驱动案例
本案例是将“京东”网某本字典的书评信息,根据词出现的次数不同,生成词云,词云图中字体的大小表示词出现的频率多少。
任务目标
1.获取书评(从文件中读取书评,删除符号,计算书评条数)
2.过滤书评(删除无效书评)
3.统计词频(统计词及出现的次数)
4. 生成词云(将词频统计结果可视化)
Python文件操作
前面我们已经学过了python文件的基本操作,这里我们使用open方法打开txt文件,读取txt文件的书评后进行其他操作。
fp=open('bookComments.txt', 'r')
bookComments=fp.read()
fp.close()
正则匹配
正则匹配是指用某种预定义的模式去匹配一类具有共同特征的字符串,主要用于字符串的处理,可快速查找和替换符合匹配模式的字符。
例如有一个正则匹配字符串:
[。.,,;;、!!??&* ()( )《》]+
该正则匹配字符串包括:1个或多个中英文标点符号、&、*、空格、中英文小括号、书名号等信息。
import re #导入re库,它提供了正则匹配操作所需的功能
r='[。,,!.?&!;?*;、 ()( )《》]+' #接着将正则匹配字符串赋值给匹配模式r
Comments_data = re.sub(r,‘’,bookComments) #sub方法中 第1个参数为:匹配模式; 第2个参数为:用来替换的字符串; 第3个参数为待替换的变量。
最后调用re模块的sub方法,若书评bookComments中出现匹配模式r中的各种字符,则用空来替换,从而实现了删除书评中的标点等特殊符号的功能。删除书评后的书评信息存放到Comments_data中。
列表
案例3里面已经介绍了什么是列表及列表的特点:
(1)列表中的元素是有序的,意味着每一个元素都有
一个位置;
(2)列表可以容纳Python中的任何对象;
(3)列表元素都可变。
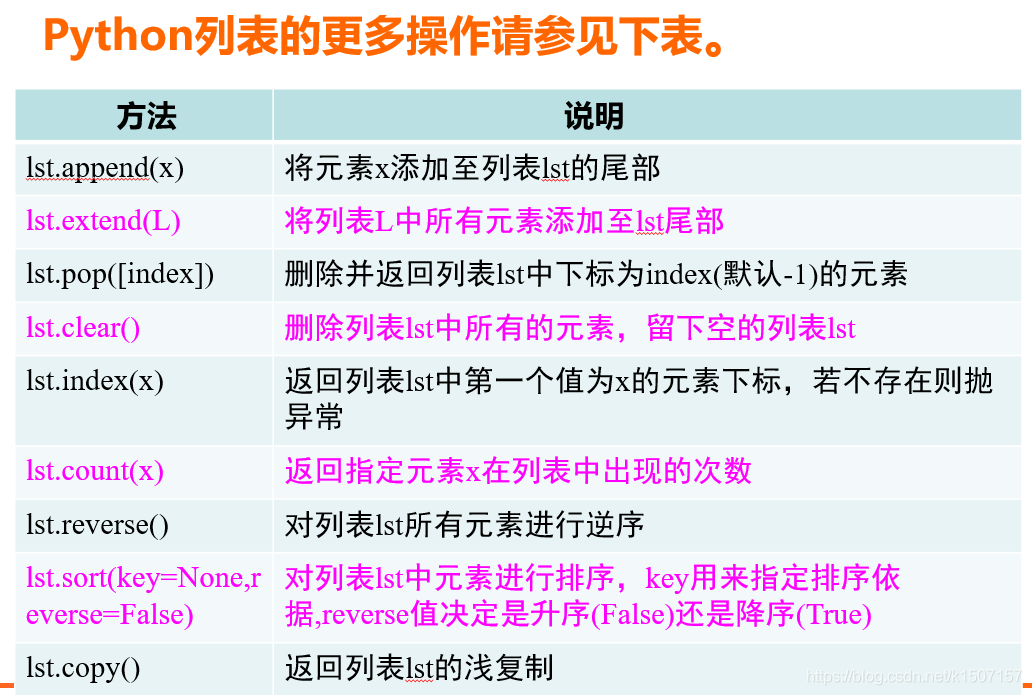
在这里将进一步介绍列表的增、删、改等操作。
增加列表元素
fruit=['apple','banana'] #定义一个fruit列表,包含有apple和banana两个元素。apple的序号为0,banana的序号为1。
fruit.insert(1,'orange') #调用fruit的insert方法,在1号位置插入orange元素
运行结果:

从输出来看,插入的元素就在指定位置,若指定的位置不存在则为越界,那么这时新插入的元素就在列表最后。
删除列表元素
fruit=['apple','banana'] #定义列表
fruit.remove('banana') #调用remove方法删除banana元素
fruit=['apple','banana'] #定义列表
del fruit[0] #调用del关键词删除指定位置元素
修改列表元素
fruit=['apple','orange']
fruit[0]='grape' #修改0号位置的元素,即将apple改为grape。
求列表长度
fruit=['apple','banana’]
len(fruit) #调用len求列表长度
元组
根据列表的特点,其元素可变,因此使用列表存放书评可能会被意外修改,这是要避免的。若能将列表变为元组,就安全了。那如何将列表转变为元组呢?
