堆排序
虽然树还没弄懂,但是这个算法中用到的完全二叉树还是很容易懂的。
我们将堆排序的算法分为两部分,一部分是排序算法,另一部分是构造堆的算法。
void HeapAdjust(SqList* L, int s, int m)
{
// 调整堆内元素排序位置,将双亲结点和孩子结点中元素值最大的赋值给根结点
int temp, j;
temp = L->Array[s];
for (j = 2 * s; j <= m; j *= 2)
{
// 沿较大孩子结点向下筛选
if (j < m && L->Array[j] < L->Array[j + 1])
++j; // j为关键字,记录孩子结点值较大的下标
if (temp >= L->Array[j])
break; // 双亲结点大于等于孩子结点,不进行交换
L->Array[s] = L->Array[j];
s = j;
}
L->Array[s] = temp;
}
void Heap_Sort(SqList* L)
{
int i;
for (i = L->length / 2; i > 0; i--) {
//把顺序表构建为一个大根堆
HeapAdjust(L, i, L->length);
}
for (i = L->length; i > 1; i--)
{
swap(L, 1, i); // 将堆顶记录和当前未经排序子序列的最后一个记录交换
HeapAdjust(L, 1, i - 1); // 重新将数组构建为大根堆,但不囊括树的i-1个元素
}
}
构造堆有两种方式,一种大根堆,一种小根堆。我们以大根堆进行分析(小根堆不过是换几个符号):
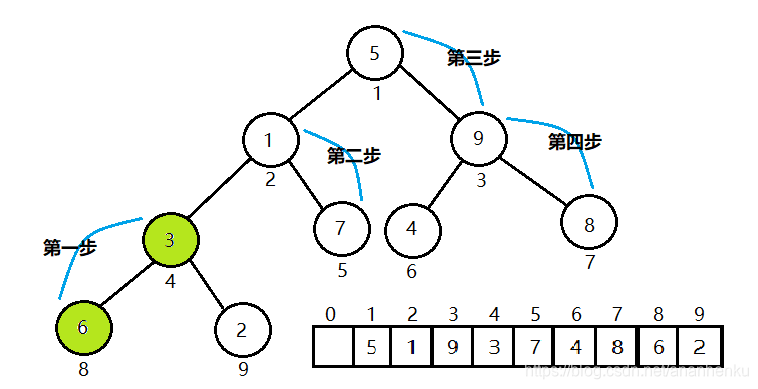
每一步都是从双亲结点出发,找到它对应的左右孩子结点中最大值,如果比双亲结点的值大,进行交换,…,随后我们便得到一个大根堆。
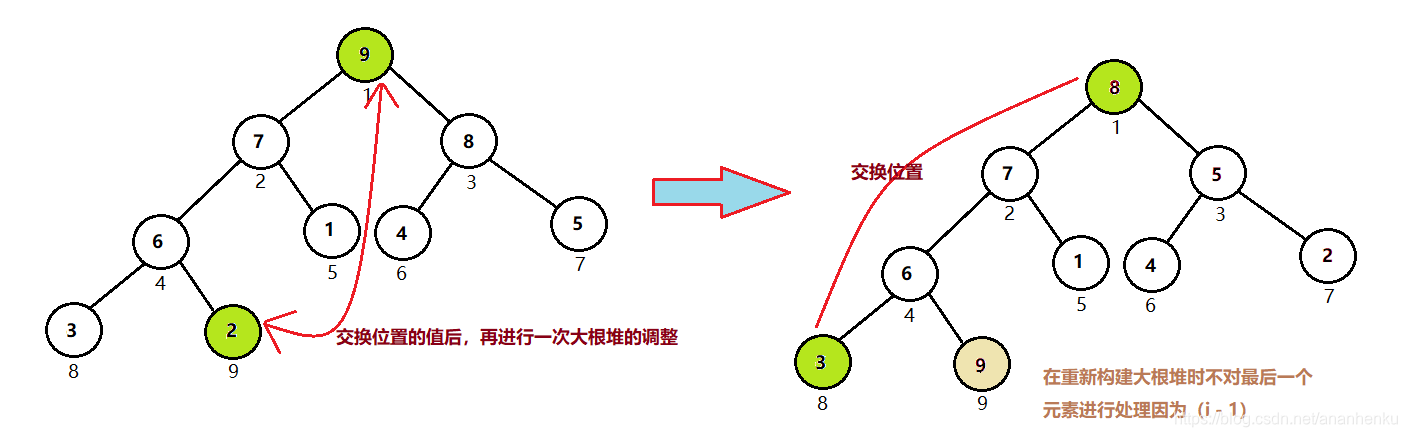
依次取出大根堆根结点元素的值,随后我们便能得到一个从小到大的序列。
在堆排列中最重要的部分便是堆大根堆(小根堆)的构建,不断通过每次构建大根堆时把根结点元素取出(因为此时的根结点是树中的最大值)
但是堆排序堆原有的序列排序状态并不敏感,以至于没有最好和最坏的时间复杂度,无论什么时间复杂度都为O (nlgn)。