并行查询
并行查询相关配置参数
并行查询的几个重要参数
- max_worker_processes(integer)
设置系统支持的最大后台进程数,默认值为8,如果有备库,备库上此参数必须大于或于主库上的此参数配置值,此参数调整后需重启数据库生效。
- max_parallel_workers (integer)
设置系统支持的并行查询进程数,默认值为8,此参数受max_worker_processes 参数 制,设置此参数的值比max_worker_ processes值高将无效。
当调整这个参数时建议同时调整max_parall_workers_ per_ gather 参数值。
- max_parallel_workers_per_gather (integer)
设置允许启用的并行进程的进程数,默认值为2,设置成0表示禁用并行查询,此参数 max worker processes参数和max_ parallel_ workers参数限制,因此并行查询的实际进程数可能比预期的少,并行查询比非并行查询消耗更多的CPU、IO、内存资源,对生产系统有一定影响,使用时需虑这方面的因素,这三个参数的配置值大小关系通常如下所示:
max_worker_processes > max_parallel_workers >max_parallel_workers_per_gather
- parallel_setup_colat(floating point)
设置优化器启动并行进程的成本,默认为1000
- parallel_tuple_cost(floating point)
设置优化器通过并行进程处理行数据的成本,默认为0.1
- min_prallel_table_scan_size(integer)
设置开启并行的条件之一 ,表占用空间小于此值将不会开启并行,并行顺序扫描场景下扫描的数据大小通常等于表大小,默认值为8MB。
- min_parall_index_scan_size(integer)
设置开启并行的条件之一,实际上并行索引扫描不会扫描索引所有数据块,,默认值为512kb。
- force_parallel_mode (enum)
强制开启并行,一般作为测试目的,OLTP生产环境开启需慎重,一般不建议开启。
max_worker_processes = 16
max_parallel_workers_per_gather = 4 #taken from max_parallel_workers
max parallel workers = 8
parallel_tuple_cost = 0.1
Parallel_setup_cost =1000.0
min_parallel_table_scan = 8MB
min_parallel_index_scan_size = 512kB
force_parallel_mode = off
查看当前数据库参数配置情况
select name,setting
from pg_settings ps
where 1=1
and ps.name in (
'force_parallel_mode',
'max_worker_processes',
'max_parallel_workers',
'max_parallel_maintenance_workers',
'max_parallel_workers_per_gather',
--'min_parallel_relation_size',-- add 9.6,remove from 10
'min_parallel_index_scan_size',
'min_parallel_table_scan_size',
'parallel_tuple_cost',
'parallel_setup_cost',
'parallel_leader_participation'
);
psql -h 192.168.1.253 -p 5432 test postgres
并行扫描
并行顺序扫描
介绍并行顺序扫描之前先介绍顺序扫描(sequential scan),顺序扫描通常也称之为全表 扫描,全表扫描会扫描整张表数据,当表很大时, 全表扫描会占用大量CPU、内存、I0资源,对数据库性能有较大影响,在OLTP事务型数据库系统中应当尽量避免。
创建数据库
CREATE DATABASE test ENCODING = 'UTF8';
首先创建一张测试表, 并插人5000万数据,如下所示:
CREATE TABLE test_big1(
id int4,
name character varying(32),