元组即tuple,即用()括起所有元素,元素间用逗号分隔。
例如:fruit=(‘apple’,‘banana’,‘orange’)
元组与列表非常相似,唯一的区别是它的元素不可修改。
CommentsTuple=tuple(Comments) #将列表Comments转为元组CommentsTuple
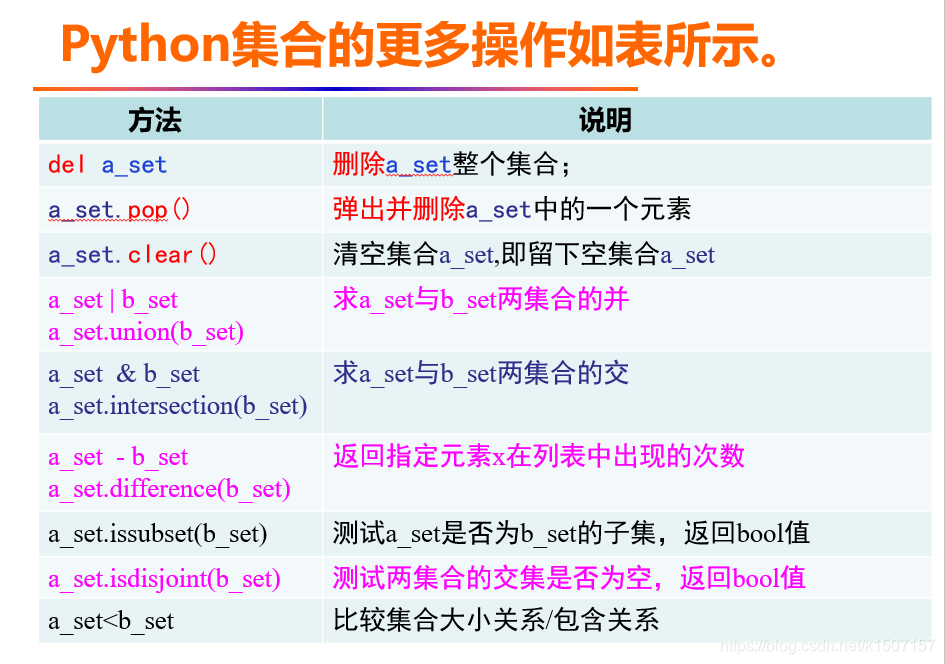
集合
Python中的集合(set)类型同数学上的集合概念一致, 即包含0或多个不重复数据项的无序集合。
fruit={
'apple', 'banana', 'orange'}
集合与列表很相似,元素都可变,表达上将[]替换为{},但集合没有索引即无序,且不允许出现重复元素。
根据集合的特点,集合不能像列表那样索引,除了做集合
运算外,集合元素可以被增加或删除。
增加集合元素
a_set = {
'apple', 'banana'}
a_set.add('orange') #使用add方法,向集合a_set中添加一个元素orange
print(a_set)

输出元素随机,说明集合是无序的!
