文章目录
一、数据类型
1.1 数据类型
C语言是一种有类型的语言。C语言中的变量在使用前必须被定义,并且需要确定类型。 如果我们不定义变量a就直接使用,看看会有什么后果。
#include <stdio.h>
int main()
{
a = 6;
return 0;
}
可以看出报错,提示我们使用了未定义的变量。

C以后的语言向两个方向发展:
• C++/Java更强调类型,对类型的检查更严格
• JavaScript、Python、PHP不看重类型,甚至不需要事先定义
因此,针对类型安全,有支持与反对的观点:
• 支持强类型的观点认为明确的类型有助于尽早发现程序中的简单错误
• 反对强类型的观点认为过于强调类型迫使程序员面对底层、实现而非事务逻辑
• 总的来说,早期语言强调类型,面向底层的语言强调类型
• C语言需要类型,但是对类型的安全检查并不足够
在C语言中有四大类类型:整数(包含逻辑)、浮点数、指针、自定义类型。
• 整数: char、short、int、long、long long
• 浮点数: float、double、long double
• 逻辑: bool
• 指针
• 自定义类型
这些类型都有什么不同呢?表现在以下几方面:
• 类型名称: int、long、double
• 输入输出时的格式化: %d、%ld、%lf
• 所表达的数的范围: char < short < int < float < double
• 内存中所占据的大小: 1个字节到16个字节
• 内存中的表达形式: 二进制数(补码)、编码
C语言有一个工具:sizeof。它是一个运算符,给出某个类型或变量在内存中所占据的字节数。使用示例如:sizeof(int)、sizeof(i)。我们写代码来试一试,进行测试,可以看出int类型和变量a在内存中都占了4个字节,也就是32个bit。

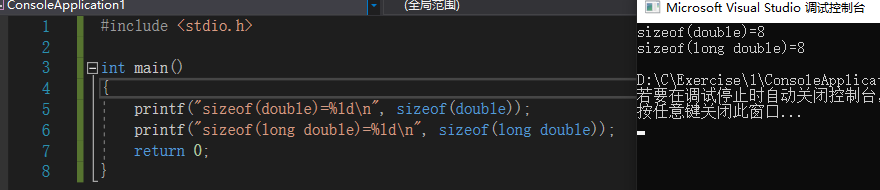
我们再测试double和long double的大小,可以看出都是8个字节,也就是64个bit。
关于sizeof,有需要注意的地方。sizeof是静态运算符,它的结果在编译时刻就决定了。因此,不要在sizeof的括号里做运算,这些运算不会做的。
#include <stdio.h>
int main()
{
int a;
a = 6;
printf("sizeof(a)=%ld\n", sizeof(a++));
printf("a=%d\n", a);
return 0;
}
我们运行一下,发现a的结果没变化。这是因为这个sizeof是静态的,括号里面的操作根本就没有做。它只会去看a++的结果是个什么类型的值,然后输出结果的类型大小。

我们再来测试a+1.0的大小。对于a+1.0这样一个int一个double相加,编译器会将int转换成double,最后的结果是个double类型的值。可以看出a+1.0的类型大小为8,且a的值没有改变。

1.2 整数类型
我们来看下整数各类型的大小。
#include <stdio.h>
int main()
{
printf("sizeof(char)=%ld\n", sizeof(char));
printf("sizeof(short)=%ld\n", sizeof(short));
printf("sizeof(int)=%ld\n", sizeof(int));
printf("sizeof(long)=%ld\n", sizeof(long));
printf("sizeof(long long)=%ld\n", sizeof(long long));
return 0;
}
结果如下:

