任务并行是软件中独立任务的执行。在单核处理器上,不同的任务必须共享同一个处理器。在多核处理器上,任务基本上彼此独立运行,从而提高了执行效率
将应用程序映射到多核处理器的第一步是确定任务的并行性并且选择最适合的处理模型
两个主要的模型:
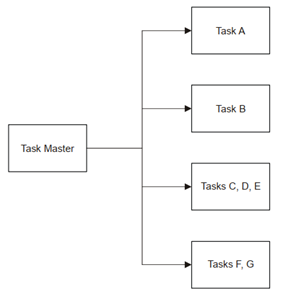
1. 主/从模型:其中一个核控制所有核上的工作分配
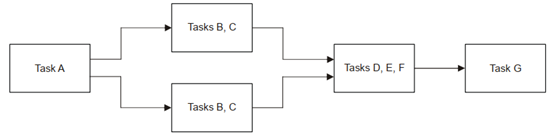
2. 数据流模型:工作像流水线一样通过处理阶段
主/从模型(MASTER/SLAVE MODEL)
主/从模型表示分布式执行的集中控制。主内核负责调度各种执行线程,这些线程可以分配给任何可用的内核进行处理。它还必须将线程所需的任何数据传送到从属核心。适合此模型的应用程序本质上由许多独立的小线程组成,这些线程很容易适应单个核心的处理资源。
使用此模型的应用程序面临的挑战是实时负载平衡,因为线程激活可能是随机的。执行的各个线程可以有非常不同的吞吐量要求。主机必须维护一个可用资源的内核列表,并且能够优化内核之间的工作平衡,从而实现最佳并行性。
主/从任务分配模型表示为如下图:
一个适合主/从模型的应用是通信协议栈的多用户数据链路层。它负责物理层的媒体访问控制核逻辑链路控制,包括复杂的动态调度和通过传输通道的数据移动。软件经常访问多维数组,导致非常不连贯的内存访问。
一个或多个执行线程映射到每个核心。任务分配是通过核心之间的消息传递来实现的。这些消息提供开始执行的控件触发器核指向所需数据的指针。每个核心至少有一个任务,其任务是接收包含作业分配的消息。任务被挂起,直到消息到达触发执行线程。
数据流模型(DATA FLOW MODEL)
数据流模型表示分式控制和执行。每个核心使用各种算法处理一个数据块,然后将数据传递给另一个核心进一步处理。初始核心通常连接到输入接口,从传感器或FPGA提供初始数据进行处理。计划在数据可用时触发。适合数据流模型的应用程序通常包含大型且计算复杂的组件,这些组件相互依赖,并且可能不适合单个核心。运行在实时操作系统上,并且最小化延迟是关键。数据访问模式非常规则,因为数据数据的每个元素都是统一处理的。
下图是数据流处理模型:
数据流模型的一个应用程序是通信协议栈的物理层。它将来自数据链路层的通信请求转换为特定于硬件的操作,以影响电子信号的传输或接收。软件利用硬件中指令级的并行性,利用内部指令实现复杂的信号处理。处理链要求将一个或多个任务映射到每个核心。执行的同步是通过核心之间的消息传递来实现。数据通过共享内存或DMA传输在内核之间传递。
OpenMP Model
OpenMP是一种应用程序编程接口(API),用于在C/C++或Fortran中为共享内存并行(SMP)体系结构开发多线程应用程序。
OpenMP标准化了过去20年的SMP实践,是一种程序员友好的方法,具有许多优点。该API易于使用,实现速度快,一旦程序员确定了并行区域并并插入了相关的OpenMP结构,编译器和运行时系统就会计算出其余的细节。该API使跨核心的扩展变得容易,并允许在对源代码进行最小修改的情况下,从"m"核心实现转移到"n"核心实现。OpenMP是友好的顺序编码器友好的;也就是说,当一个程序员有一段连续的代码并希望将其并行化时,不需要创建一个完全独立的多核版本的程序。OpenMP鼓励采用增量并行化方法,程序员可以一次专注于小代码块的并行化,而不是这种全有或全无的方法。API还允许用户为顺序和并行版本的代码维护一个统一的代码库。
特征
OpenMP API主要由编译器指令、库例程和可用于并行化程序的环境变量组成
编译器指令允许程序员指定他们希望并行执行的指令,以及他们希望工作如何分布在内核中
OpenMP指令的语法通常为
#pragma omp construct[clause[clause]...]
例如:
#pragma omp section[nowait]
其中section是construct,nowait是clause
库例程或运行库调用允许程序员执行大量不同的函数。有一些执行环境例程可以配置和监视线程、处理器和并行环境的其他方面
有一些锁例程为同步提供函数调用。有一些定时程序提供了一个便携式挂钟计时器。
例如
“omp_set_num_threads(int numthreads)”告诉编译器需要为即将到来的并行区域创建多少线程
环境变量使程序员能够查询状态或更改应用程序的执行功能,如默认线程数、循环迭代计数等
例如:"OMP_NUM_threads"是保存OpenMP线程总数的环境变量
实现
本节包含四种典型的实现场景,并展示OpenMP如何允许程序员处理每种场景
创建线程组
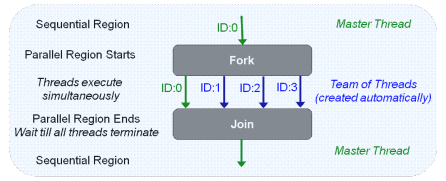
下图显示了OpenMP实现如何基于fork-join模型。OpenMP程序从顺序区域中的初始线程(称为主线程)开始。当遇到编译器指令"#pragma omp parallel"指示的并行区域时,调度程序会自动创建称为工作线程的额外线程。这组线程同时执行以处理并行代码块。当并行区域结束时,程序等待所有线程终止,然后为下一个连续区域恢复单线程执行
下面是一个OpenMP Hello World程序
#include<ti/omp/omp.h> //头文件
void main()
{
omp_set_num_threads(4); //库函数,设置线程数
#pragma omp parallel //编译器指令
{
int tid = omp_get_thread_num(); //库函数,获取线程id
printf("Hello World from thread = %d\n",tid);
}
}
在线程之间共享工作
在程序员确定了该区域中的哪些代码块将由多个线程运行之后,下一步是表示并行区域中的工作将如何在线程之间共享。
OpenMP工作共享结构正是为了实现这一点而设计的。有多种工作共享结构:
-
"pragma omp for"工作共享结构使程序员能够在多个线程之间分配for循环。此构造适用于后续迭代彼此独立的for循环;也就是说,更改迭代调用的顺序不会更改结果。
下面是三种工作共享结构:sequential、only with the parallel construct、both the parallel and work-sharing constructs
案例:假设一个具有N次迭代的for循环,执行基本的数组运算

-
“#pragma omp sections”,允许程序员跨核心分发多个任务,每个核心各自运行一段代码
案例:

参考文献:
- 《Multicore Programming Guide》