删除集合元素
a_set = {
'apple', 'banana'}
a_set.discard('apple') #使用discard方法删除一个元素,也可使用remove方法
print(a_set)
集合因为没有位置索引,所以不能按位置删除。
求集合长度
a_set=set([1,1,1,2,3,3,3,3])print(a_set)
#另外:set()函数用于集合的生成,返回一个无重复且无序的集合。
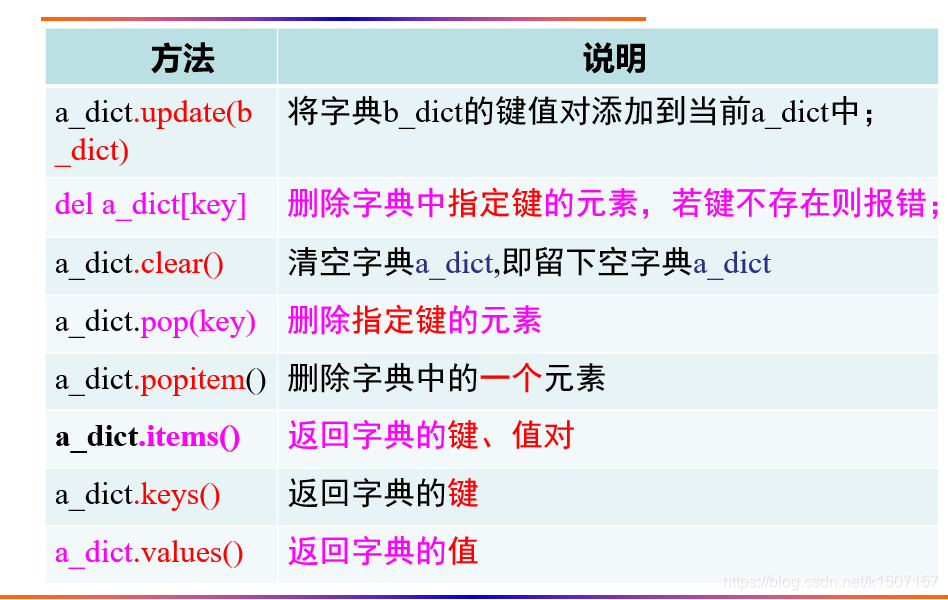
字典
Python中的字典来源于生活中的字典,是以键-值对形成构成的集合。
例如:fruit={‘apple’:10,‘banana’:20,‘orange’:30}
字典的主要特点:
(1)它具有集合的无序特性,还具有集合的元素不重复的特点,即键具有唯一性。
(2)它而键不可修改,但值可修改。字典的键值对一定是成对出现,且键值不可变且唯一。
#安装库函数
1.系统命令安装
(1)打开cmd命令行窗口。
(2) 假设Python的安装路径为D:\Python。在命令行先键入 D:,再执行 cd Python\Scripts,则在命令行进入到D:\Python\Scripts
(3)在当前的命令行窗口,执行 pip install jieba,安装jieba库。
(4)另一种方法是在当前命令行窗口指定可用的镜像资源安装。
pip install jieba -i https://pypi.douban.com/simple/
成功提示截图:

词云图
词云图即将词及其出现的次数(左图),按照出现的次数多的词相应地显示较大(下图):

第1步:检查或安装必要的库
第2步:确定词云形状,准备词云图形状的参考图片
第3步:确定词云图样式,从而创建词云对象
wc = wordcloud.WordCloud(#根据所设置词云属性创建词云对象
font_path='C:/Windows/Fonts/simhei.ttf', # 设置字体类型
width=500, height=400,# 词云尺寸
mask=mask, # mask =np.array(Image.open('beijing.png'))
#设置参考图为背景
max_words=200, # 最多显示词数
max_font_size=100, # 字体最大值
background_color='white', #设置背景颜色为白色
font_step=3,#以3为步长,设置不同的字体大小
random_state=False,# 词云图形状不随机变化
prefer_horizontal=0.9)# 90%的词显示在水平方向
第4步:根据已经统计的词及其词频生成词云
wc.generate_from_frequencies(d)
第5步:渲染词云
(1)调用词云库中的ImageColorGenerator方法从背景图建
立颜色方案;
image_colors = wordcloud.ImageColorGenerator(mask)
(2)调用词云对象的recolor方法将词云颜色设置为背景图方
案。
wc.recolor(color_func=image_colors)
第6步:显示词云图像
import matplotlib.pyplot as plt
(1) 显示词云;
plt.imshow(wc)
(2) 关闭坐标轴;(若不关闭会显示x-y轴及其标签)
plt.axis(‘off’)
(3) 显示图像。
plt.show()
案例代码
import re
import jieba
import collections
import numpy as np
import wordcloud
from PIL import Image
import matplotlib.pyplot as plt
import collections #导入collection库
import jieba
with open('bookCommentsNew2.txt', 'r') as fp:
bookComments=fp.read()
Comments_list_exact = jieba.cut(bookComments,cut_all =False) # 精确模式分词
d=dict()
for key in Comments_list_exact:
d[key] = d.get(key, 0) + 1
print(d)
#词频展示
mask = np.array(Image.open('beijing.png')) # 定义词频背景
wc = wordcloud.WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf', # 设置字体格式
#width=500, height=400,
mask=mask, # 设置背景图
max_words=200, # 最多显示词数
max_font_size=100, # 字体最大值
background_color='white',
font_step=3,
random_state=True,
prefer_horizontal=0.9)
wc.generate_from_frequencies(d) # 从字典生成词云
image_colors = wordcloud.ImageColorGenerator(mask) # 从背景图建立颜色方案
wc.recolor(color_func=image_colors) # 将词云颜色设置为背景图方案
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
总结
本章主要补充介绍了文件的读取与写入、re库、列表的基本操作、元组、集合、过滤函数filter、lamda表达式、字典、模块的定义、模块的导入方式、常见的标准模块、自定义模块、模块的导入特性、包以及下载与安装第三方模块、jieba库、wordcloud库、pillow库、matplotlib库等