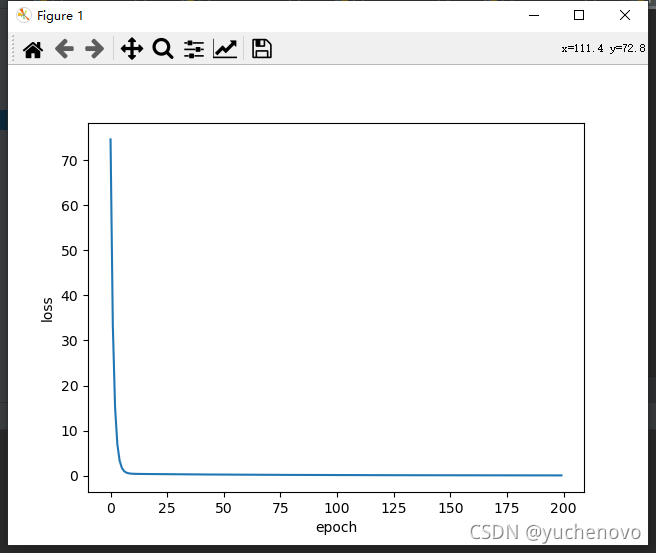
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
结果为:
0 120.76341247558594
1 53.76991271972656
.....
199 0.0009839881677180529
w= 1.9791173934936523
b= 0.04747113212943077
y_pred= tensor([[7.9639]])
Process finished with exit code 0