1.引入
在SQL的查询中,我们经常会使用到关键字:order by,那么我们在使用order by的时候会出现使用文件类排序的情况,那么这一个时候的SQL性能其实是不好的。那么下面呢,我们就一起来说说如何实现sql的关键字order by的优化问题。其实就是说一个问题,如何把order by查询结果由:using filesort优化到using index。
2.创建测试内容准备
(1).创建测试使用数据库表:book
DROP TABLE IF EXISTS `book`;
CREATE TABLE `book` (
`book_id` int(11) NOT NULL AUTO_INCREMENT,
`book_name` varchar(50) NOT NULL,
`book_author` varchar(50) NOT NULL,
`book_price` decimal(10,0) DEFAULT NULL,
`book_pct` varchar(50) DEFAULT NULL,
`book_pub` varchar(50) DEFAULT NULL,
`book_num` int(10) NOT NULL,
`book_intro` varchar(255) DEFAULT NULL,
`book_record` varchar(50) DEFAULT NULL,
`bookstore_id` int(11) NOT NULL,
PRIMARY KEY (`book_id`)
) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8;(2).插入数据并查询

(3).创建索引,在book_name,book_price上创建索引
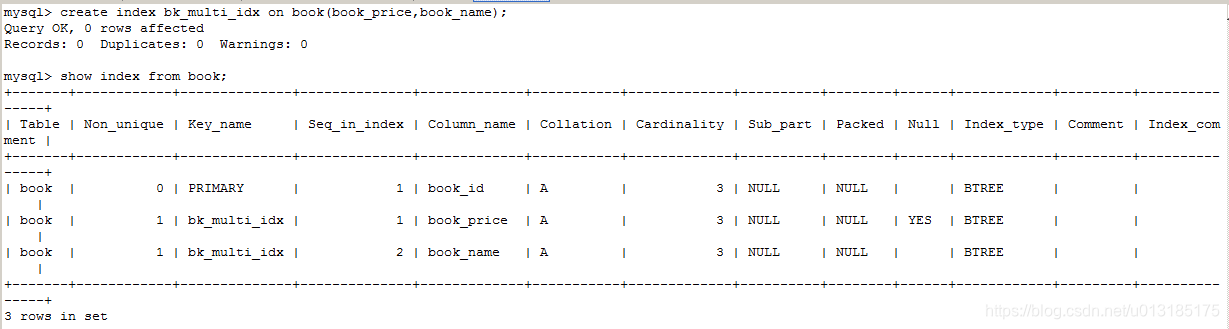
3..查询分析测试
(1).按照book_price排序查询,直接查询排序

(2).按照book_price排序查询,并设置where条件

(3).按照book_name进行排序,并设置where条件

(4).按照book_name.book_price进行排序。

(5).特殊情况的排序,直接按照创建的的索引进行数据的排序操作。
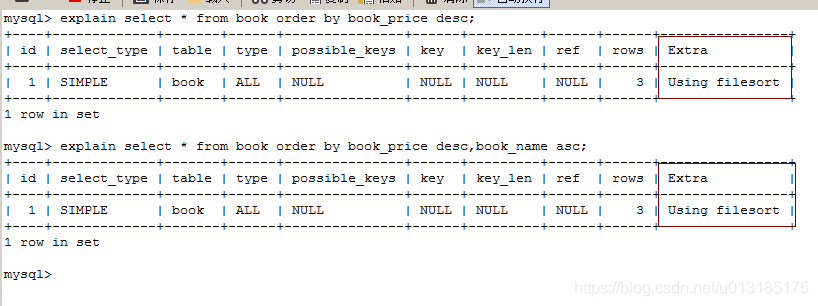
总结:
MySQL数据库对于查询数据的时候的排序,一般情况会使用俩种,一种是index,另一种是filesort.其中index的效率高,它是指
MySQL数据库扫描索引本身完成的排序;filesort效率比较低,它是指对文件进行排序。那么也就是说我们在写查询排序SQL的时候
需要的就是让它使用index的方式,那么order by在什么样子的情况下会使用index呢?一般的情况如下俩种就会使用到index:
1.order by语句使用索引的最左前列。
2.使用where 子句和 order by 子句条件组合满足索引最左前列。
使用index排序是使用了我们所创建的索引本身来进行排序,那么为什么使用filesort就会比index慢呢?其实MySQL数据库在使用filesort的时候它就要启动双路排序和单路排序。
双路排序:扫描俩次磁盘,然后读取到数据。从获取的数据中进行buffer排序,然后再去读取其他的字段。
单路排序:对磁盘进行一次扫描,然后读取数据。这一种的效率会更高一下,但是由于它一次读取就需要把数据操作完成,所以它更加的耗费资源。但是效率更快。
但是在使用单路的时候就会有一个问题,那就是如果计算机的配置信息等足够,那么MySQL数据库在进行操作的时候不能够一次性使用单路排序。那么这样的单路排序就会进行多次。这样的效率还不如双路排序的效率。那么这一个时候怎么解决呢?一般情况我们调整我们MySQL的配置文件信息就可以了:
把配置文件中的sort_buffer_size和max_length_for_sort_data的参数值大小调大。
3.总结:如何提升order by的查询速度
