DTP中用到Delta和Full这个咱都知道。但是由于咱基础知识不牢,所以有时候一遍并不能融汇贯通。
应用场景总是多变的,由于很多知识我没完全懂。所以事后要来修补:
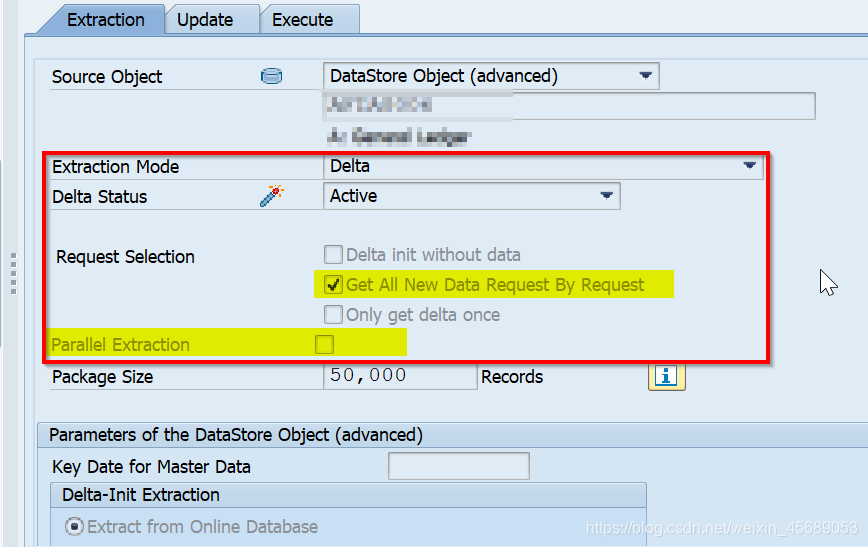
联动篇: Delta增量抽取模式.
至于用Full还是Delta的抽取模式,取决于数据是否要求增量。
对包的大小的设置需要和转换的逻辑复杂与否,以及数据源数量多少联系起来做分析。
如果你逻辑很复杂,那请用小一点的包啊,别用5万了。这一点要切记啊,不是只能从转换的逻辑代码那里做性能的优化啊。
如果你就没有查找逻辑,直接直连数据源,那你甚至可以把包大小调到5万以上。不过一般不做调整,因为也慢不到哪里去。
ADSO中用到的DTP
full
delta
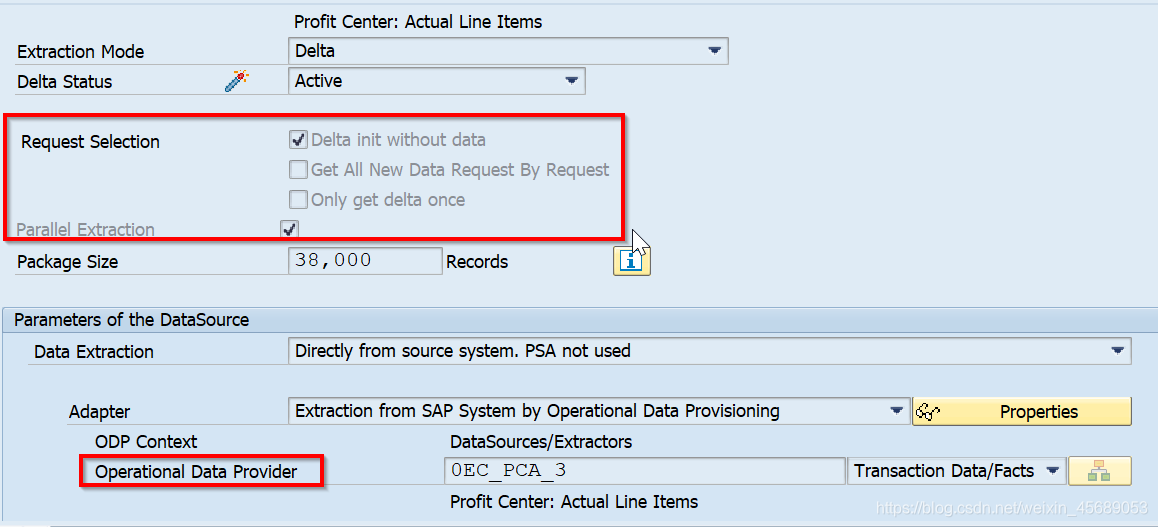
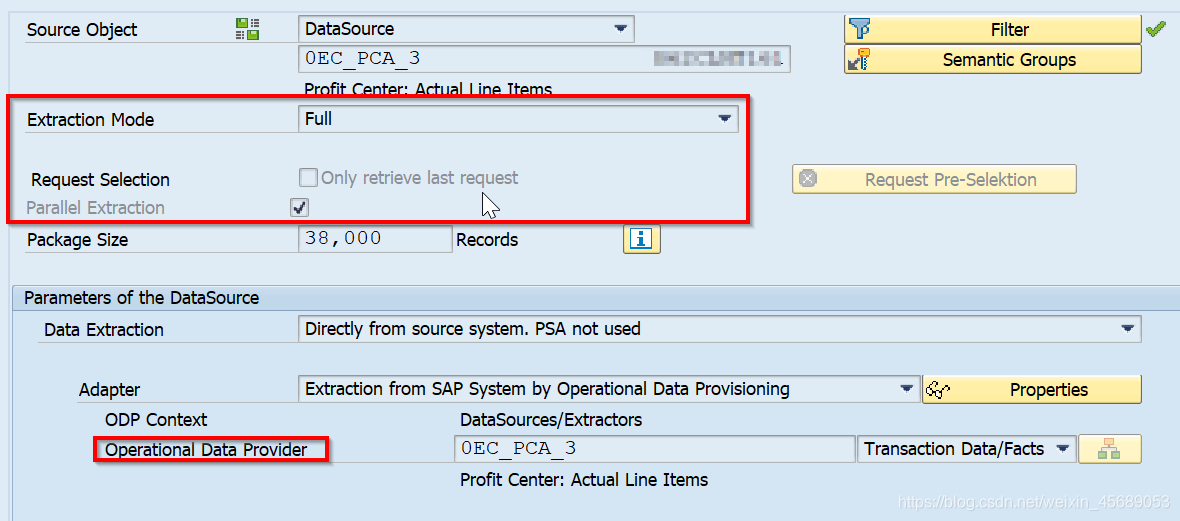
