要知道两种sql的区别,先要知道什么是hive,什么是spark
一、什么是hive,什么是spark
(一)hive
1、hive在hadoop中承担了多种角色,每种角色承担特定的功能。
| 定语 | 角色 | 作用 | 优点 |
|---|---|---|---|
| 基于Hadoop的数仓工具 | 查询引擎 | 可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转化为MapReduce任务进行运行 | 学习成本低,可以通过类sql语句执行统计,不必开发专门的MapReduce应用 |
| 建立于Hadoop上的数据仓库基础架构 | 数据仓库 | 它提供了一系列工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制,它定义了类SQL语言HQL,允许熟悉SQL的用户查询数据 | 简化了查询分析工作 |
| – | – | – | – |
2、hive和关系型数据库的区别
| hive | 关系型数据库 | |
|---|---|---|
| 存储系统 | HDFS | 服务器本地的文件系统 |
| 计算模型 | mapreduce | 关系型数据库自己设计的计算模型 |
| 设计初衷 | 海量数据做数据挖掘 | 实时查询 |
| 实时性 | 实时性差 | 就是为实时查询而生的 |
| 扩展性 | 和hadoop一样,计算能力和存储能力扩展方便 | 相对差很多 |
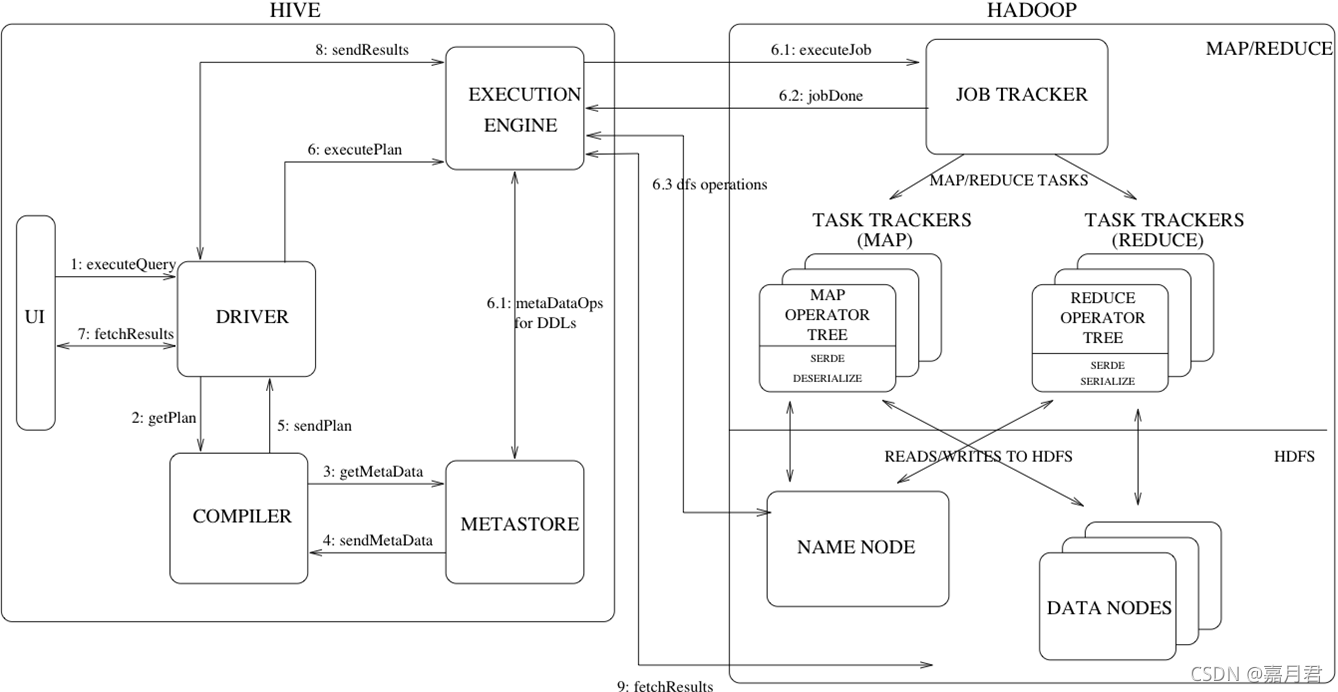
3、hive架构及执行流程介绍
hive架构图
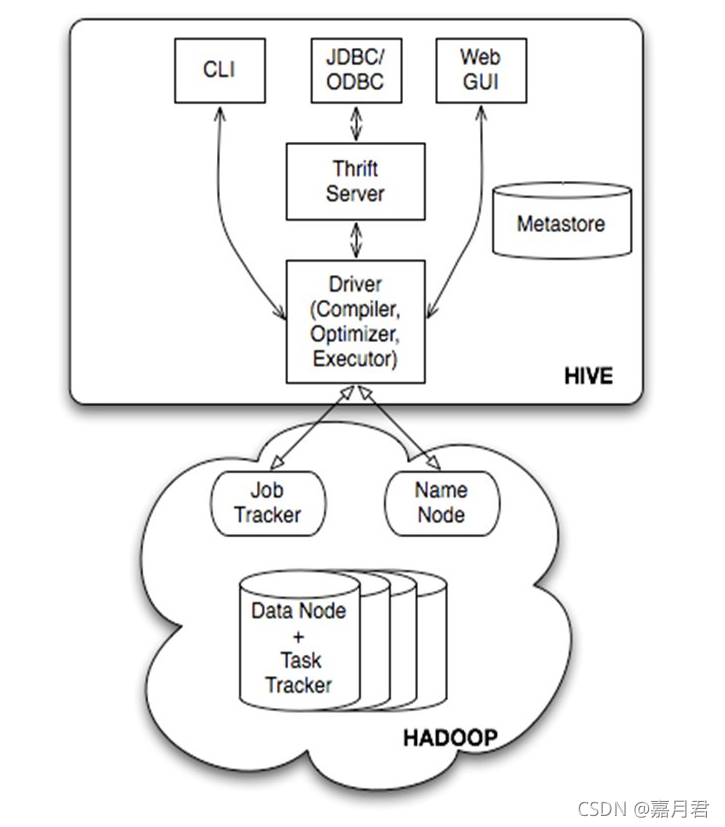
hive基于大数据底座hadoop
| 类型 | 组件 | 作用 | 备注 |
|---|---|---|---|
| 客户端 | CLI | 终端命令执行接口 | |
| 客户端 | Thrift客户端 | 包含JDBC/ODBC在内的诸多连接方式均建立在thrift客户端之上 | |
| 客户端 | WEB GUI | 提供了一种通过网页的方式访问hive的途径,接口对应hwi(hive web interface),需要提前启动hwi服务 | |
| 服务端 | Driver | 组件包含Complier、Optimizer、Executor,负责将hql进行编译,优化生成执行计划,而后调用mapreduce进行计算执行 | |
| 服务端 | MetaStore | 元数据服务组件,负责存储hive的元数据,因为元数据的重要性,hive支持把metastore服务独立出来,安装到远程的服务器集群中,从而解耦hive和metastore,保证hive运行的健壮性 | |
| 服务端 | Thrift | facebook开发的软件框架,用来进行可扩展且跨语言的服务开发,hive集成了该服务,能让不同的开发语言调用hive接口 |
hive执行流程图