总的来说,C语言各类型的大小如下所示:
char: 1字节(8比特)
short: 2字节
int: 取决于编译器(CPU),通常的意义是“1个字”
long: 取决于编译器(CPU),通常的意义是“1个字”
long long: 8字节
关于上面提到的“1个字”,详细的说明如下:
在计算机里面我们有CPU,在CPU外面有内存(RAM),在CPU和内存之间有一种东西叫做总线,在CPU里面还有一种东西叫做寄存器(Reg)。当我们在说一台计算机的字长时,我们一般说的是这个寄存器是多少bit的。比如当我们说字长是32位时,我们是在说这个寄存器能够表达32bit的数据。我们也是在说CPU和内存间传递数据时,每一次传递32个bit。这个字长在C语言中就会反映成int,即int表达的就是一个寄存器的大小。这也就为什么在不同平台上int不一样大的原因。

1.3 整数的内部表达
整数在计算机内部是怎样表达的呢?计算机内部一切都是二进制,不管你是整数还是浮点数,只是我们以什么方式去看待它。所有的类型最终的意义是说我们以什么方式去看待它,而不是表明它在内部是怎么表达的 。
对于负数,我们是如何表达的呢?
18 —> 00010010
0 —> 00000000
-18 —> ?
十进制负数:
十进制用负号“-”来表示负数,在做计算的时候
• 加减是做相反的运算
• 乘除时当作正数,计算完毕后对结果的符号取反
二进制负数:
1个字节可以表达的数:00000000 — 11111111 (0-255),要表达出负数有三种方案:
1 仿照十进制,有一个特殊的标志表示负数
2. 取中间的数为0,如1000000表示0,比它小的是负数,比它大的是正数
3. 补码
我们来分析前两种方案:
①使用一个特殊标志来表达负数,这个标志是在这个数以外的。即在这8个bit以外,使用另外一个bit来表达是正数还是负数。 这样会使得计算机设计会非常复杂,每次做运算都需要根据数据外的一个bit来表示正负,然后进行相应的操作。
②如果去中间数为0,每次运算时都需要减去128将其转换为正常的十进制数,也会使得程序在输入输出过程中做得比较复杂。
补码:
考虑-1,我们希望-1 + 1 —> 0。如何能做到?
0 —> 00000000
1 —> 00000001
全1加上1就为100000000,由于是8bit,所以多出的那一位会丢掉,剩下的结果正是0。
11111111 + 00000001 —> 100000000
也可以换一种思路:
因为0 - 1 —> -1,所以,-1 =
(1)00000000 - 00000001 —> 11111111
11111111被当作纯二进制看待时,是255,被当作补码看待时是-1
总结:对于 − a -a −a,其补码就是 0 − a 0-a 0−a,实际是 2 n − a {2^n} - a 2n−a, n n n是这种类型的位数。补码的意义就是拿补码和原码可以加出一个溢出的“零”。
1.4 整数的范围
对于一个字节(8位),可以表达的是:00000000 - 11111111。其中
00000000 —> 0
11111111 ~ 10000000(开头为1且递减) —> -1 ~ -128
00000001 ~ 01111111(开头为0且递增) —> 1 ~ 127
因此,对于其它类型的变量,能够表示的范围是: − 2 32 − 1 ∼ 2 32 − 1 − 1 - {2^{32 - 1}} \sim {2^{32 - 1}} - 1 −232−1∼232−1−1
char: -128 ~ 127
short: -32768 ~ 32767
int: 取决于编译器(CPU),通常的意义是“1个字”
long: 4字节
long long: 8字节
我们来举个例子,看一下将一个值分别赋值给两个不同类型的变量,结果是怎么样的。
#include <stdio.h>
int main()
{
char c = 255;
int i =255;
printf("c=%d,i=%d\n", c, i);
return 0;
}
运行,可以发现在char类型的变量中,255=11111111,最高位为1,所以为负数,根据补码原理可以知道为-1。对于int,255=00000000 00000000 00000000 11111111,最高位仍为0,所以为正数。