比较了Full和Delta的图,你就能看到不论是Full还是Delta下面都会有个request selection的复选框。不选当然可以。可是这个请求选择项都是什么意思呢?
还有下面那个Parallel Extraction又是什么意思呢?
对于最下方的Operational Data Provider我圈出来是意思现在都用这个弄了。。数据源就是这个,然后是从ODQ来抽的。这个点到为止。
回到Request Selection上面:对于Delta的三个,在联动的那篇已经写了。
对于Full的这个,把上次的重抽一遍?
最后一点Parallel Extraction,同步执行啥意思?
如果我不选同步执行呢?
今天正好有空,来看看这些到底咋回事。
Parallel Extraction相对于Serial Extraction。
并行抽取和执行,也就是有多个进程抽取数据的同时把数据更新到目标。因为它是一个请求一个请求的抽,执行一个DTP就有一个请求。我选了同步抽取就是多个进程抽取数据然后可以更新到target。那么串行的就是一个进程先抽完了,然后还是这个进程再更新到目标。然后下一个请求还是这个进程。所以一般都选择并行。
OpenHub中用到的DTP
full
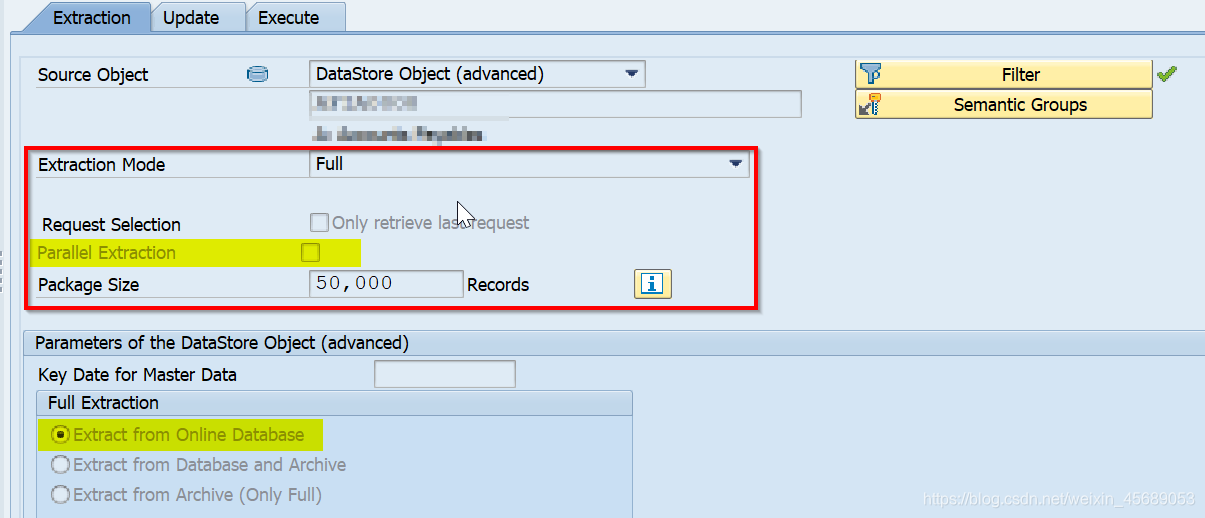
从这个地方能稍微理解了,全量抽取数据量小的情况下,不用并行也行。而如果数据量大,把包调小的同时,弄成并行抽取。但是如果你是弄Delta一般都是并行抽取啊,要不然性能很差,很慢的。这里是说抽数的性能。
delta
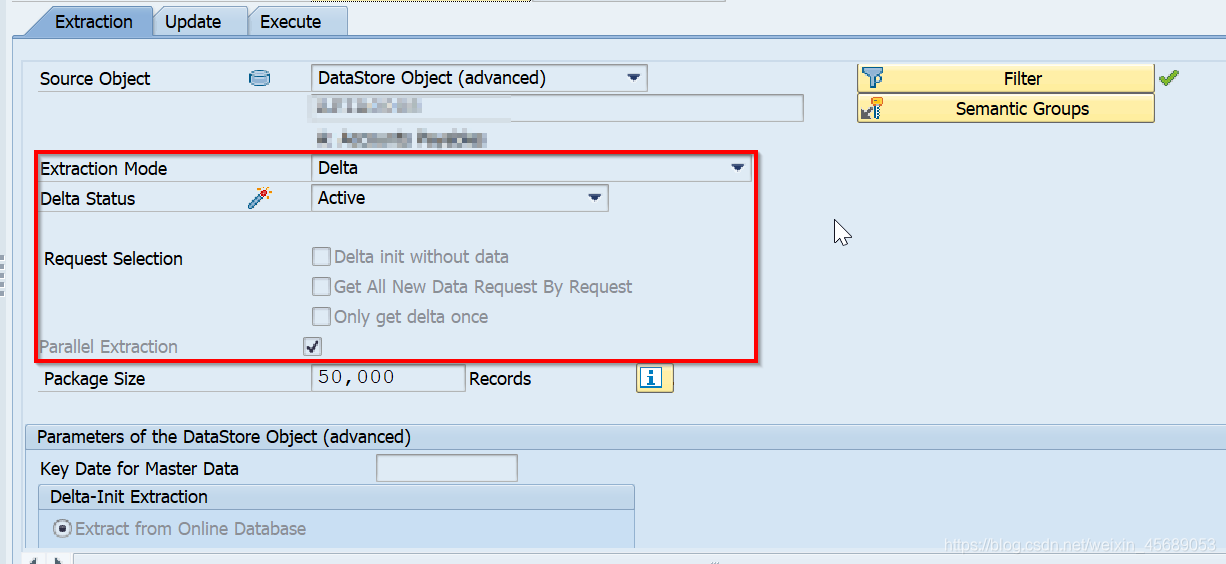
对比:
上面是两个简单的对比,都是openHub的Delta,一个是选了并行处理,另一个没有选并行处理,而且还从ADSO的Change Log表里一个接一个request来抽,那这个会出现什么情况呢?
首先你知道这个例子OpenHub是从ADSO来的,而且它是Delta的抽取模式,也就是它的数据是从ADSO的change log表来的。
Change Log表长啥样?
