一、决策树
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
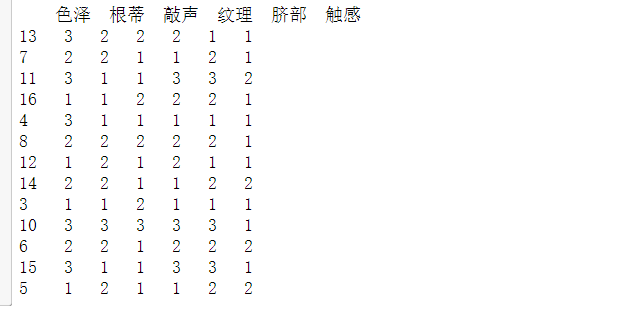
样本数据如下:

二、将txt导入excel
创建一个空的xsl文件,以EXCEL打开:
点击数据中的自文本:
选择要导入的txt文件:
选择分隔符号和字符集:
选择空格:
完成:
确定:
成功导入:
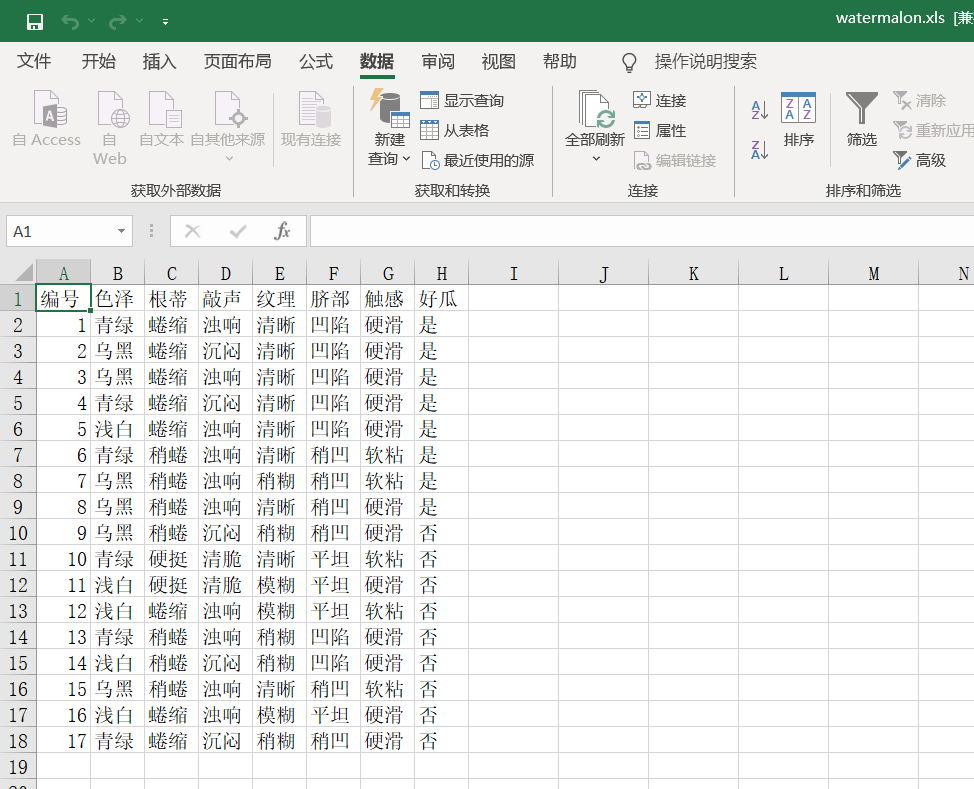
三、用python求解
导入python模块:
import pandas as pd
import numpy as np
from collections import Counter
from math import log2
数据获取和处理函数:
#数据获取与处理
def getData(filePath):
data = pd.read_excel(filePath)
return data
def dataDeal(data):
dataList = np.array(data).tolist()
dataSet = [element[1:] for element in dataList]
return dataSet
- 获取属性名称和类别标记
#获取属性名称
def getLabels(data):
labels = list(data.columns)[1:-1]
return labels
#获取类别标记
def targetClass(dataSet):
classification = set([element[-1] for element in dataSet])
return classification
- 叶节点标记
#将分支结点标记为叶结点,选择样本数最多的类作为类标记
def majorityRule(dataSet):
mostKind = Counter([element[-1] for element in dataSet]).most_common(1)
majorityKind = mostKind[0][0]
return majorityKind
- 计算信息熵
#计算信息熵
def infoEntropy(dataSet):
classColumnCnt = Counter([element[-1] for element in dataSet])