如果我们将这些类型的变量拿出来时也当作正常的二进制数对待,我们需要在那些变量的类型的前面再加个关键字:unsigned。如果一个字面量常数想表达自己是unsigned,可以在后面加上u或U,如255U。
char: 00000000~11111111 -> -128~127
unsigned char: 00000000~11111111 -> 0~255
整数越界问题:
整数是以纯二进制方式进行计算的,尽管整数的负数部分是以补码来表达的。所以:
11111111 + 1 —> 100000000 —> 0
01111111 + 1 —> 10000000 —> -128
10000000 - 1 —> 01111111 —> 127
我们画一个图来直观地理解整数越界。char可以看作一个圆圈,有正数和复数两部分。如果在边界处加减1,则会越界。

我们试着在127那个地方加1看看会不会得到-128。我们写出代码如下:
#include <stdio.h>
int main()
{
char c = 127;
int i = 255;
c = c + 1;
printf("c=%d,i=%d\n", c, i);
return 0;
}
运行,进行测试可以看出的确出现了越界。

如果对unsigned char类型的127加1,则会得到128。

如果将unsigned char类型的255加1,则会得到0,因为256在8个bit里面是全0,第9位是1会被丢掉。

如果将unsigned char类型的0减1,则会得到255。

因此,unsigned char的范围如下图所示:

1.5 整数的格式化
虽然整数有很多种类型,但是在使用printf和scanf做输入输出时,只有两种:int和long long。所有小于int的都采用int来输入输出,就是%d。所有比int大的用%ld来输入输出,这个l表示long。如果是unsigned的,就用%u和%lu。
• %d: int
• %u: unsigned
• %ld:long long
• %lu:unsigned long long
我们现在输入两个负数,分别为char和int类型。然后让他们使用%u,当作unsigned被输出。
#include <stdio.h>
int main()
{
char c = -1;
int i = -1;
printf("c=%u,i=%u\n", c,i);
return 0;
}
运行一下,可以看出输出结果是两个非常大的值且相等。这两个数是unsigned int所能表达的最大的数,因为-1就表示全1。对于char c = -1,当我们把小于int的类型传递给printf时,编译器会把这些类型转换为int。

8进制和16进制:
一个以0开始的数字面量是8进制
一个以0x开始的数字面量是16进制
#include <stdio.h>
int main()
{
char c = 012;
int i = 0x12;
printf("c=%d,i=%d\n", c,i);
return 0;
}
我们运行一下,可以看出用%d十进制的方式打印这两个数结果正确。值得注意的是:我们用8进制或者16进制只是用一种方式去看这个值,它在计算机内部是二进制。

如果我们想用8进制和16进制输出,我们需要用%o和%x。

在16进制中,如果带有大写字母,可以用%X。

总结:8进制和16进制只是如何把数字表达为字符串,与内部如何表达数字无关
1.6 选择整数类型
C语言有太多的整数类型了,这也是为什么我们一开始不直接学习那么多的类型。C语言有那么多整数类型的原因是:
早期的计算机语言需要准确地去表达计算机里面的东西。比如我有一个输入输出的端口,那个端口就是16bit,每一个bit对应一个芯片上的引脚,于是我就必须要用short去控制它,用别的去控制它就不对了。
现在我们如何去选择整数类型:没有特殊需要,就选择int。原因如下:
• 现在的CPU的字长普遍是32位或64位,一次内存读写就是一个int,一次计算也是一个int,选择更短的类型不会更快,甚至可能更慢。
• 现代的编译器一般会设计内存对齐,所以更短的类型实际在内存中有可能也占据一个int的大小(虽然sizeof告诉你更小)
对于unsigned,它只是输出的方式不同,内部计算是一样的。如果不是迫不得已,没必要用unsigned。
1.7 浮点类型
浮点类型有float和double,他们的基本信息如下。
| 类型 | 字长 | 范围 | 有效数字 |
|---|---|---|---|
| float | 32 | ± ( 1.20 × 1 0 − 38 ∼ 3.40 × 1 0 38 ) , 0 , ± inf , n a n \pm (1.20 \times {10^{ - 38}} \sim 3.40 \times {10^{38}}),0, \pm \inf ,{\rm{nan}} ±(1.20×10−38∼3.40×1038),0,±inf,nan | 7 |
| double | 64 | ± ( 2.20 × 1 0 − 308 ∼ 1.79 × 1 0 308 ) , 0 , ± inf , n a n \pm (2.20 \times {10^{ - 308}} \sim 1.79 \times {10^{308}}),0, \pm \inf ,{\rm{nan}} ±(2.20×10−308∼1.79×10308),0,±inf,nan | 15 |
在可以表达的数字范围中,特别地,0是特地拿出来可以表达的数。 ± inf \pm \inf ±inf(±无穷大)是可以表达的, n a n {\rm{nan}} nan(无效数字)也是可以表达的。float和double都存在0周围一小段范围无法表达,如下图所示:

对于有效数字,比如float的有效数字是7,代表只有前面7个数字是准确的,后面的数字都是不准确的。
浮点类型的输入输出用法如下:
| 类型 | scanf | printf |
|---|---|---|
| float | %f | %f,%e |
| double | %lf | %f,%e |
对于printf,可以使用%e,这代表以科学计数法的方式进行输出。我们写出代码来看下效果。
#include <stdio.h>
int main()
{
double ff = 1234.56789;
printf("ff=%e %E %f\n", ff,ff,ff);
return 0;
}
我们运行,可以看出使用科学计数法的输出后面有个e+03,代表 1 0 3 {\rm{1}}{
{\rm{0}}^3} 103。

科学计数法的使用注意规范如下:

现在我有一个很小的数0.0000000001,使用科学计数法可以表示为1E-10。我们在程序中用%f的方式将其打印出来看看。可以看出后面的1没有显示。

如何将那个1显示出来呢?我们只需在%和f之间加上一个点 . 和需要显示的位数。

在%和f之间加上.n可以指定输出小数点后几位,这样的输出是做4舍5入的。我们写出代码来测试一下:
#include <stdio.h>
int main()
{
printf("ff=%.3f\n", -0.0049);
printf("ff=%.30f\n", -0.0049);
printf("ff=%.3f\n", -0.00049);
return 0;
}
结果如下,可以看出,当我们输出30位小数时,打印的不是-0.0049000000…。这是因为计算机内部所有的数实际上是离散的,不是数学意义上连续的,无法准确地去表达一个数。如果找不到-0.0049这个数,就要去找一个离它最近的数,两个数的差值就是浮点数的误差。

1.8 浮点数的范围和精度
在前面我们说过浮点数的范围也包括inf和nan。
• printf输出inf表示超过范围的浮点数:±∞
• printf输出nan表示不存在的浮点数
我们写出代码测试一下
#include <stdio.h>
int main()
{
printf("%f\n", 12.0/0.0);
printf("%f\n", -12.0 / 0.0);
printf("%f\n", 0.0 / 0.0);
return 0;
}
Dev C++输出结果为:
inf
-inf
nan
我使用的Visual Studio,编译直接会通不过。

对于浮点数,在计算机内部它们是不连续的,因此在浮点数运算中慎用==号,我们先举个例子如下:
#include <stdio.h>
int main()
{
float a, b, c;
//注意后面需要带f表示为float变量
//带小数点的字面量为double而非float
a = 1.345f;
b = 1.123f;
c = a + b;
if (c == 2.468)
printf("相等\n");
else
printf("不相等!c=%.10f,或%f\n",c,c);
return 0;
}
运行,发现结果并不相等。

因此 ,在浮点运算中:
f1 == f2可能失败,可以使用如下方法:
fabs(f1-f2) < 1e-12
只要它们的差值的绝对值小于能够表达的精度就行,比如对于float能够表达7位有效数字,那么<1e-8就行。
浮点数的内部表示不是真正的二进制,而是编码的形式。前面11个bit表示整数部分,后面52bit表示指数部分。浮点数在计算时是由专用的硬件部件实现的。在做计算时,这个硬件将其解码出来,然后去做运算,最后得到的结果又进行编码。计算double和float所用的部件是一样的。