create_time timestamp without time zone default clock_timestamp()
);
INSERT INTO test_big1(id, name)SELECT n, n||'_test' FROM generate_series(1,50000000) n;
EXPLAIN SELECT * FROM test_bigl WHERE name='1_test';
以上执行计划Seq Scan on test _big1 说明表test bigl 上进行了顺序扫描,这是一个典 型的顺序扫描执行计划,PostgreSQL 中的顺序扫描在9.6版本开始支持并行处理,并行顺 序扫描会产生多个子进程,并利用多个逻辑CPU并行全表扫描,- - 个并行顺序扫描的执行计划如下所示:
# 一个并行顺序扫描的执行计划如下所示
EXPLAIN ANALYZE SELECT * FROM test_big1 WHERE name='1_test';
并行索引扫描
介绍并行索引扫描之前,先简单介绍下索引扫描( index scan),在表上创建索引后,进行索引扫描的执行计划如下所示:
EXPLAIN ANALYZE SELECT * FROM test_big1 WHERE id=1;
Index SCean using表示执行计划预计进行索引扫描,索引扫描也支持并行,称为并行索引扫描(rallel index scan),本节演示并行索引扫描,首先在表test_big1上创建索引,如 下所示:
CREATE INDEX idx_test_big1_id ON test_big1 USING btree (id);
统计ID小于1千万的记录数,如下所示:
EXPLAIN ANALYZE SELECT count(name) FROM test_big1 WHERE id<10000000;
PostgreSQL10 对并行扫描的支持将提升范围扫描SQL的性能,由于开启并行将消耗更多的CPU、内存、IO资源,设置并行进程数时得合理考虑,另一方面,目前 PostgreSQL 10暂不支持非btree索引类型的并行索引扫描。
并行index only扫描
index-only扫描是指只需扫描索引,也就是说SQL仅根据索引就能获得所需检索的数据,而不需要通过索引回表查询数据。例如,使用SQL统计ID小于100万的记录数。
会话级别关闭并行
SET max_parallel_workers_per_gather = 0;
不开启并行,执行计划如下:
EXPLAIN ANALYZE SELECT count(*) FROM test_big1 WHERE id<1000000;
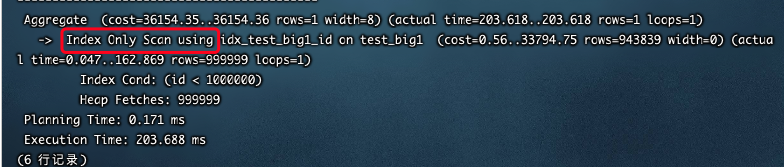
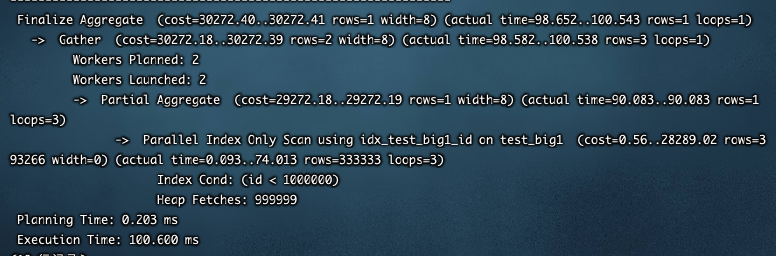
index-only 扫描支持并行
会话级别开启并行
SET max_parallel_workers_per_gather TO default;
执行计划如下:
EXPLAIN ANALYZE SELECT count(*) FROM test_big1 WHERE id<1000000;
并行bitmap heap扫描
介绍并行bitmap heap扫描之前先了解下Bitmap Index扫描和Bitmap Heap扫描,当SQL 的where条件中出现or时很有可能出现Bitmap Index扫描,如下所示:
EXPLAIN SELECT * FROM test_big1 WHERE id=1 OR id=2;
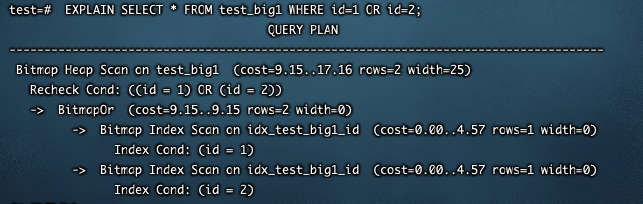
从以上执行计划看出,首先执行两次Bimap Index扫描获取索引项,之后将Bitmap Index扫描获取的结果合起来回表查询,这时在表test bigl上进行了Bitmap Heap扫描。 Bitmap Heap扫描也支持并行,执行以下SQL,在查询条件中将ID的选择范围扩大。
EXPLAIN ANALYZE SELECT count(*) FROM test_big1 WHERE id <1000000 OR id > 49000000;
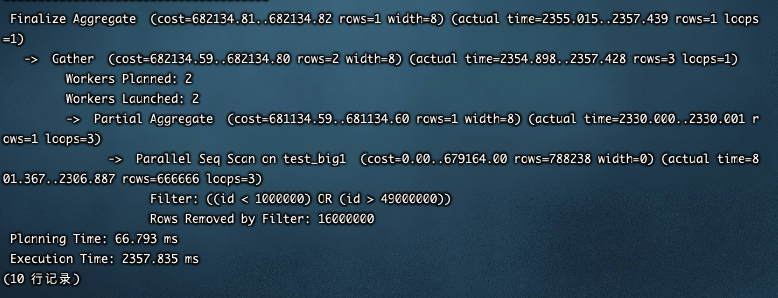
会话级别关闭并行
SET max_parallel_workers_per_gather = 0;
不开启并行,执行计划如下:
EXPLAIN ANALYZE SELECT count(*) FROM test_big1 WHERE id <1000000 OR id > 49000000;