进入到BW4HANA之后,现在的版本应该都是BW4HANA2.0.
那么针对不同的ADSO,会有不同的表。
对于标准ADSO会固定有三个表:1 2 3
同时会有3个SQL 视图,分别是6 7 8
那这三个视图用来干嘛的?
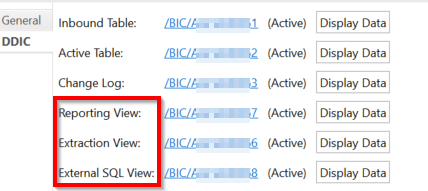
6 提取视图 当你去提取数据到别的target的时候,这是个后台操作。后台用的是这张表。
7 报表视图 就是包含了inbound表和active表的数据,你跑基于这个ADSO的report的时候,后台用的也是这张表。
8 外部SQL视图 这个是完全新的,用于给别人输数据,可以用在transformation里面或者AMDP里面。就是说优化了它这个接口啥的。就这么个意思。一般你外部要用的话,就别去用active表了,可以用8视图。(不是说openhub的那种外部使用,openhub是没办法选表的)这个表里面是没有分析授权的。如果你说你想要,那咋办呢?
用ADSO生成的外部view,这个里面会包含它的分析授权。

如果这个8视图你一开始没有,或者你在1.0版本的时候就激活了这个ADSO导致现在没办法搞8视图,那你用这个report:RSDG_ADSO_ACTIVATE.
文章目录
ADSO的类型
因为这会我们2.0了,1.0和2.0还是有些区别的,特别是ADSO的类型上。挺混乱的。
但是既然1.0过时了,就不讨论1.0了。
2.0的建模属性是这个样子的:

小圆圈的类型分的很清楚,下面的库存拉,计划啦,还有一个写接口,就是搞BO的数据往里面写的,你的SAC也可以往ADSO里面写。对于ADSO的类型呢,其实四个小圆圈就够了。那么下面的扩展特殊属性,是复选框,分别对应啥呢?

- 库存类型:对应标准ADSO和infocube类型ADSO
- 计划类型:对应标准ADSO,infocube类型ADSO,直接更新ADSO
- 写接口类型:对应标准ADSO和写优化ADSO
链接图:link.
1.data mart (infocube)
这个就是和原来的infocube一样。那么infocube是没有change log表的。只有个inbound表压缩后进入active表,报表可以从inbound表或者active表出来。然后往上层的话可以从active表进行full,或者inbound表进行full与delta。
一般用于报表分析。
inbound表: (未压缩的事实表)-F表
active表:(压缩的事实表)-E表
要想用cube类型,属性不能全是display的。
数据先进入inbound表,然后根据你的关键值的聚集方式来group压缩。然后inbound表被删除。changelog表是空的。所有的特性都是key。所以呢,关键值类型的不能被覆盖。只能是被聚集,累加啦,最大啦,最小啦。
这种ADSO在请求未激活时也可用于报表,就是从inbound表+active表出。
激活的时候,inbound表会被清空,request ID被删除,数据聚集到active表中。这个激活的操作就是压缩。此时报表从active表出。
报表数据
那么此时进入细节部分,如果所有的数据都是进入到inbound表,不去激活。报表也是可以出的,是union了inbound和active表。但是由于不同请求的数据技术主键不同,最后在报表里面是累加值。也就是累加的这个步骤到了报表层面执行了。
那么你说,既然我报表数据都能拿到,那还激活干啥呢?
1.激活是压缩了数据。省空间啊。毕竟HANA内存很贵的。
2.对于dataMart类型的内存ADSO,也是要激活累加的。
数据抽取
抽取数据的时候呢,往上的full/initialize是从active和inbound表结合出的。如果是delta,那是从inbound表出的,因为active表是没有request ID的,delta一定需要request ID。
这里的场景就是,如果你这个ADSO只有inbound表和active表,但是你又有上层的ADSO,那么上层的ADSO怎么做delta?
这个步骤就必须得是,你先抽数据到底层的ADSO,然后去做上层的delta,等上层的delta取了数了,再来激活这个inbound表里的请求。
这个东西呢,也就和6,7,8表对应上了。也就是说这些个view呢,就是后台给你生成的,用于后台的。你就别烦了。当你是个dataMart的ADSO,你往上给数据,让别人来extraction的时候。如果你就是个active表。那这个6提取视图就是active表的内容。如果你还有inbound表,那么你这个6extraction视图那就是inbound和active的union。
还有7那个也是一样的。实际上跑报表的时候人家后台给你迅猛生成view。但是这些view,说白了还是从最基础的1,2,3来的。就看你有啥。