在使用浮点数做计算时,需要注意以下两点:
• 如果没有特殊需要,只使用double
• 现代CPU能直接对double做硬件运算,性能不会比float差,在64位的机器上,数据存储的速度也不比float慢
1.9 字符类型
char(Character)是一种整数,也是一种特殊的类型:字符。
• 我们可以用单引号表示字符字面量:'a', '1'
• ''也是一个字符
• printf和scanf里用%c来输入输出字符
针对char也可以是个字符,我们分别赋予两个char类型的变量1和’1’,看其是否相等。
#include <stdio.h>
int main()
{
char c = 1;
char d = '1';
if (c == d)
printf("相等\n");
else
printf("不相等\n");
printf("c=%d\n",c);
printf("d=%d\n",d);
return 0;
}
可以看出,'1’这个字符在计算机内部使用49来表达。

我们再来测试一下,以%c的方法去读入字符,然后以整数和字符的方法打印结果。
#include <stdio.h>
int main()
{
char c;
scanf_s("%c", &c);
printf("c=%d\n",c);
printf("c='%c'\n", c);
return 0;
}
结果如下:

我们以%d的方法去读入
#include <stdio.h>
int main()
{
int i;
char c;
//scanf不能读入char,因此使用int读取,并把值给c
scanf_s("%d", &i);
c = i;
printf("c=%d\n",c);
printf("c='%c'\n", c);
return 0;
}
结果如下:

因此,我们如何输入’1’这个字符给char c?有两种方法
• scanf("%c", &c); —>输入的c为1
• scanf("%d", &i); c=i; —>输入的i为49
‘1’的ASCII编码是49,所以当c==49时,它代表’1’

现在我有两个输入,看看有什么不同。
scanf("%d %c", &i, &c);
scanf("%d%c", &i, &c);
我们首先来看第一种:
#include <stdio.h>
int main()
{
int i;
char c;
scanf_s("%d %c", &i, &c);
printf("i=%d, c=%d, d='%c'\n", i,c,c);
return 0;
}

我们来看看第二种不带空格的。

总结:
①不带空格:整数只读到整数结束为止,后面那个给别人。
②带空格:整数要把空格也读入
字符运算:
字符也是可以做运算的,我们这里让字符’A’++,看看结果如何。
#include <stdio.h>
int main()
{
char c = 'A';
c++;
printf("%c\n",c);
return 0;
}
可以看出’A’++过后变成了’B’。

我们再来看看两个字符的差。
#include <stdio.h>
int main()
{
int i = 'Z' - 'A';
printf("%d\n",i);
return 0;
}
可以看出’A’和’Z’刚好差了25

因此我们可以总结如下:
• 一个字符加一个数字得到ASCII码表中那个数之后的字符
• 两个字符的减,得到它们在表中的距离
根据字符可以加减的原理,我们可以处理大小写转换。
• 字母在ASCII表中是顺序排列的
• 大写字母和小写字母是分开排列的,并不在一起
• ‘a’-‘A’可以得到两段之间的距离,于是
• a+’a’-‘A”可以把一个大写字母变成小写字母,而
• a+’A’-‘a’可以把一个小写字母变成大写字母
1.10 逃逸字符
之前在求身高的题目中看到过这个。

由于无法在打印引号内直接添加引号,因此我们用来"。因此,用来表达无法印出来的控制字符或特殊字符,它由一个反斜杠“\”开头,后面跟上另一个字符,这两个字符合起来,组成了一个字符,我们叫做逃逸字符。
C语言中有以下逃逸字符:
| 字符 | 意义 | 字符 | 意义 |
|---|---|---|---|
| \b | 回退一格 | " | 双引号 |
| \t | 到下一个表格位 | ’ | 单引号 |
| \n | 换行 | \ | 反斜杠本身 |
| \r | 回车 |
我们来测试下回退一格的功能:
#include <stdio.h>
int main()
{
printf("123\b\n456\n");
return 0;
}
在Dev C++中运行发现出现这个
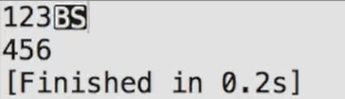
而在终端里面出现这个