Ent = 0
for symbol in classColumnCnt:
p_k = classColumnCnt[symbol]/len(dataSet)
Ent = Ent-p_k*log2(p_k)
return Ent
- 构建子数据集
#子数据集构建
def makeAttributeData(dataSet,value,iColumn):
attributeData = []
for element in dataSet:
if element[iColumn]==value:
row = element[:iColumn]
row.extend(element[iColumn+1:])
attributeData.append(row)
return attributeData
- 计算信息增益
#计算信息增益
def infoGain(dataSet,iColumn):
Ent = infoEntropy(dataSet)
tempGain = 0.0
attribute = set([element[iColumn] for element in dataSet])
for value in attribute:
attributeData = makeAttributeData(dataSet,value,iColumn)
tempGain = tempGain+len(attributeData)/len(dataSet)*infoEntropy(attributeData)
Gain = Ent-tempGain
return Gain
- 选择最优属性
#选择最优属性
def selectOptimalAttribute(dataSet,labels):
bestGain = 0
sequence = 0
for iColumn in range(0,len(labels)):#不计最后的类别列
Gain = infoGain(dataSet,iColumn)
if Gain>bestGain:
bestGain = Gain
sequence = iColumn
print(labels[iColumn],Gain)
return sequence
- 建立决策树
#建立决策树
def createTree(dataSet,labels):
classification = targetClass(dataSet) #获取类别种类(集合去重)