那么其实这个infocube类型实际上好像没啥用。只在inventory ADSO用上。类比之前的用法,就是说多个标准ADSO需要在infocube上累计数值的时候用上。如果直接是上BW4HANA了。那我暂时没看到多少用这个类型的了。用标准的就够了。
而且你datamart类型ADSO支持的功能,我标准ADSO也都支持。SAP也可能以后不用这个ADSO了。
况且以前说为了性能考虑,有dimension ID的,不能超过13个的,现在是叫分组了,随便搞多少分组。也不用考虑笛卡尔积了。技术发展了。
2.standard
很久以前呢,标准ADSO必须有三张表,包括change log表。因为往上的delta需要这个表。但是现在如果你认定你的标准ADSO不需要change log,那你就只能往上搞full好处是省空间。但是吧,你也不知道你以后会不会有上层呢,所以一般都保留。
但是对于库存和计划类型的ADSO,changelog必须有。
标准ADSO可以基于infoobject或者直接基于field了,就是说简化步骤了。
(0927补充,field能代替的infoobject只能是那种不用到属性,层级,导航属性的特性,和那种不用到unit转换,currency转换,extra exception的关键值,所以说,一般来讲在底层可以直接field,但是上层最好还是用infoobject)
对比标准ADSO和Cube类型ADSO
一个差别就是标准ADSO里面基本上放细粒度的详细的数据,比如说到每天,每条凭证的每个行项目。默认是进行覆盖。
到Cube那大多是聚集类型,可以把天聚集到月,也就是我一个月的数据累加。
对于ADSO的更新呢,key值不能重复以外,其他非key值的特性,都会被delta的请求覆盖。那么对于其他数值类型的。你自己设的关键值的,就设个聚集类型了。默认也是覆盖move的,你改成sum或者Max啥的,还有个no update.

报表来源
这个层ADSO可出明细报表。不用像以前cube搞聚集了,聚集还是因为性能不够强。但是有了HANA,就不用那么斤斤计较了。
对于标准ADSO,不论你是有changelog,还是没有,还是支持写接口的。所有的数据都是从active表出的。不像是infocube是inbound和active的union。在标准ADSO这里,你没激活的inbound数据是看不到的。但是你跑报表下钻的好好的。如果下一秒有个新激活的请求数据进来了,那你报表里的数据会迅速改变的。这个跟infocube不一样。说好也好吧。
就是得处理链跑数记得在别人工作时间看报表之前。
infocube的话,你不去刷新报表,它新数据是进不来的。
数据抽取
对于数据往上抽取,那就很简单了。Full和initial都是从active表出,delta是从changelog出。这个你出一个然后去看请求就知道了。就是现在都在bwcockpit里面看,真是不好看。而且我们现在这个网速。动不动给你一个neterror。
一些解释
接下来,就看除了默认的这个写changelog的,还有下面两个属性。复选框加成。
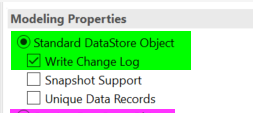
1. changelog
就是新增的,更改的,删除的。都在这里。用于增量提取。同时呢,这个changelog的请求数据没被删除的话,那还可以回滚到上次这个ADSO激活前的状态。
因为你想,先从inbound表激活,所有的请求会更新到changelog表里面。那么changelog表是有个更改前和更改后的状态的。更改后的状态是直接更新到ADSO的。如果回滚,那就把更改前的状态再改回去。这点很好玩的。
如果你要搞快照,库存和计划类型也得要changelog,如下图,不选changelog不行。
如果是唯一记录和写接口类型,就可以不要changelog。

2. 快照
是啥意思呢?数据源给你的数据集呢,只是full。
就是文本数据源拉,或者是主数据的更新。那我昨天有3个销售组织。今天只有2个了。如果我不选这个快照,那ADSO是不会帮我删除昨天的那个第三条的。反正激活了的都是它的。但是如果我选了这个快照,在changelog表里,我就会对比今天的inbound表和active表的数据,在changelog里被删掉的这条加个R,代表反转被删除了,然后删除这条不需要的。
或者我3个都做了更改,那我changelog表也有X和空的更新模式的。
(这里有个问题,如果是full来的,那它和直接更新ADSO有啥使用方式区别?)
这种快照针对于只支持全部full的,每回都是一个全部更新的,而且可能有删除的场景到是很好使。
**因为以前呢,你是要把这个full load的ADSO先drop一遍,然后再full load一回的。**这个也挺有意思的。
3. 唯一记录
就是说你点了这个,那主键组合的记录,不能有重复的。来了重复的,这条dataload就不会成功。就根本load不上去,还给你报个错。
3.staging (写优化)
这个是啥意思呢?
现在这个代替了写优化DSO了。写优化又是啥意思呢?