为甚什么在不同的地方会出现不同的结果呢,我们来详细分析:

我们把带代码稍微修改一下,在\b后面加个字母A,此时回退符成功将前面的3替换成A。回退辅就是回去一格,让下一个输出从那里开始。如果你不输出东西,那就什么都没有。如果你输出东西,就把刚才的东西覆盖掉。

我们来看看制表符的使用:
• 制表位不是一段距离,而是代表每行的固定位置
• 一个\t使得输出从下一个制表位开始
• 用\t才能使得上下两行对齐
我们写出带代码进行测试:
#include <stdio.h>
int main()
{
printf("123\t456\n");
printf("12\t456\n");
return 0;
}
可以看出是对齐了的。

1.11 类型转换
当运算符的两边出现不一致的类型时,会自动转换成较大的类型
• ⼤大的意思是能表达的数的范围更⼤大
• char —> short —> int —> long —> long long
• int —> float —> double
• 对于printf,任何小于int的类型会被转换成int;float会被转换成double
• 但是scanf不会,它需要明确知道后面变量的大小。比如要输⼊入short,需要%hd
当我们要把一个变量强制转换成另一个类型(通常是较小的类型),用法如下:
• (类型)值 比如:
• (int)10.2
• (short)32
• 注意这时候的安全性,小的变量不总能表达大的量
• (short)32768
我们来测试一下小的变量表示大的变量
#include <stdio.h>
int main()
{
printf("%d", (short)32768);
return 0;
}
运行,可以发现越界。

强制类型转变只是从那个变量计算出了一个新的类型的值,它并不改变那个变量,无论是值还是类型都不改变。比如这里我把int类型的i转换类型赋值给short类型的s。
#include <stdio.h>
int main()
{
int i = 32768;
short s = (short)i;
printf("%d\n",i);
return 0;
}
可以看出i的类型并没有发生变化。

我们再看个例子
double a = 1.0;
double b = 2.0;
int i = (int)a / b;
强制类型转换的优先级⾼高于四则运算
因此会先将a转换成int,然后i除以double,最终结果i变成double
如果需要让结果为int,需要int i = (int)(a / b);
小测验
1、以下哪个字母不能在数字后面表示类型?
A.F
B.U
C.L
D.X
答案:D
2、以下哪个数字的值最大?
A.10
B.010
C.0x10
D.10.0
答案:C
3、以下哪个数字占据的空间最大?
A.32768
B.‘3’
C.32768.0
D.32768.0F
答案:C
4、以下哪种类型不能用在switch-case的判断变量中:
A.char
B.short
C.int
D.double
答案:D
5、下列哪些是有效的字符?
A.‘ ’
B.‘\’‘
C.''
D.'\'
答案:ABC
6、以下表达式的结果是:
'1'+3
答案:52
二、其他运算:逻辑、条件、逗号
2.1 逻辑类型
还有一种类型叫做逻辑类型(bool)
使用时需要#include <stdbooh.h>
之后就可以使用bool和true、false
我们来使用一下看看:
#include <stdio.h>
#include <stdbool.h>
int main()
{
bool b = 6 > 5;
bool t = true;
t=2;
printf("%d", b);
return 0;
}
我们可以看出,bool变量实际上是个整数,可以将整数赋值给它。如果要输出这个bool变量,没有特别的的方式使用,还是得用%d。