if len(classification) == 1:
return list(classification)[0]
if len(labels) == 1:
return majorityRule(dataSet)#返回样本种类较多的类别
sequence = selectOptimalAttribute(dataSet,labels)
print(labels)
optimalAttribute = labels[sequence]
del(labels[sequence])
myTree = {
optimalAttribute:{
}}
attribute = set([element[sequence] for element in dataSet])
for value in attribute:
print(myTree)
print(value)
subLabels = labels[:]
myTree[optimalAttribute][value] = \
createTree(makeAttributeData(dataSet,value,sequence),subLabels)
return myTree
def main():
filePath = 'watermalon.xls'
data = getData(filePath)
dataSet = dataDeal(data)
labels = getLabels(data)
myTree = createTree(dataSet,labels)
return myTree
mytree = main()
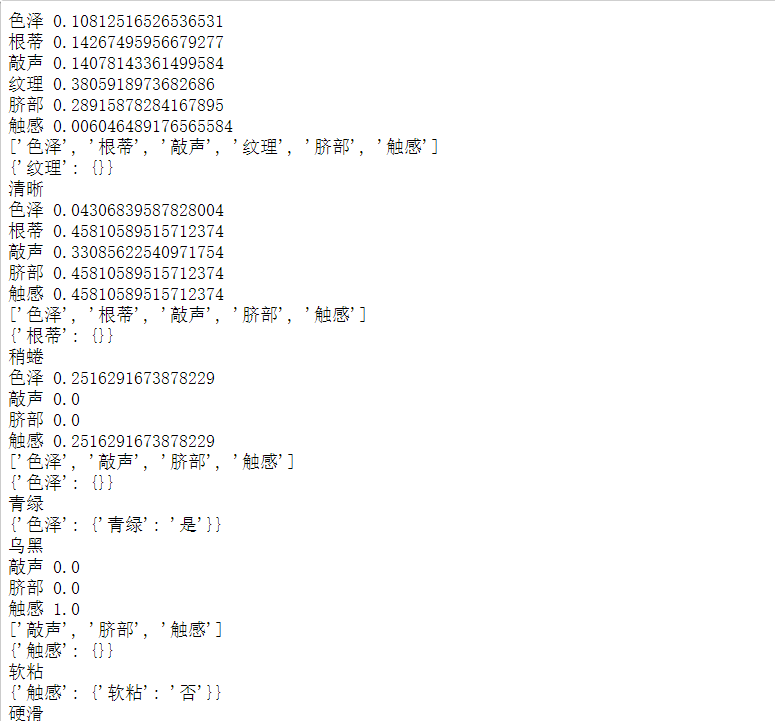

print(mytree)

最终结果:
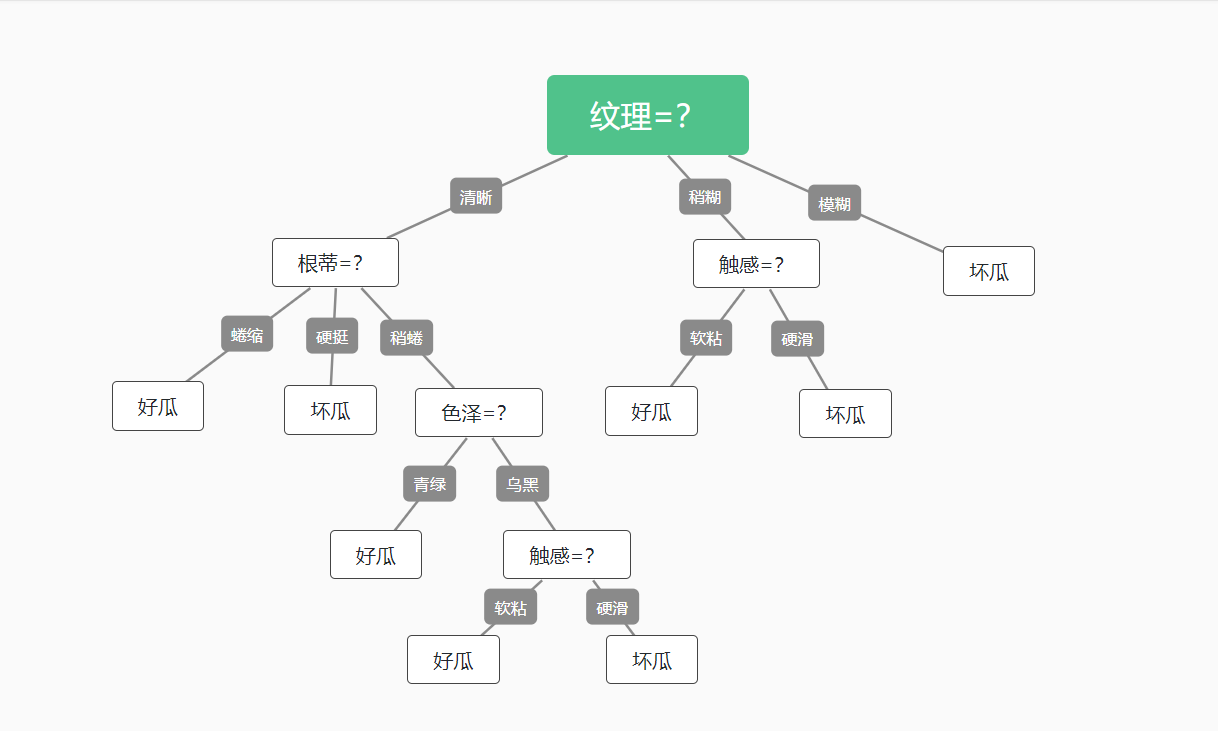
四、使用ID3算法
1. ID3算法
ID3算法是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
2. 代码实现
数据集如下:
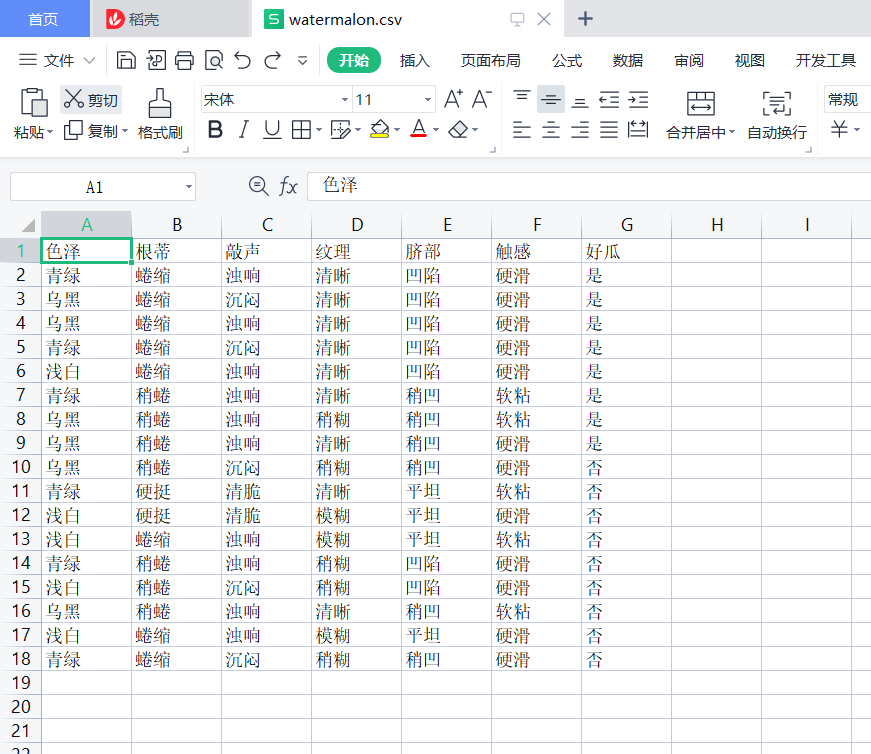
导入包和数据:
#导入相关库
import pandas as pd
import graphviz