它下面有三个单选,1是只有个inbound表。2是压缩数据,就是说除了inbound表,还有个激活表。这个和cube一样。
还有3报表用的。
这个staging,我也不会解释,因为没人给我解释过。我也没怎么研究过。但是按照stage的解释是分阶段。一阶段的ADSO。
就是它是最底层的,用来把所有的源数据都拿过来的。为了防止你之后上层的数据出了问题了,好修复的。
但是同样啊,所有ADSO开始建的时候都会生成123表,不同的是根据建模属性,有些表是不用的。只是存在空壳子。
你选第一个inbound only的话,那就只有一个表的。
你选了第二个,就会有inbound和active表。
但是无论咋样,changelog表是不需要的。
这个最底层的ADSO呢,可以有filed或者是infoobject的。
只有inbound表
那么这个往上层是可以有delta或者full的。因为有请求号。
那么这个时候呢,其实基于请求号删数据也是可以的了。反正你也没有active表,你也不会激活它。跟PSA还是有点像的。
这个时候,你要晓得,他是不用于出报表的。你也不能给他加到出报表的provider里面去。(它有个reporting的)
然后,这个ADSO里,也不需要定义啥语义key的。有些active表要定义key的。因为active表里没有inbound表里的TSN,package ID和record ID这些技术主键。所以active表必须得去定义语义主键,没有这些主键,它不给你激活的。
compress data
这个就是inbound的下一层了,带激活的。那么咱知道激活了之后,inbound表数据就清空了。实际上这个是减少空间了。
因为你inbound表始终每个请求都有不同的主键,只要有record就会有新请求。那这个是很占空间的。万一你那边是更改的。我这里用inbound就会重复。很占地方。
当你激活了之后,active表只能full抽取了。(或者没激活,直接从inbound表去delta,然后再来激活)
当然你激活了之后,也没办法基于请求删除数据了,要么selective deletion,要么全删。
这个也是不适合用于reporting的。那它第三个选项呢?
reporting enabled
这个第三个选项,支持报表的。跟第二个有啥区别呢?
区别在于它激活了之后,inbound表数据不清除。往上层的所有数据不论是full还是delta提取都是从inbound表出去的。
但是report是从active表出的。这个就是有点占空间了。
但是好处是你active表清空后还可以从inbound表再给回去。
所以这会呢,compress压缩就是说active之后清空inbound表。基于请求号删除在这里就行不通了。
reporting就是说active之后保留inbound表。我觉得此时还是可以基于请求号删除的。但是我没试过。
只要你从inbound表激活,在active表里,都是没有请求号的。
那你激活的时候,最终到active表里的数据实际上是依据你的关键值那里的聚集方式去生成记录的。
提取区别
对于第一个inbound表和第三个不清除inbound表,那么full都是从inbound表出的。
只有第二个是从active表出的。毕竟也只有这个一个表。(在还有没激活的inbound的情况下,是从inbound+active出)
对于所有的delta,一律只能从inbound表出。
所以对于第二种压缩情况,如果上层一定要delta,那就在这个inbound没有被激活的时候去搞delta。然后回来再激活。
报表区别
这个呢,就只有第三个选项可以出报表。而且这个第三个选项非常占地方的啊,只有从active表出才可以。也只有这个第三个选项才能被加到provider里面。就是说可能哦,某些用户就是想看看底层数据对不对呢。我得确认底层数据对了,才能再往上层开发。
就这种功能呢,虽然很费,但是你得有。以防万一吧。
不过如果你觉得你啥都没问题非常自信。那就不需要这么搞了。直接标准ADSO吧。
实际使用场景大多只有第一种,只从inbound表出去数据。而且这个staging ADSO是基于字段的。这样就够了。
对于第三种呢,占那么多空间的,也不删inbound表的。随便你怎么搞都行。功能的强大是基于空间的占用。而且这种的你随便怎么搞delta、full都行。也不用说我等没激活的时候去搞delta。反正它都不删。就是说上层的delta来抽它,好嘛,一看,哦,你这些request我没有抽过诶,那我赶紧来都给抽走。
但是你这里也不好删inbound表的数据的,因为啥呢,因为你的request一旦删了,你让active表情何以堪。你得先删active表,然后再来删inbound。
4.direct update
这个呢,就是不用更新啥的。只有一个active表。很简单。
你可以在这个上面直接出报表。数据抽取的话就直接从这个上面full。
可以用于planning, 要在AFO中锁住特定发布区间的。这个planning的需要搞class 和 method。
当然planning是1,3,4都可以。

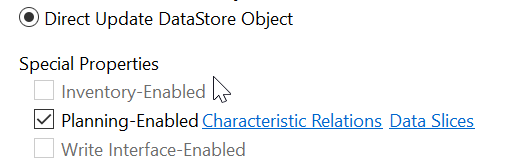
那么这些包括staging啊,直接更新啊的。都是可以用field的。用field和infoobject呢,就是简单一些,不用建infoobject,也更灵活一些。但是infoobject的一些文本啊,属性啊,层级啊的是它的强项。当然还有个授权,哈哈,差点忘了。
一般底层直接过来可以用field,那么往上层,用到比较重要的主数据的时候,就是infoobject,不能说你用客户这个主数据还用fields。
写接口
说实话这个我没用过。第三方要通过某些服务,把数据写进来。那就只有SAP它自己提供的一些服务了,你可以选用。
5.库存ADSO(库存infocube)
待续:2021/09/27