2.2 逻辑运算
逻辑运算是对逻辑量进行的运算,结果只有0或1。逻辑量是关系运算或逻辑运算的结果。
| 运算符 | 描述 | 示例 | 结果 |
|---|---|---|---|
| ! | 逻辑非 | !a | 如果a是true结果就是false,如果a是false结果就是true |
| && | 逻辑与 | a && b | 如果a和b都是true,结果就是true;否则就是false |
| | | | 逻辑或 | a || b | 如果a和b有一个是true,结果为true;两个都是false,结果为false |
如果要表达数学中的区间,如:x ∈(4,6)或x ∈[4,6],应该如何写C的表达式?
像 4 < x < 6这样的式子,不是C能正确计算的式子,因为4 < x的结果是一个逻辑值(0或1)。
正确写法应该是x>4 && x<6
如何判断一个字符c是否是大写字母?
c >= ‘A’ && c<= ‘Z’
!age>20是如何运算的呢?
虽然逻辑运算符的优先级普遍低于比较运算符,但是这个!是个单目运算符,而单目运算符优先级一般高于双目运算符。因此结果是判断!age的值是否大于20,结果肯定为false,因为!age的值为0或者1。
这三个运算符优先级如下:
! > && > ||
我们总结出所有的运算符优先级如下:

逻辑运算是自左向右进行的,如果左边的结果已经能够决定结果了,就不会做右边的计算。
• 对于&&,左边是false时就不做右边了
• 对于||,左边是true时就不做右边了
• 不要把赋值,包括复合赋值组合进表达式!
我们举个例子,将赋值运算也加进逻辑运算表达式。
#include <stdio.h>
int main()
{
int a = -1;
if (a>0 && a++>1)
{
printf("OK\n");
}
printf("%d\n", a);
return 0;
}
可以看出,由于a<0,所以逻辑运算符左边判断为假后不会进行右边的运算。如果改为左边a<0,那么右边a++会执行,a最后值为0。

2.3 条件运算与逗号运算
条件运算符长得像这样:
count = (count > 20) ? count -10 : count+10;
其中,问号前面是条件。问号后面是条件满足时的值和条件不满足时的值。
它就相当于:
if ( count >20 )
count = count-10;
else
count = count+10;
条件运算符的优先级高于赋值运算符,但是低于其他运算符。条件运算符是自右向左结合的,我们不希望你使用嵌套的条件表达式,会使得别人难以理解你的程序。
逗号运算符:
逗号用来连接两个表达式,并以其右边的表达式的值作为它的结果。逗号的优先级是所有的运算符中最低的,所以它两边的表达式会先计算;逗号的组合关系是自左向右,所以左边的表达式会先计算,而右边的表达式的值就留下来作为逗号运算的结果。
我们写出代码来测试一下。
#include <stdio.h>
int main()
{
int i;
i = 3+4,5+6;
printf("%d\n", i);
return 0;
}
运行,由于逗号运算符优先级最低,因此先算i=3+4,最后去算5+6,5+6这个表达式没有用到,它的结果没有给任何人。

如果我给表达式加上括号,此时结果就发生变化,i=11。

目前逗号运算符一般用在for循环中,用于当我们想在for里面放多个计算时。
for ( i=0, j=10; i<j; i++, j- - ) ……
小测验
1、以下哪个表达式,当a和b都是true或者都是false的时候,表达式的结果为true。
A. a && b
B. a || b
C. a == b
D. a ^ b
答案:C
2、以下哪个表达式与!(a&&b)是等价的
A. !a && !b
B. !a || !b
C. a && b
D. a || b
答案:B
3、以下哪个表达式的结果是true?
A. !(4<5)
B. 2>2||4==4&&1<0
C. 34==33&&!false
D. !false
答案:D
4、以下哪个表达式,当a和b中只有一个是true的时候结果为true,而如果两个都是false或都是true的时候,结果为false
A. a && b
B. a || b
C. a != b
D. !a && !b
答案:C
5、以下代码执行后,i的值是:
i = 3/2,3*2;
答案:1