from sklearn.model_selection import train_test_split
from sklearn import tree
f = open('watermalon.csv','r')
data = pd.read_csv(f)
x = data[["色泽","根蒂","敲声","纹理","脐部","触感"]].copy()
y = data['好瓜'].copy()
print(data)

数据转换:
#将特征值数值化
x = x.copy()
for i in ["色泽","根蒂","敲声","纹理","脐部","触感"]:
for j in range(len(x)):
if(x[i][j] == "青绿" or x[i][j] == "蜷缩" or data[i][j] == "浊响" \
or x[i][j] == "清晰" or x[i][j] == "凹陷" or x[i][j] == "硬滑"):
x[i][j] = 1
elif(x[i][j] == "乌黑" or x[i][j] == "稍蜷" or data[i][j] == "沉闷" \
or x[i][j] == "稍糊" or x[i][j] == "稍凹" or x[i][j] == "软粘"):
x[i][j] = 2
else:
x[i][j] = 3
y = y.copy()
for i in range(len(y)):
if(y[i] == "是"):
y[i] = int(1)
else:
y[i] = int(-1)
#需要将数据x,y转化好格式,数据框dataframe,否则格式报错
x = pd.DataFrame(x).astype(int)
y = pd.DataFrame(y).astype(int)
print(x)
print(y)

建立模型并训练:
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2)
print(x_train)
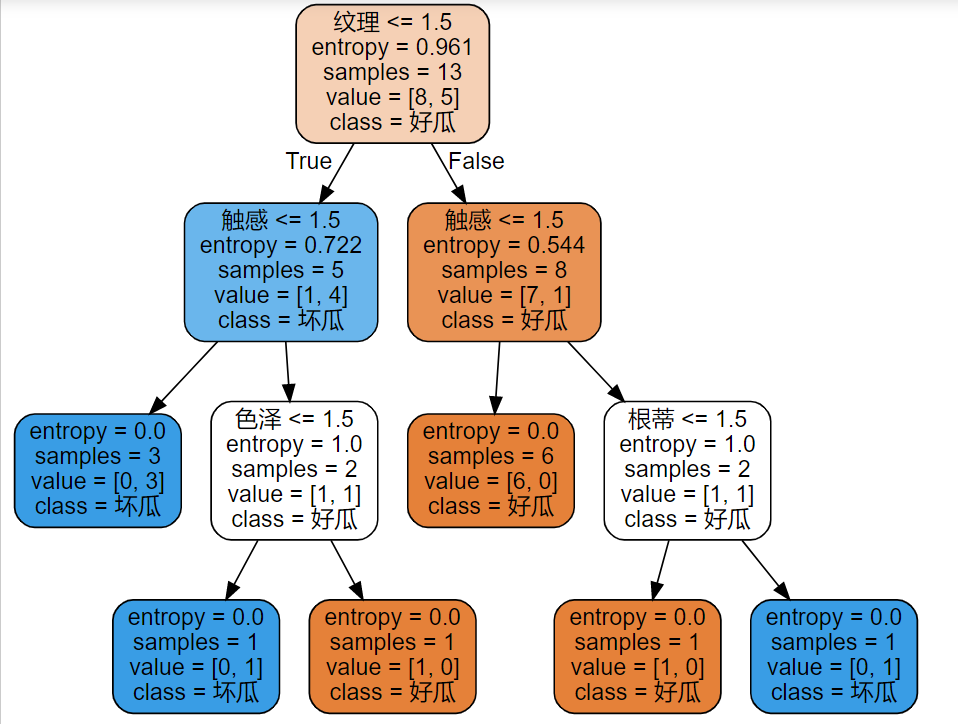
#决策树学习
clf = tree.DecisionTreeClassifier(criterion="entropy") #实例化
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test)
print(score)

画决策树:
# 加上Graphviz2.38绝对路径
import os
os.environ["PATH"] += os.pathsep + 'D:/Some_App_Use/Anaconda/Anaconda3/Library/bin/graphviz'
feature_name = ["色泽","根蒂","敲声","纹理","脐部","触感"]
dot_data = tree.export_graphviz(clf ,feature_names= feature_name,class_names=["好瓜","坏瓜"],filled=True,rounded=True,out_file =None)
graph = graphviz.Source(dot_data)
graph
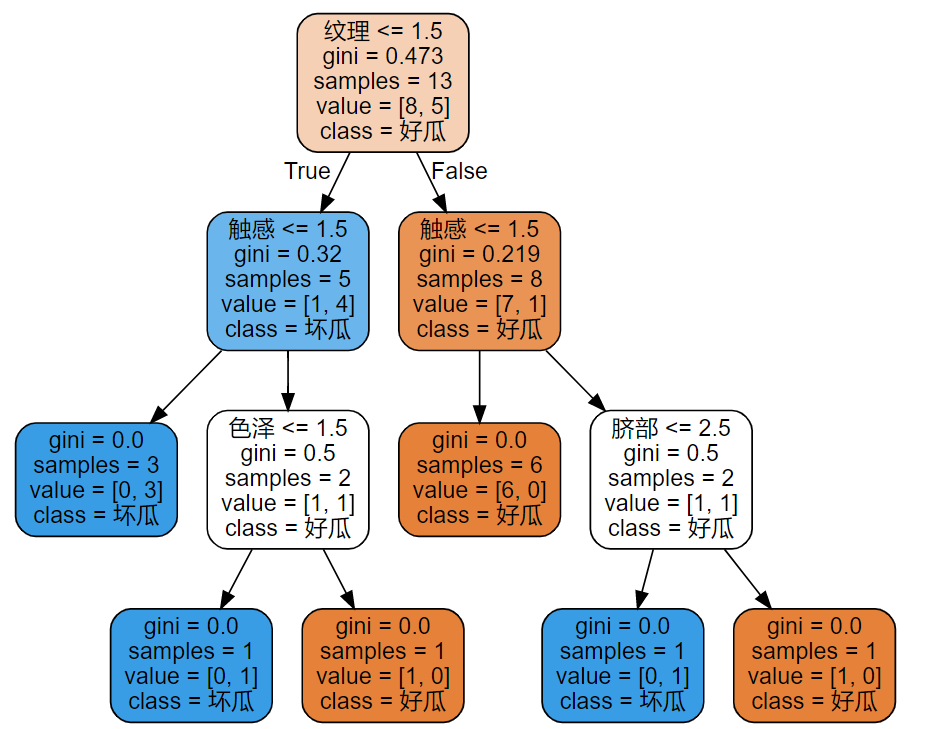
五、使用CART算法
只需要将DecisionTreeClassifier函数的参数criterion的值改为gini:
clf = tree.DecisionTreeClassifier(criterion="gini") #实例化
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test)
print(score)

画决策树:
# 加上Graphviz2.38绝对路径
import os
os.environ["PATH"] += os.pathsep + 'D:/Some_App_Use/Anaconda/Anaconda3/Library/bin/graphviz'
feature_name = ["色泽","根蒂","敲声","纹理","脐部","触感"]
dot_data = tree.export_graphviz(clf ,feature_names= feature_name,class_names=["好瓜","坏瓜"],filled=True,rounded=True,out_file =None)
graph = graphviz.Source(dot_data)
graph
六、总结
决策树易于理解和实现,人们在在学习过程中不需要使用者了解很多的背景知识,这同时是它的能够直接体现数据的特点,只要通过解释后都有能力去理解决策树所表达的意义。
参考
(一)《机器学习》(周志华)第4章 决策树 笔记 理论及实现——“西瓜树”