只有active表里面是语义主键,change log和inbound表里面都是有技术主键的。有请求号的。
从一个个的请求来,那么这个DTP就会一个个的从Change Log表的请求来执行,每一个请求都会有一个后台job,极限情况下你的SM37就会有很多个job啊,后台的进程太多,会导致CPU使用率飙升。那你的系统就没办法处理别的事情了。
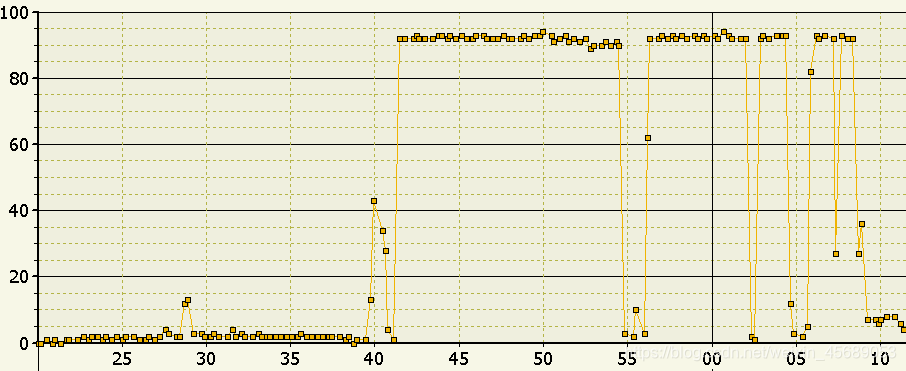
举例:
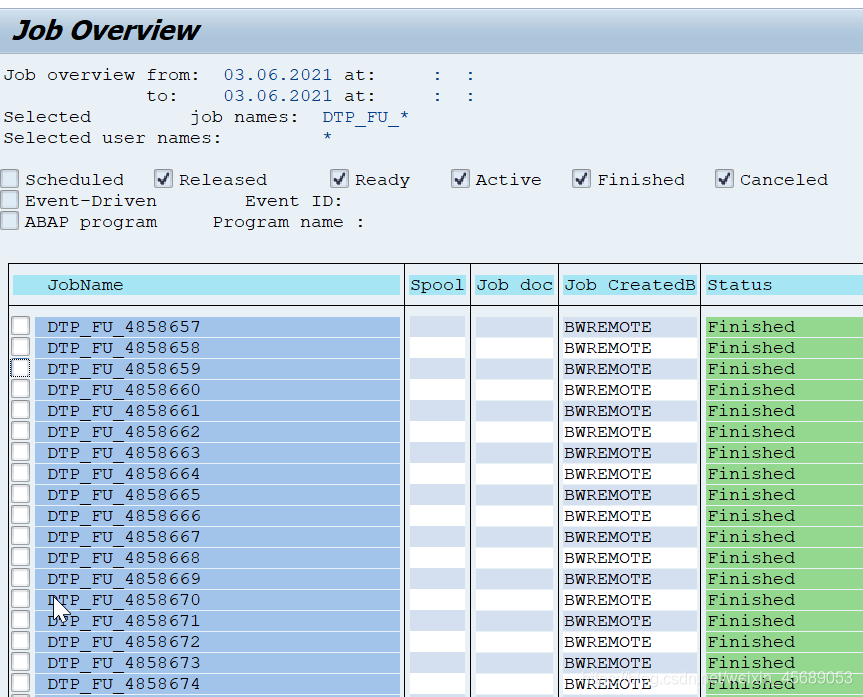
去看job log,查到DTP编号:去RSBKREQUEST去查DTP(中间的是ID,也可以用这个batch ID直接去查ID:到表RSBKQUESTRUN里直接查这个DTPR。。。不过这个是多此一举。
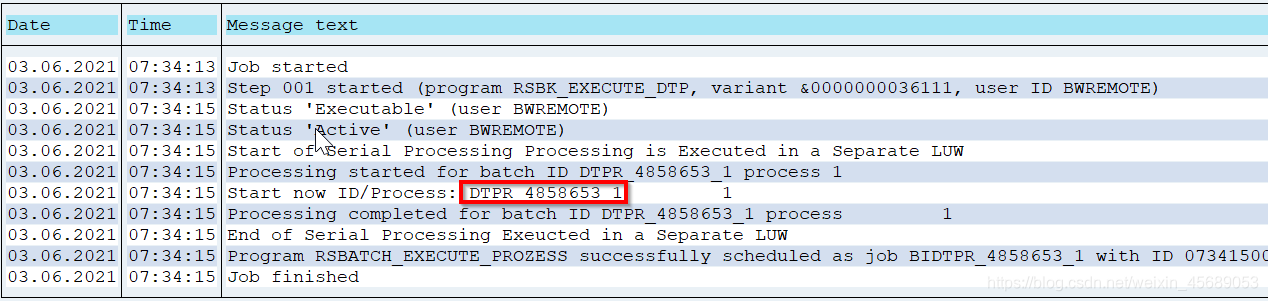

RSBKDTPT查看具体DTP描述。然后去看你的DTP是啥个抽数模式。
总结 :为了 DTP的性能,并行处理勾起来。